Mergesort
Mergesort (von englisch merge ‚verschmelzen‘ und sort ‚sortieren‘) ist ein stabiler Sortieralgorithmus, der nach dem Prinzip teile und herrsche (divide and conquer) arbeitet. Er wurde erstmals 1945 durch John von Neumann vorgestellt.[1]

Funktionsweise
Mergesort betrachtet die zu sortierenden Daten als Liste und zerlegt sie in kleinere Listen, die jede für sich sortiert werden. Die kleinen sortierten Listen werden dann im Reißverschlussverfahren zu größeren sortierten Listen zusammengefügt (engl. (to) merge), bis eine sortierte Gesamtliste erreicht ist. Das Verfahren arbeitet bei Arrays in der Regel nicht in-place, es sind dafür aber (trickreiche) Implementierungen bekannt, in welchen die Teil-Arrays üblicherweise rekursiv zusammengeführt werden.[2] Verkettete Listen sind besonders geeignet zur Implementierung von Mergesort, dabei ergibt sich die in-place-Sortierung fast von selbst.
Veranschaulichung der Funktionsweise
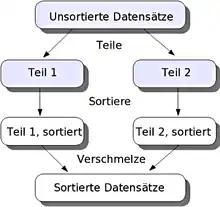
Das Bild veranschaulicht die drei wesentlichen Schritte eines Teile-und-herrsche-Verfahrens, wie sie im Rahmen von Mergesort umgesetzt werden. Der Teile-Schritt ist ersichtlich trivial (die Daten werden einfach in zwei Hälften aufgeteilt). Die wesentliche Arbeit wird beim Verschmelzen (merge) geleistet – daher rührt auch der Name des Algorithmus. Bei Quicksort ist hingegen der Teile-Schritt aufwendig und der Merge-Schritt einfacher (nämlich eine Konkatenierung).
Bei der Betrachtung des in der Grafik dargestellten Verfahrens sollte man sich allerdings bewusst machen, dass es sich hier nur um eine von mehreren Rekursionsebenen handelt. So könnte etwa die Sortierfunktion, welche die beiden Teile 1 und 2 sortieren soll, zu dem Ergebnis kommen, dass diese Teile immer noch zu groß für die Sortierung sind. Beide Teile würden dann wiederum aufgeteilt und der Sortierfunktion rekursiv übergeben, so dass eine weitere Rekursionsebene geöffnet wird, welche dieselben Schritte abarbeitet. Im Extremfall (der bei Mergesort sogar der Regelfall ist) wird das Aufteilen so weit fortgesetzt, bis die beiden Teile nur noch aus einzelnen Datenelementen bestehen und damit automatisch sortiert sind.
Implementierung
Der folgende Pseudocode illustriert die Arbeitsweise des Algorithmus, wobei liste die zu sortierenden Elemente enthält.
funktion mergesort(liste);
falls (Größe von liste <= 1) dann antworte liste
sonst
halbiere die liste in linkeListe, rechteListe
linkeListe = mergesort(linkeListe)
rechteListe = mergesort(rechteListe)
antworte merge(linkeListe, rechteListe)
funktion merge(linkeListe, rechteListe); neueListe solange (linkeListe und rechteListe nicht leer) | falls (erstes Element der linkeListe <= erstes Element der rechteListe) | dann füge erstes Element linkeListe in die neueListe hinten ein und entferne es aus linkeListe | sonst füge erstes Element rechteListe in die neueListe hinten ein und entferne es aus rechteListe solange_ende solange (linkeListe nicht leer) | füge erstes Element linkeListe in die neueListe hinten ein und entferne es aus linkeListe solange_ende solange (rechteListe nicht leer) | füge erstes Element rechteListe in die neueListe hinten ein und entferne es aus rechteListe solange_ende antworte neueListe
Beispiel
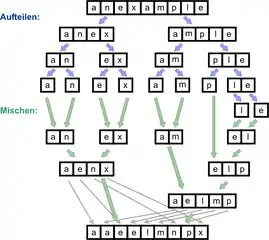
Im letzten Verschmelzungsschritt ist das Reißverschlussverfahren beim Verschmelzen (in der Abb. „Mischen:“) angedeutet. Blaue Pfeile verdeutlichen den Aufteilungsschritt, grüne Pfeile die Verschmelzungsschritte.
Es folgt ein Beispielcode analog zum obigen Abschnitt "Implementierung" für den rekursiven Sortieralgorithmus. Er teilt rekursiv absteigend die Eingabe in 2 kleinere Listen, bis diese trivialerweise sortiert sind, und verschmilzt sie auf dem rekursiven Rückweg, wodurch sie sortiert werden.
function merge_sort(list x)
if length(x) ≤ 1 then
return x // Kurzes x ist trivialerweise sortiert.
var l := empty list
var r := empty list
var nx := length(x)−1
// Teile x in die zwei Hälften l und r ...
for i := 0 to floor(nx/2) do
append x[i] to l
for i := floor(nx/2)+1 to nx do
append x[i] to r
// ... und sortiere beide (einzeln).
l := merge_sort(l)
r := merge_sort(r)
// Verschmelze die sortierten Hälften.
return merge(l, r)
Beispielcode zum Verschmelzen zweier sortierter Listen.
function merge(list l, list r)
var y := empty list // Ergebnisliste
var nl := length(l)−1
var nr := length(r)−1
var il := 0
for i := 0 to nl+nr+1 do
if il > nl then
append r[i−il] to y
continue
if il < i−nr then
append l[il] to y
il := il+1
continue
// Jetzt ist 0 ≤ il ≤ nl und 0 ≤ i−il ≤ nr.
if l[il] ≤ r[i−il] then
append l[il] to y
il := il+1
else
append r[i−il] to y
return y
Java-Implementation
Eine iterative Implementation in der Programmiersprache Java unter Verwendung von verketteten Listen könnte folgendermaßen aussehen:
(Es wird eine merge()-Funktion zu verschmelzen zweier Listen verwendet, die im Absatz darunter erläutert wird.)
void mergeSort(List<Integer> l) {
int n = l.size();
//Erstelle n Teillisten. (1 Element pro Liste) (Divide)
LinkedList<LinkedList<Integer>> groups = new LinkedList<LinkedList<Integer>>();
for (int i = 0; i < n; i++) {
LinkedList<Integer> list = new LinkedList<>();
list.add(l.get(i));
groups.add(list);
}
//Solange mehrere Gruppen existieren:
while (groups.size() > 1) {
//Merge die ersten beiden Listen im vorrat und hänge die verbundene Liste hinten an.
groups.addLast(merge(groups.removeFirst(), groups.removeFirst()));
}
//Überschreibe die unsortierte Liste mit der sortierten Version
list = groups.getFirst();
}
Der Merge-Schritt im Detail
Gegeben sind zwei in sich sortierte Listen und , die zu einer sortierten Liste zusammengefügt werden sollen.



Man vergleicht nun die beiden kleinsten Elemente (am Anfang der Listen und ), fügt das kleinere zu hinzu und nimmt es aus der jeweiligen Liste oder heraus.
Dies wird so lange wiederholt bis eine der beiden Listen A oder B leer ist, danach wird der Rest aus der anderen Liste oder (in der noch Einträge vorhanden sind) ans Ende von gehängt.
Der Mergeschritt braucht genau immer Operationen, da jedes Element aus beiden Listen in konstanter Zeit gelöscht und hinzugefügt werden kann. Die Laufzeit beträgt folglich:


LinkedList<Integer> merge(LinkedList<Integer> linkeListe, LinkedList<Integer> rechteListe) {
LinkedList<Integer> temp = new LinkedList<>();
// Solange noch nicht beide Listen hinzugefügt worden
while (!linkeListe.isEmpty() && !rechteListe.isEmpty()) {
if (linkeListe.getFirst() <= rechteListe.getFirst()) {
temp.addLast(linkeListe.removeFirst());
} else {
temp.addLast(rechteListe.removeFirst());
}
}
// Füge Rest hinzu, falls etwas übrig ist.
temp.addAll(linkeListe);
temp.addAll(rechteListe);
return temp;
}
Komplexität
Mergesort ist ein stabiles Sortierverfahren, vorausgesetzt der Merge-Schritt ist entsprechend implementiert. Seine Komplexität beträgt im Worst-, Best- und Average-Case in Landau-Notation ausgedrückt stets .

Damit ist Mergesort hinsichtlich der Komplexität Quicksort grundsätzlich überlegen, da Quicksort (ohne besondere Vorkehrungen) ein Worst-Case-Verhalten von besitzt. Es benötigt jedoch zusätzlichen Speicherplatz (der Größenordnung ), ist also kein In-place-Verfahren.


Für die Laufzeit von Mergesort bei zu sortierenden Elementen gilt die Rekursionsformel



mit dem Rekursionsanfang .

Nach dem Master-Theorem kann die Rekursionsformel durch bzw. approximiert werden mit jeweils der Lösung (2. Fall des Mastertheorems, s. dort) .



| Durchschnittliche und maximale Anzahl Vergleiche | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Sind die Längen der zu verschmelzenden und vorsortierten Folgen dann gilt für die Anzahl der erforderlichen Vergleiche fürs sortierende Verschmelzen
da erstens eine Folge komplett vor der anderen liegen kann, d. h., es ist bzw. oder es ist zweitens (bzw. umgekehrt), sodass die Elemente bis zum letzten Element in jeder Folge verglichen werden müssen. Dabei ist jeweils angenommen, dass das Vergleichen der zwei Folgen bei den Elementen mit niedrigem Index beginnt. Mit (Subskript für maximal) sei die maximale Anzahl der Vergleiche fürs Verschmelzen bezeichnet. Für die maximale Anzahl an Vergleichen für einen ganzen Mergesort-Lauf von Elementen errechnet sich daraus
ist die Folge A001855 in OEIS. Für eine Gleichverteilung lässt sich auch die durchschnittliche Anzahl (Subskript für durchschnittlich) der Vergleiche genau berechnen, und zwar ist für und für Dabei ist die Anzahl der Vergleiche für die Anordnung
wobei für das letzte (das am höchsten sortierende) Element in der Folge steht, die (nicht von einem Element aus unterbrochenen) en zu gehören und (die auch fehlen können) entweder zu oder zu gehören. Der in den Summenformeln beigegebene Binomialkoeffizient zählt die verschiedenen Möglichkeiten für Für die durchschnittliche Anzahl an Vergleichen für einen ganzen Mergesort-Lauf von Elementen errechnet man daraus
und findet |






























Korrektheit und Terminierung
Der Rekursionsabbruch stellt die Terminierung von Mergesort offensichtlich sicher, so dass lediglich noch die Korrektheit gezeigt werden muss. Dies geschieht, indem wir folgende Behauptung beweisen:
Behauptung: In Rekursionstiefe werden die sortierten Teillisten aus Rekursionstiefe korrekt sortiert.


Beweis: Sei o. B. d. A. die -te Rekursion die tiefste. Dann sind die Teillisten offensichtlich sortiert, da sie einelementig sind. Somit ist ein Teil der Behauptung schon mal gesichert. Nun werden diese sortierten Teillisten eine Rekursionsebene nach oben, also in die -te Rekursion übergeben. Dort werden diese nach Konstruktion der merge-Prozedur von Mergesort korrekt sortiert. Somit ist unsere Behauptung erfüllt und die totale Korrektheit von Mergesort bewiesen.

Natural Mergesort
Natural Mergesort (natürliches Mergesort) ist eine Erweiterung von Mergesort, die bereits vorsortierte Teilfolgen, so genannte runs, innerhalb der zu sortierenden Startliste ausnutzt. Die Basis für den Mergevorgang bilden hier nicht die rekursiv oder iterativ gewonnenen Zweiergruppen, sondern die in einem ersten Durchgang zu bestimmenden runs:
Startliste : 3--4--2--1--7--5--8--9--0--6 Runs bestimmen: 3--4 2 1--7 5--8--9 0--6 Merge : 2--3--4 1--5--7--8--9 0--6 Merge : 1--2--3--4--5--7--8--9 0--6 Merge : 0--1--2--3--4--5--6--7--8--9
Diese Variante hat den Vorteil, dass sortierte Folgen „erkannt“ werden und die Komplexität im Best-Case beträgt. Average- und Worst-Case-Verhalten ändern sich hingegen nicht.
Außerdem eignet sich Mergesort gut für größere Datenmengen, die nicht mehr im Hauptspeicher gehalten werden können – es müssen jeweils nur beim Verschmelzen in jeder Ebene zwei Listen vom externen Zwischenspeicher (z. B. Festplatte) gelesen und eine dorthin geschrieben werden. Eine Variante nutzt den verfügbaren Hauptspeicher besser aus (und minimiert Schreib-/Lesezugriffe auf der Festplatte), indem mehr als nur zwei Teil-Listen gleichzeitig vereinigt werden, und damit die Rekursionstiefe abnimmt.
Paralleler Mergesort
Mergesort lässt sich aufgrund des Teile-und-herrsche Ansatzes gut parallelisieren. Verschiedene parallele Varianten wurden in der Vergangenheit entwickelt. Manche sind stark verwandt mit der hier vorgestellten sequentiellen Variante, während andere eine grundlegend verschiedene Struktur besitzen und das K-Wege-Mischen verwenden.
Mergesort mit parallelen Rekursionsaufrufen
Der sequentielle Mergesort kann in zwei Phasen beschrieben werden, die Teilen-Phase und die anschließende Misch-Phase. Die erste besteht aus vielen rekursiven Aufrufen, die immer wieder den gleichen Aufteilungsprozess durchführen, bis die Teilsequenzen trivial sortiert sind (mit einem oder keinem Element). Ein intuitiver Ansatz ist es, diese rekursiven Aufrufe zu parallelisieren.[3] Der folgende Pseudocode beschreibt den klassischen Mergesort Algorithmus mit paralleler Rekursion unter Verwendung der Schlüsselwörter fork and join.
// Sort elements lo through hi (exclusive) of array A.
algorithm mergesort(A, lo, hi) is
if lo+1 < hi then // Two or more elements.
mid := ⌊(lo + hi) / 2⌋
fork mergesort(A, lo, mid)
mergesort(A, mid, hi)
join
merge(A, lo, mid, hi)
Dieser Algorithmus ist die triviale Modifikation des sequentiellen Algorithmus und ist noch nicht optimal. Sein Speedup ist dementsprechend auch nicht beeindruckend. Er hat einen Spann von , was nur eine Verbesserung um den Faktor ist im Vergleich zur sequentiellen Version (siehe auch Introduction to Algorithms). Dies liegt hauptsächlich an der sequentiellen Mischmethode, welche der Flaschenhals der parallelen Ausführung ist.


Mergesort mit paralleler Mischmethode
Ein besserer Parallelismus kann durch eine parallele Mischmethode erreicht werden. Cormen et al. präsentieren eine binäre Variante, welche zwei sortierte Teilsequenzen in eine sortierte Ausgabesequenz mischt. Eine ausführlichere Beschreibung findet sich hier.[3]
In der längeren der beiden Sequenzen (falls ungleich lang) wird das Element des mittleren Indexes ausgewählt. Seine Position in der anderen Sequenz wird so bestimmt, dass die Sequenz sortiert bliebe, wenn dieses Element an der bestimmten Stelle eingefügt werden würde. So weiß man, wie viele Elemente insgesamt kleiner sind als das Pivotelement, und die finale Position des Pivots kann in der Ausgabesequenz berechnet werden. Für die so erzeugten Teilfolgen der kleineren und größeren Elemente wird die Mischmethode wieder parallel ausgeführt, bis der Basisfall der Rekursion erreicht ist.
Der folgende Pseudocode illustriert den Mergesort mit modifizierter paralleler Mischmethode (aus Cormen et al.).
/**
* A: Input array
* B: Output array
* lo: lower bound
* hi: upper bound
* off: offset
*/
algorithm parallelMergesort(A, lo, hi, B, off) is
len := hi - lo + 1
if len == 1 then
B[off] := A[lo]
else let T[1..len] be a new array
mid := ⌊(lo + hi) / 2⌋
mid' := mid - lo + 1
fork parallelMergesort(A, lo, mid, T, 1)
parallelMergesort(A, mid + 1, hi, T, mid' + 1)
join
parallelMerge(T, 1, mid', mid' + 1, len, B, off)
Um eine Rekurrenzrelation für den Worst Case zu erhalten müssen die rekursiven Aufrufe von parallelMergesort aufgrund der parallelen Ausführung nur einmal aufgeführt werden. Man erhält
.

Für genauere Informationen über die Komplexität der parallelen Mischmethode, siehe Merge algorithm.
Die Lösung dieser Rekurrenz ist
.

Dieser Algorithmus erreicht eine Parallelisierbarkeit von , was um einiges besser ist als der Parallelismus des vorherigen Algorithmus. Solch ein Sortieralgorithmus kann, wenn er mit einem schnellen stabilen sequentiellen Sortieralgorithmus und einer sequentiellen Mischmethode als Basisfall für das Mischen von zwei kleinen Sequenzen ausgestattet ist gut in der Praxis funktionieren.[4]

Paralleler Mehrwege-Mergesort
Es wirkt unnatürlich, Mergesort Algorithmen auf binäre Mischmethoden zu beschränken, da oftmals mehr als zwei Prozessoren zur Verfügung stehen. Ein besserer Ansatz wäre es, ein K-Wege-Mischen zu realisieren. Diese Generalisierung mischt im Gegensatz zum binären Mischen sortierte Sequenzen zu einer sortierten Sequenz. Diese Misch-Variante eignet sich gut zur Beschreibung eines Sortieralgorithmus auf einem PRAM.[5][6]
Grundidee


Gegeben sei eine Folge von Elementen. Ziel ist es, diese Sequenz mit verfügbaren Prozessoren zu sortieren. Die Elemente sind dabei gleich auf alle Prozessoren aufgeteilt und werden zunächst lokal mit einem sequentiellen Sortieralgorithmus vorsortiert. Dementsprechend bestehen die Daten nun aus sortierten Folgen der Länge . Der Einfachheit halber sei ein Vielfaches von , so dass für gilt: . Jede dieser Sequenzen wird wiederum in Teilsequenzen partitioniert, indem für die Trennelemente mit globalem Rang bestimmt werden. Die korrespondierenden Indizes werden in jeder Folge mit binärer Sucher ermittelt, sodass die Folgen anhand der Indizes aufgeteilt werden können. Formal definiert gilt somit .











Nun werden die Elemente von dem Prozessor zugeteilt. Dies sind alle Elemente vom globalen Rang bis zum Rang , die über die verteilt sind. So erhält jeder Prozessor eine Folge von sortierten Sequenzen. Aus der Tatsache, dass der Rang der Trennelemente global gewählt wurde, ergeben sich zwei wichtige Eigenschaften: Zunächst sind die Trennelemente so gewählt, dass jeder Prozessor nach der Zuteilung der neuen Daten immer noch mit Elementen betraut ist. Der Algorithmus besitzt also eine perfekte Lastverteilung. Außerdem sind alle Elemente des Prozessors kleiner oder gleich der Elemente des Prozessors . Wenn nun jeder Prozessor ein p-Wege-Mischen lokal durchführt, sind aufgrund dieser Eigenschaft die Elemente global sortiert. Somit müssen die Ergebnisse nur in der Reihenfolge der Prozessoren zusammengesetzt werden.






Trennelementbestimmung
In der einfachsten Form sind sortierte Folgen gleichverteilt auf Prozessoren sowie ein Rang gegeben. Gesucht ist nun ein Trennelement mit globalem Rang in der Vereinigung der Folgen. Damit kann jede Folge an einem Index in zwei Teile aufgeteilt werden: Der untere Teil besteht nur aus Elementen, die kleiner sind, während der obere Teil alle Elemente enthält, welche größer oder gleich als sind.


Der hier vorgestellte sequentielle Algorithmus gibt die Indizes der Trennungen zurück, also die Indizes in den Folgen , sodass einen global kleineren Rang als hat und ist.[7]


algorithm msSelect(S : Array of sorted Sequences [S_1,..,S_p], k : int) is
for i = 1 to p do
(l_i, r_i) = (0, |S_i|-1)
while there exists i: l_i < r_i do //pick Pivot Element in S_j[l_j],..,S_j[r_j], chose random j uniformly v := pickPivot(S, l, r) for i = 1 to p do m_i = binarySearch(v, S_i[l_i, r_i]) //sequentially if m_1 + ... + m_p >= k then //m_1+ ... + m_p is the global rank of v r := m //vector assignment else l := m
return l
Für die Komplexitätsanalyse wurde das PRAM-Modell gewählt. Die p-fache Ausführung der binarySearch Methode hat eine Laufzeit in , falls die Daten über alle Prozessoren gleichverteilt anliegen. Die erwartete Rekursionstiefe beträgt wie im Quickselect Algorithmus . Somit ist die gesamte erwartete Laufzeit .



Angewandt auf den parallelen Mehrwege-Mergesort muss die msSelect Methode parallel ausgeführt werden, um alle Trennelemente vom Rang gleichzeitig zu finden. Dies kann anschließend verwendet werden, um jede Folge in Teile zu zerschneiden. Es ergibt sich die gleiche Gesamtlaufzeit .

Pseudocode
Hier ist der komplette Pseudocode für den parallelen Mehrwege-Mergesort. Dabei wird eine Barriere-Synchronisation vor und nach der Trennelementbestimmung angenommen, sodass jeder Prozessor seine Trennelemente und die Partitionierung seiner Sequenz richtig berechnen kann.
/** * d: Unsorted Array of Elements * n: Number of Elements * p: Number of Processors * return Sorted Array */ algorithm parallelMultiwayMergesort(d : Array, n : int, p : int) is o := new Array[0, n] // the output array for i = 1 to p do in parallel // each processor in parallel S_i := d[(i-1) * n/p, i * n/p] // Sequence of length n/p sort(S_i) // sort locally synch v_i := msSelect([S_1,...,S_p], i * n/p) // element with global rank i * n/p synch (S_i,1 ,..., S_i,p) := sequence_partitioning(si, v_1, ..., v_p) // split s_i into subsequences
o[(i-1) * n/p, i * n/p] := kWayMerge(s_1,i, ..., s_p,i) // merge and assign to output array
return o
Analyse
Zunächst sortiert jeder Prozessor die zugewiesenen Elemente lokal mit einem vergleichsbasierten Sortieralgorithmus der Komplexität . Anschließend können die Trennelemente in Zeit bestimmt werden. Schließlich müssen jede Gruppe von Teilstücken gleichzeitig von jedem Prozessor zusammen gemischt werden. Dies hat eine Laufzeit von , indem ein sequentieller k-Wege Mischalgorithmus verwendet wird. Somit ergibt sich eine Gesamtlaufzeit von



.

Praktische Anpassung und Anwendung
Der Mehrwege-Mergesort Algorithmus ist durch seine hohe Parallelität, was den Einsatz vieler Prozessoren ermöglicht, sehr skalierbar. Dies macht den Algorithmus zu einem brauchbaren Kandidaten für das Sortieren großer Datenmengen, wie sie beispielsweise in Computer-Clustern verarbeitet werden. Da der Speicher in solchen Systemen in der Regel keine limitierende Ressource darstellt, ist der Nachteil der Speicherkomplexität von Mergesort vernachlässigbar. Allerdings werden in solchen Systemen andere Faktoren wichtig, die bei der Modellierung auf einer PRAM nicht berücksichtigt werden. Hier sind unter anderem die folgenden Aspekte zu berücksichtigen: Die Speicherhierarchie, wenn die Daten nicht in den Cache der Prozessoren passen, oder der Kommunikationsaufwand beim Datenaustausch zwischen den Prozessoren, der zu einem Engpass werden könnte, wenn auf die Daten nicht mehr über den gemeinsamen Speicher zugegriffen werden kann.
Sanders et al. haben in ihrem Paper einen bulk synchronous parallel-Algorithmus für einen mehrstufigen Mehrwege-Mergesort vorgestellt, der Prozessoren in Gruppen der Größe unterteilt. Alle Prozessoren sortieren zuerst lokal. Im Gegensatz zu einem einstufigen Mehrwege-Mergesort werden diese Sequenzen dann in Teile aufgeteilt und den entsprechenden Prozessorgruppen zugeordnet. Diese Schritte werden innerhalb dieser Gruppen rekursiv wiederholt. So wird die Kommunikation reduziert und insbesondere Probleme mit vielen kleinen Nachrichten vermieden. Die hierarchische Struktur des zugrundeliegenden realen Netzwerks (z. B. Racks, Cluster,...) kann zur Definition der Prozessorgruppen verwendet werden.[6]


Weitere Varianten
Mergesort war einer der ersten Sortieralgorithmen, bei dem ein optimaler Speedup erreicht wurde, wobei Richard Cole einen cleveren Subsampling-Algorithmus verwendete, um die O(1)-Zusammenführung sicherzustellen.[8] Andere ausgeklügelte parallele Sortieralgorithmen können die gleichen oder bessere Zeitschranken mit einer niedrigeren Konstante erreichen. David Powers beschrieb beispielsweise 1991 einen parallelisierten Quicksort (und einen verwandten Radixsort), der durch implizite Partitionierung in Zeit auf einer CRCW-Parallel Random Access Machine (PRAM) mit Prozessoren arbeiten kann.[9] Powers zeigt ferner, dass eine Pipeline-Version von Batchers Bitonic Mergesort in Zeit auf einem Butterfly-Sortiernetzwerk in der Praxis schneller ist als sein Sortieralgorithmus auf einer PRAM, und er bietet eine detaillierte Diskussion der versteckten Overheads beim Vergleich, bei der Radix- und der Parallelsortierung.[10]


Sonstiges
Da Mergesort die Startliste sowie alle Zwischenlisten sequenziell abarbeitet, eignet er sich besonders zur Sortierung von verketteten Listen. Für Arrays wird normalerweise ein temporäres Array derselben Länge des zu sortierenden Arrays als Zwischenspeicher verwendet (das heißt Mergesort arbeitet normalerweise nicht in-place, s. o.). Quicksort dagegen benötigt kein temporäres Array.
Die SGI-Implementierung der Standard Template Library (STL) verwendet den Mergesort als Algorithmus zur stabilen Sortierung.[11]
Literatur
- Robert Sedgewick: Algorithmen. Pearson Studium, 2002, ISBN 3-8273-7032-9.
Weblinks
Einzelnachweise
- Donald E. Knuth: The Art of Computer Programming. 2. Auflage. Vol. 3: Sorting and Searching. Addison-Wesley, 1998, S. 158.
- h2database/h2database. In: GitHub. Abgerufen am 1. September 2016.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein: Introduction to algorithms. 3. Auflage. MIT Press, Cambridge, Mass. 2009, ISBN 978-0-262-27083-0.
- Victor J. Duvanenko: Parallel Merge Sort. In: Dr. Dobb's Journal & blog. duvanenko.tech.blog and GitHub repo C++ implementation github.com
- Peter Sanders, Johannes Singler: MCSTL:Multi-Core Standard Template Library. Practical Implementation of Parallel Algorithms for Shared-Memory Systems. 2008. Lecture Parallel algorithms Last visited 05.02.2020. http://algo2.iti.kit.edu/sanders/courses/paralg08/singler.pdf
- dl.acm.org (Hrsg.): Practical Massively Parallel Sorting | Proceedings of the 27th ACM symposium on Parallelism in Algorithms and Architectures. doi:10.1145/2755573.2755595 (englisch, acm.org [abgerufen am 28. Februar 2020]).
- Peter Sanders. 2019. Lecture Parallel algorithms Last visited 05.02.2020. http://algo2.iti.kit.edu/sanders/courses/paralg19/vorlesung.pdf
- Richard Cole: Parallel Merge Sort. In: SIAM Journal on Computing. Band 17, Nr. 4, August 1988, ISSN 0097-5397, S. 770–785, doi:10.1137/0217049 (siam.org [abgerufen am 6. März 2020]).
- David M. W. Powers: Parallelized Quicksort and Radixsort with Optimal Speedup. In: Proceedings of International Conference on Parallel Computing Technologies. Novosibirsk 1991.
- David M. W. Powers: Parallel Unification: Practical Complexity, Australasian Computer Architecture Workshop, Flinders University, January 1995.
- http://www.sgi.com/tech/stl/stable_sort.html stable_sort