Lastverteilung (Informatik)
Mittels Lastverteilung (englisch Load Balancing) werden in der Informatik umfangreiche Berechnungen oder große Mengen von Anfragen auf mehrere parallel arbeitende Systeme verteilt mit dem Ziel, ihre gesamte Verarbeitung effizienter zu gestalten.
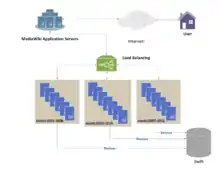
Lastverteilung ist das Ergebnis der Forschung im Bereich der Parallelrechner. Zwei Hauptansätze existieren nebeneinander: statische Algorithmen, die den Zustand der verschiedenen Maschinen nicht berücksichtigen, und dynamische Algorithmen, die öfters allgemeiner und effizienter sind, aber dafür einen anspruchsvollen Informationsaustausch zwischen den verschiedenen Recheneinheiten erfordern, was der Effizienz schaden kann.
Dies kann sehr unterschiedliche Ausprägungen haben. Eine einfache Lastverteilung findet zum Beispiel auf Rechnern mit mehreren Prozessoren statt. Jeder Prozess kann auf einem eigenen Prozessor ausgeführt werden. Die Art der Verteilung der Prozesse auf Prozessoren kann dabei einen großen Einfluss auf die Gesamtperformance des Systems haben, da z. B. der Cache-Inhalt lokal für jeden Prozessor ist. Ein anderes Verfahren findet man bei Computerclustern bzw. Servern. Hierbei bilden mehrere Rechner einen Verbund, der sich nach außen meistens wie ein einzelnes System verhält.
Problemübersicht
Ein Lastverteilungsalgorithmus versucht immer, ein bestimmtes Problem zu lösen. Unter anderen sollen die Art der zu lösenden Aufgaben, die algorithmische Komplexität, die Hardware-Architektur sowie die Fehlertoleranz berücksichtigt werden. Daher muss ein Kompromiss gefunden werden, um die anwendungsspezifischen Anforderungen bestmöglich zu erfüllen.
Art der Jobs
Die Effizienz von Lastverteilungsalgorithmen hängt entscheidend von der Art der Jobs ab. Je mehr Informationen über die Aufgaben zum Zeitpunkt der Entscheidungsfindung verfügbar sind, desto größer ist daher das Optimierungspotenzial.
Größe
Eine perfekte Kenntnis der Ausführungszeit jeder der Aufgaben erlaubt es, eine optimale Lastverteilung zu erreichen (siehe den Präfixsumme Algorithmus unten).[1] Leider handelt es sich hierbei tatsächlich um einen idealisierten Fall. Die genaue Kenntnis der Ausführungszeit jeder Aufgabe ist eine extrem seltene Situation.
Aus diesem Grund gibt es verschiedene Techniken, um sich eine Vorstellung von den verschiedenen Ausführungszeiten zu machen. Zunächst einmal kann man in dem glücklichen Fall, dass es sich um Aufgaben von relativ homogener Größe handelt, davon ausgehen, dass jede von ihnen ungefähr die durchschnittliche Ausführungszeit erfordert. Wenn die Ausführungszeit hingegen sehr unregelmäßig ist, müssen subtilere Techniken verwendet werden. Eine Technik ist das Hinzufügen einiger Metadaten zu jeder Aufgabe. Abhängig von der bisherigen Ausführungszeit für ähnliche Metadaten können auf der Grundlage von Statistiken Rückschlüsse für eine zukünftige Aufgabe gezogen werden.[2]
Schließlich kann die Anzahl der Aufgaben selbst von einiger Bedeutung sein.
Abhängigkeit
In einigen Fällen hängen die Aufgaben voneinander ab. Diese gegenseitigen Abhängigkeitsrelationen können durch eine azyklisch orientierten Grafen (englisch Directed acyclic graph) veranschaulicht werden. Intuitiv können einige Aufgaben erst beginnen, wenn andere nicht abgeschlossen sind.
Unter der Annahme, dass die erforderliche Zeit für jede der Aufgaben im Voraus bekannt ist, muss eine optimale Ausführungsreihenfolge zur Minimierung der Gesamtausführungszeit führen. Obwohl dies ein NP-schwere Problem ist und daher schwer genau zu lösen sein kann, gibt es Scheduling-Algorithmen, die ehrenhafte Aufgabenverteilungen erzeugen.
Spaltbarkeit
Ein weiteres Merkmal der Jobs, das einen großen Einfluss auf das Design des Lastverteilungsalgorithmus hat, ist ihre Fähigkeit, während der Ausführung in Teilaufgaben aufgeteilt zu werden. Der „Work-Stealing“ Algorithmus, den wir später vorstellen werden, nutzt diese Besonderheit.
Statische Algorithmen
Ein Lastverteilungsalgorithmus wird als „statisch“ bezeichnet, wenn er den Zustand des Systems bei der Aufgabenverteilung nicht berücksichtigt. Unter Systemzustand verstehen wir hier die Auslastung (und manchmal sogar Überlastung) bestimmter Prozessoren. Stattdessen werden im Vorfeld Annahmen über das Gesamtsystem getroffen, wie z. B. die Ankunftszeiten und der Ressourcenbedarf der eingehenden Aufgaben. Darüber hinaus sind die Anzahl der Prozessoren, ihre jeweilige Leistung und Kommunikationsgeschwindigkeit bekannt. Es geht also darum, Aufgaben mit den Prozessoren so zu verbinden, dass eine bestimmte Leistungsfunktion minimiert wird. Der Trick liegt in der Gestaltung dieser Leistungsfunktion.
Die Techniken sind immer um einen Router herum zentralisiert, der die Lasten verteilt und die Optimierung der Funktion gewährleistet. Diese Minimierung kann Informationen in Bezug auf die zu verteilenden Aufgaben berücksichtigen und eine erwartete Ausführungszeit ableiten.
Der Vorteil von statischen Algorithmen ist, dass sie leicht zu implementieren und bei relativ regelmäßigen Aufgaben (wie der Verarbeitung von HTTP-Anfragen einer Website) äußerst effizient sind. Es gibt jedoch immer noch statistische Varianz in der Aufgabenverteilung, die zu einer Überlastung einiger Recheneinheiten führen kann.
Dynamische Algorithmen
Im Gegensatz zu statischen Lastverteilungsalgorithmen berücksichtigen dynamische Algorithmen die aktuelle Last jeder der Recheneinheiten (auch Knoten genannt) im System. Bei diesem Ansatz können Aufgaben dynamisch von einem überlasteten Knoten zu einem unterlasteten Knoten verschoben werden, um eine schnellere Verarbeitung zu erhalten. Obwohl diese Algorithmen viel komplizierter zu entwerfen sind, können sie hervorragende Ergebnisse liefern, insbesondere wenn die Ausführungszeit von einer Aufgabe zur anderen stark variiert.
Beim dynamischen Lastverteilung kann die Architektur modularer sein, da es nicht zwingend erforderlich ist, einen speziellen Knoten für die Arbeitsverteilung zu haben. Wenn Aufgaben einem Prozessor entsprechend seinem Zustand zu einem bestimmten Zeitpunkt eindeutig zugeordnet werden, sprechen wir von einer eindeutigen Zuordnung. Wenn andererseits die Aufgaben entsprechend dem Zustand des Systems und seiner Entwicklung permanent neu verteilt werden können, spricht man von dynamischer Zuweisung. Offensichtlich ist ein Lastverteilungsalgorithmus, der zu viel Kommunikation erfordert, um seine Entscheidungen zu treffen, nicht wünschenswert, auf die Gefahr hin, die Lösung des Gesamtproblems zu verlangsamen. Der schlimmste Fall ist ein Ping-Pong-Spiel zwischen den Prozessoren, das zu einer unbegrenzten Blockierung der Lösung führt.[3]
Heterogene Maschinen
Parallele Rechner Infrastrukturen bestehen oft aus Einheiten unterschiedlicher Rechenleistung, die bei der Lastverteilung berücksichtigt werden sollten.
Beispielsweise können Einheiten mit geringerer Leistung Anfragen erhalten, die einen geringeren Berechnungsaufwand erfordern, oder, im Falle homogener oder unbekannter Anfragegrößen, weniger Anfragen erhalten als größere Einheiten.
Gemeinsamer und verteilter Speicher
Parallelrechner werden oft in zwei große Kategorien unterteilt: solche, bei denen sich alle Prozessoren einen einzigen gemeinsamen Speicher teilen, auf dem sie parallel lesen und schreiben (PRAM-Modell), und solche, bei denen jede Recheneinheit über einen eigenen Speicher verfügt (Modell des verteilten Speichers) und Informationen durch Nachrichten mit den anderen Einheiten austauscht.
Bei Computern mit gemeinsamem Speicher verlangsamt die Verwaltung von Schreib Konflikten die individuelle Ausführungsgeschwindigkeit jeder einzelnen Recheneinheit erheblich. Sie können jedoch gut parallel arbeiten. Umgekehrt kann beim Nachrichtenaustausch jeder der Prozessoren mit voller Geschwindigkeit arbeiten. Andererseits sind beim Nachrichtenaustausch alle Prozessoren gezwungen, auf den Beginn der Kommunikationsphase durch die langsamsten Prozessoren zu warten.
In der Realität fallen nur wenige Systeme in genau eine der Kategorien. Im Allgemeinen verfügen die Prozessoren jeweils über einen internen Speicher, um die für die nächsten Berechnungen benötigten Daten zu speichern, und sind in aufeinanderfolgenden Clustern organisiert. Häufig werden diese Verarbeitungselemente dann durch verteilten Speicher und Nachrichtenaustausch koordiniert. Daher sollte der Lastverteilungsalgorithmus eindeutig an eine parallele Architektur angepasst werden. Andernfalls besteht die Gefahr, dass die Effizienz der parallelen Problemlösung stark beeinträchtigt wird.
Hierarchie
Zur Anpassung an den oben dargestellten Hardware Strukturen gibt es zwei Hauptkategorien von Lastverteilungsalgorithmen. Einerseits werden die Aufgaben von einem „Master“ zugewiesen und von „Arbeitern“ ausgeführt (Master-Slave-Modell), die den Master über die Entwicklung ihrer Arbeit auf dem Laufenden halten. Der Master kann dann für die Zuweisung (und Neuzuweisung) der Arbeitslast verantwortlich sein, wenn der Algorithmus dynamisch (mit dynamischer Zuweisung) ist. Die Literatur spricht von der „Meister-Arbeiter“-Architektur. Umgekehrt kann die Steuerung auf die verschiedenen Knoten verteilt werden. Der Lastverteilungsalgorithmus wird dann auf jedem von ihnen ausgeführt, und die Verantwortung für die Zuweisung von Jobs (sowie gegebenenfalls für die Neuzuweisung und Aufteilung) wird geteilt. Die letztere Kategorie setzt einen dynamischen Lastverteilungsalgorithmus voraus.
Auch hier gilt: Da das Design jedes Lastverteilungsalgorithmus einzigartig ist, muss die vorherige Unterscheidung eingeschränkt werden. So ist auch eine Zwischenstrategie möglich, z. B. mit „Master“-Knoten für jeden Sub-Cluster, die ihrerseits einem globalen „Master“ unterliegen. Es gibt auch Organisationen mit mehreren Ebenen, mit einem Wechsel zwischen Master-Slave- und verteilten Kontrollstrategien. Letztere Strategien werden schnell komplex und sind selten anzutreffen. Developer bevorzugen leichter kontrollierbare Algorithmen.
Skalierbarkeit
Im Rahmen von Algorithmen, die sehr langfristig laufen (Server, Cloud …), entwickelt sich die Computerarchitektur im Laufe der Zeit weiter. Es ist jedoch vorzuziehen, nicht jedes Mal einen neuen Algorithmus entwerfen zu müssen.
Ein weiterer wichtiger Parameter eines Lastverteilungsalgorithmus ist daher seine Fähigkeit, sich an eine sich entwickelnde Hardware-Architektur anzupassen. Das nennt man die Skalierbarkeit des Algorithmus. Ein Algorithmus soll auch für einen Eingabeparameter skalierbar sein, wenn seine Leistung relativ unabhängig von der Größe dieses Parameters bleibt.
Wenn der Algorithmus in der Lage ist, sich an eine unterschiedliche Anzahl von Prozessoren anzupassen, die Anzahl der Prozessoren jedoch vor der Ausführung festgelegt werden muss, wird er als „formbar“ (englisch „moldable“) bezeichnet. Wenn der Algorithmus andererseits in der Lage ist, mit einer schwankenden Anzahl von Prozessoren während seiner Ausführung umzugehen, gilt der Algorithmus als „schmiedbar“ (englisch „malleable“). Die meisten Lastverteilungsalgorithmen sind zumindest formbar.[4]
Fehlertoleranz
Insbesondere in großen Rechnerverbunde ist es nicht tolerierbar, einen parallelen Algorithmus auszuführen, der dem Ausfall einer einzelnen Komponente nicht standhalten kann. Daher werden fehlertolerante Algorithmen entwickelt, die Ausfälle von Prozessoren erkennen und die Berechnung wiederherstellen können.[5]
Ansätze
Statische Lastverteilung mit vollständigem Bekenntnis der Jobs: „Prefix-Summe“ Algorithmus
Wenn die Aufgaben unabhängig voneinander und spaltbare sind, und wenn man ihre jeweilige Ausführungszeit kennt, gibt es einen einfachen und optimalen Algorithmus.
Indem die Aufgaben so aufgeteilt werden, dass jeder Prozessor den gleichen Rechenaufwand hat, müssen die Ergebnisse nur noch gruppiert werden. Mit Hilfe eines Prefix-Summe Algorithmus kann diese Division in einer logarithmischen Zeit der Anzahl der Prozessoren berechnet werden.
Wenn sich die Aufgaben jedoch nicht unterteilen lassen (man sagt, sie seien atomar), obwohl die Optimierung der Aufgabenzuweisung ein schwieriges Problem darstellt, ist es immer noch möglich, eine relativ faire Verteilung der Aufgaben zu approximieren, vorausgesetzt, dass die Größe jeder einzelnen Aufgabe viel kleiner ist als die Gesamtmenge der von jedem der Knoten durchgeführten Berechnungen.[1]
Meistens ist die Ausführungszeit einer Aufgabe unbekannt, und es liegen nur grobe Näherungswerte vor. Dieser Algorithmus ist zwar besonders effizient, aber für diese Szenarien nicht praktikabel.
Statische Lastverteilung ohne Vorkenntnisse
Wenn die Ausführungszeit überhaupt nicht im Voraus bekannt ist, ist eine statische Lastverteilung immer möglich.
Round Robin
In diesem Algorithmus wird die erste Anfrage an den ersten Server gesendet, danach die nächste an den zweiten und so weiter bis zur letzten. Dann beginnen wir wieder damit, dass wir die nächste Anfrage dem ersten Server zuweisen, und so weiter.
Dieser Algorithmus kann so gewichtet werden, dass die leistungsstärksten Einheiten die größte Anzahl von Anfragen erhalten und diese als erste erhalten.
Randomisierte Zuweisung
Es handelt sich einfach um die zufällige Zuweisung von Aufgaben an die verschiedenen Server. Diese Methode funktioniert recht gut. Wenn die Anzahl der Aufgaben im Voraus bekannt ist, ist es noch effizienter, eine zufällige Permutation im Voraus zu berechnen. Dadurch werden Kommunikationskosten für jeden Auftrag vermieden. Ein Verteilungsmeister ist nicht nötig, denn jeder weiß, welche Aufgabe ihm zugewiesen ist. Auch wenn die Anzahl der Aufgaben nicht bekannt ist, kann auf die Kommunikation mit einer allen Prozessoren bekannten pseudo-zufälligen Zuweisungsgenerierung verzichtet werden.
Die Leistung dieser Strategie (gemessen an der Gesamtausführungszeit für einen bestimmten festen Satz von Aufgaben) nimmt mit der maximalen Größe der Aufgaben ab.
„Master-Worker“

Der Master-Worker-Schema gehört zu den einfachsten dynamischen Lastverteilungsalgorithmen. Ein Meister verteilt die Arbeitslast auf alle Arbeiter (manchmal auch als „Slave“ bezeichnet). Zunächst sind alle Arbeiter untätig und melden dies dem Meister. Der Meister verteilt die Aufgaben an sie. Wenn er keine Aufgaben mehr zu vergeben hat, informiert er die Arbeiter, so dass sie nicht mehr um Arbeit bitten sollen.
Der Vorteil dieses Systems ist, dass es die Last sehr gerecht verteilt. Wenn man die für den Auftrag benötigte Zeit nicht berücksichtigt, wäre die Ausführungszeit mit der oben angegebenen Prefix-Summe vergleichbar.
Das Problem mit diesem Algorithmus ist, dass er sich aufgrund der großen Kommunikationsvolumen nur schwer an eine große Anzahl von Prozessoren anpassen kann. Dieser Mangel an Skalierbarkeit führt dazu, dass es bei sehr großen Servern oder sehr großen Parallelrechnern schnell nicht mehr funktionsfähig ist. Der Master fungiert als Engpass.
Die Qualität des Algorithmus kann jedoch erheblich verbessert werden, wenn der Master durch eine Aufgabenliste ersetzt wird, in der die verschiedenen Prozessoren verwendet werden. Obwohl dieser Algorithmus etwas schwieriger zu implementieren ist, verspricht er eine viel bessere Skalierbarkeit, auch wenn er für sehr große Rechenzentren immer noch unzureichend ist.
Verteilte Architektur, ohne Vorkenntnisse: der Arbeitsdiebstahl
Eine Technik, die zur Überwindung von Skalierbarkeitsproblemen ohne Vorkenntnis der Ausführungszeiten eingesetzt wird, ist Work stealing (englisch für Arbeitsdiebstahl).
Der Ansatz besteht darin, jedem Prozessor eine bestimmte Anzahl von Aufgaben nach dem Zufallsprinzip oder auf vordefinierte Weise zuzuweisen und dann inaktiven Prozessoren zu erlauben, Arbeit von aktiven oder überlasteten Prozessoren zu „stehlen“. Es gibt mehrere Implementierungen dieses Konzepts, die durch ein Modell der Aufgabenteilung und durch die Regeln, die den Austausch zwischen den Prozessoren bestimmen, definiert sind. Diese Technik kann zwar besonders effektiv sein, ist aber schwierig zu implementieren, da sichergestellt werden muss, dass der Nachrichtenaustausch nicht die tatsächliche Ausführung von Berechnungen zur Lösung des Problems ersetzt.
Bei den atomaren Aufgaben lassen sich zwei Hauptstrategien unterscheiden: solche, bei denen die Prozessoren mit geringer Last ihre Rechenkapazität denjenigen mit der höchsten Last anbieten, und solche, bei denen die am stärksten belasteten Einheiten die ihnen zugewiesene Arbeitsbelastung verringern wollen. Es hat sich gezeigt, dass es bei hoher Auslastung des Netzwerks effizienter ist, wenn die am wenigsten belasteten Einheiten ihre Verfügbarkeit anbieten, und dass bei geringer Auslastung des Netzwerks die überlasteten Prozessoren die Unterstützung der am niedrigsten aktiv benötigen. Diese Faustregel begrenzt die Anzahl der ausgetauschten Nachrichten.
Für den Fall, dass man von einer einzigen großen Aufgabe ausgeht, die nicht über eine atomare Ebene hinaus aufgeteilt werden kann, gibt es einen sehr effizienten Algorithmus, bei dem die übergeordnete Aufgabe in einem Baum verteilt wird.
Vorfahren
Zunächst haben alle Prozessoren eine leere Aufgabe, außer einem, der sequentiell daran arbeitet. Inaktive Prozessoren stellen dann nach dem Zufallsprinzip Anfragen an andere Prozessoren (die nicht unbedingt aktiv sind). Wenn dieser in der Lage ist, die Aufgabe, an der er arbeitet, zu unterteilen, so tut er dies, indem er einen Teil seiner Arbeit an den anfordernden Knotenpunkt sendet. Andernfalls gibt es eine leere Aufgabe zurück. Dadurch wird eine Baumstruktur erzeugt. Es ist dann notwendig, ein Beendigungssignal an den übergeordneten Prozessor zu senden, wenn die Teilaufgabe abgeschlossen ist, so dass dieser wiederum die Nachricht an seinen übergeordneten Prozessor sendet, bis er die Wurzel des Baums erreicht. Wenn der erste Prozessor, d. h. die Wurzel, fertig ist, kann eine globale Beendigungsnachricht broadcast werden. Am Ende ist es notwendig, die Ergebnisse zusammenzustellen, indem man den Baum wieder hochfährt.
Effizienz
Die Effizienz eines solchen Algorithmus liegt nahe an der Präfixsumme, wenn die Zeit für das Schneiden und die Kommunikation im Vergleich zur zu erledigenden Arbeit nicht zu hoch ist. Um zu hohe Kommunikationskosten zu vermeiden, ist es möglich, sich eine Liste von Jobs auf gemeinsamem Speicher vorzustellen. Daher liest eine Anforderung einfach von einer bestimmten Position in diesem gemeinsamen Speicher auf Anforderung des Masterprozessors.
Anwendungsbeispiele
Einige mögliche Verfahren sind das Vorschalten eines Systems (Load Balancer, Frontend Server), der die Anfragen aufteilt, oder die Verwendung von DNS mit dem Round-Robin-Verfahren. Insbesondere bei Webservern ist eine Serverlastverteilung wichtig, da ein einzelner Host nur eine begrenzte Menge an HTTP-Anfragen auf einmal beantworten kann.
Der dabei vorgeschaltete Load Balancer fügt der HTTP-Anfrage zusätzliche Informationen hinzu, um Anfragen desselben Benutzers an denselben Server zu schicken. Dies ist auch bei der Nutzung von SSL zur Verschlüsselung der Kommunikation wichtig, damit nicht für jede Anfrage ein neuer SSL-Handshake durchgeführt werden muss.
Lastverteilung wird ebenfalls bei Daten-/Sprachleitungen verwendet, um den Verkehrsfluss auf parallel geführte Leitungen zu verteilen. In der Praxis treten jedoch häufig Probleme dabei auf, den Daten-/Sprachverkehr gleichmäßig auf beide Leitungen zu verteilen. Es wird daher meist die Lösung implementiert, dass eine Leitung als Hin- und die zweite Leitung als Rückkanal Verwendung findet.
Load Balancing geht oft einher mit Mechanismen zur Ausfallsicherheit: Durch den Aufbau eines Clusters mit entsprechender Kapazität und der Verteilung der Anfragen auf einzelne Systeme erreicht man eine Erhöhung der Ausfallsicherheit, sofern der Ausfall eines Systems erkannt und die Anfragen automatisch an ein anderes System abgegeben werden (siehe auch: Hochverfügbarkeit bzw. High-Availability, „HA“).
Serverlastverteilung
Serverlastverteilung (en. Server Load Balancing, „SLB“) kommt überall dort zum Einsatz, wo sehr viele Clients eine hohe Anfragendichte erzeugen und damit einen einzelnen Server-Rechner überlasten würden. Durch Verteilung der Anfragen auf mehrere Server mittels SLB lassen sich Anwendungen skalieren. Typische Kriterien zur Ermittlung der Notwendigkeit von SLB sind die Datenrate, die Anzahl der Clients und die Anfragerate.
Ein weiterer Aspekt ist die Erhöhung der Datenverfügbarkeit durch SLB. Der Einsatz mehrerer Systeme mit selber Daten-/Anwendungsbasis ermöglicht redundante Datenhaltung. Die Aufgabe des SLB ist hier die Vermittlung der Clients an die einzelnen Server. Diese Technik wird unter anderem bei Content Delivery Networks eingesetzt.
Zum Einsatz kommt SLB bei großen Portalen wie etwa Wikipedia, Marktplätzen oder Online-Shops. Prinzipiell bemerkt der Anwender nicht, ob auf der Gegenseite SLB eingesetzt wird. Siehe auch Redirect (Weiterleitung).
SLB kann auf verschiedenen Schichten des ISO-OSI-Referenzmodells umgesetzt werden.
DNS Round Robin
Hierbei werden zu einem Hostnamen im Domain Name System mehrere IP-Adressen hinterlegt, die wechselseitig als Ergebnis von Anfragen zurückgeliefert werden. Es ist die einfachste Möglichkeit der Lastenverteilung. Für eine detaillierte Beschreibung siehe Lastverteilung per DNS.
NAT based SLB
Aufwendiger, aber leistungsfähiger ist das so genannte NAT based SLB. Hier müssen zunächst zwei Netze aufgebaut werden: ein privates Netz, dem die Server angehören, und ein öffentliches Netz, das über Router mit dem öffentlichen Internet verbunden ist. Zwischen diesen beiden Netzen wird ein Content-Switch geschaltet, also ein Router, der Anfragen aus dem öffentlichen Netz entgegennimmt, auswertet und daraufhin entscheidet, an welchen Rechner im privaten Netz er die Verbindung vermittelt. Dies geschieht auf der Vermittlungsschicht des OSI-Referenzmodells. Zum Einsatz kommt hier die NAT-Technik: Der Load Balancer manipuliert eingehende und ausgehende IP-Pakete so, dass der Client den Eindruck hat, er kommuniziere stets mit ein und demselben Rechner, nämlich dem Load Balancer. Die Server im privaten Netz haben sozusagen alle die gleiche virtuelle IP-Adresse.
Problematisch ist bei diesem Verfahren, dass der gesamte Verkehr über den Load Balancer fließt, dieser also früher oder später zum Engpass wird, sofern dieser zu klein oder nicht redundant ausgelegt wurde.
Als Vorteil ergeben sich aus dem NAT based SLB, dass die einzelnen Server durch den Load Balancer zusätzlich geschützt werden. Zahlreiche Hersteller von Load Balancer-Lösungen bieten hierfür zusätzliche Sicherheitsmodule an, die Angriffe oder auch fehlerhafte Anfragen schon vor Erreichen der Servercluster ausfiltern können. Auch die Terminierung von SSL-Sessions und somit die Entlastung der Servercluster bei HTTP-Farmen ist ein nicht zu unterschätzender Vorteil beim Server Based Loadbalancing.
Neben aktiven Healthchecks, wie sie bei den anderen Verfahren notwendig sind, sind seit einiger Zeit bei großen Web-Clustern zunehmend passive Healthchecks im Einsatz. Hier wird der ein- und ausgehende Datenverkehr durch den Load Balancer überwacht, sobald ein Rechner im Servercluster eine Zeitüberschreitung bei der Beantwortung einer Anfrage auslöst, kann hierdurch dieselbe Anfrage an einen anderen Cluster-Server gestellt werden, ohne dass dies beim Client bemerkt wird.
Flat based SLB
Bei diesem Verfahren bedarf es nur eines Netzes. Die Server und der Load Balancer müssen über einen Switch miteinander verbunden sein. Sendet der Client eine Anfrage (an den Load Balancer), wird der entsprechende Ethernet-Frame so manipuliert, dass es eine direkte Anfrage des Clients an einen der Server darstellt – der Load Balancer tauscht dazu seine eigene MAC-Adresse gegen die des zu vermittelnden Servers aus und sendet den Frame weiter. Die IP-Adresse bleibt unverändert. Man spricht bei diesem Vorgehen auch von MAT (MAC Address Translation). Der Server, der den Frame bekommen hat, sendet die Antwort direkt an die IP-Adresse des Absenders, also des Clients. Der Client hat damit den Eindruck, er kommuniziere nur mit einem einzigen Rechner, nämlich dem Load Balancer, während der Server tatsächlich nur mit einem Rechner, direkt mit dem Client, kommuniziert. Dieses Verfahren wird als DSR (Direct Server Return) bezeichnet.
Vorteil bei Flat based SLB ist die Entlastung des Load Balancers. Der (meist datenreichere) Rückverkehr findet auf direktem Wege statt.
Anycast SLB
Bei der Lastverteilung über Anycast wird eine ganze Gruppe von Rechnern über eine Adresse angesprochen. Es antwortet derjenige, der über die kürzeste Route erreichbar ist. Im Internet wird dieses mit BGP realisiert.
Der Vorteil dieser Lösung ist die geographisch nahe Auswahl eines Servers mit entsprechender Verringerung der Latenz. Die Umsetzung erfordert allerdings den Betrieb eines eigenen Autonomen Systems im Internet.
Probleme der Praxis
Anwendungen wie Online-Shops verwalten Client-Anfragen oft über Sessions. Für bestehende Sessions wird z. B. der Inhalt des Warenkorbes gespeichert. Dies setzt aber voraus, dass ein Client, für den bereits eine Session eröffnet wurde, immer wieder mit demselben Server kommuniziert, sofern hier clientbasierte Sessions verwendet werden. Entweder müssen dazu alle Verbindungen eines Clients über dessen IP auf denselben Server geleitet werden, oder der Load Balancer muss fähig sein, auf der Anwendungsschicht des OSI-Referenzmodells zu agieren, also z. B. Cookies und Session IDs aus Paketen zu extrahieren und auszuwerten, um daraufhin eine Vermittlungsentscheidung zu treffen. Das Weiterleiten einer Session auf immer denselben Backendserver wird als „Affinität“ bezeichnet. Als Load Balancer werden in der Praxis daher Layer 4-7-Switches eingesetzt. Alternativ kann das Problem auch durch die Anwendung selbst gelöst werden (z. B. durch Speicherung der Session in einer Datenbank), so dass eine Anfrage auch von einem beliebigen Rechner des Server-Pools beantwortet werden kann.[6]
Literatur
- Ingo Wegener (Hrsg.): Highlights aus der Informatik. Springer Verlag, Berlin / Heidelberg, ISBN 978-3-642-64656-0.
- Hartmut Ernst: Grundkurs Informatik. 3. Auflage, Friedrich Vieweg & Sohn, Wiesbaden 2003, ISBN 978-3-528-25717-0.
- Paul J. Kühn: Kommunikation in verteilten Systemen. Springer Verlag, Berlin / Heidelberg 1989, ISBN 978-3-540-50893-9.
- Bernd Bundschuh, Peter Sokolowsky: Rechnerstrukturen und Rechnerarchitekturen. Friedrich Vieweg & Sohn Verlag, Wiesbaden 1988, ISBN 978-3-528-04389-6.
Einzelnachweise
- Sanders Peter, Dietzfelbinger Martin, Dementiev Roman: Sequential and parallel algorithms and data structures : the basic toolbox. Hrsg.: Springer. 2019, ISBN 978-3-03025209-0.
- Qi Liu, Weidong Cai, Dandan Jin et Jian Shen: Estimation Accuracy on Execution Time of Run-Time Tasks in a Heterogeneous Distributed Environment. In: Sensors. 30. August 2016, ISSN 1424-8220, S. 1386, doi:10.3390/s16091386, PMID 27589753 (englisch).
- Alakeel, Ali: A Guide to Dynamic Load Balancing in Distributed Computer Systems. In: International Journal of Computer Science and Network Security, (IJCSNS). Vol. 10, November 2009 (englisch, researchgate.net).
- Asghar Sajjad, Aubanel Eric, Bremner David: A Dynamic Moldable Job Scheduling Based Parallel SAT Solver. In: 22013 42nd International Conference on Parallel Processing. Oktober 2013, S. 110–119, doi:10.1109/ICPP.2013.20 (ieee.org).
- G. Punetha, N. Gnanambigai, P. Dinadayalan: Survey on fault tolerant — Load balancing algorithms in cloud computing. In: IEEE (Hrsg.): 2015 2nd International Conference on Electronics and Communication Systems (ICECS). 2015, ISBN 978-1-4799-7225-8, doi:10.1109/ecs.2015.7124879.
- Shared Session Management (Memento vom 23. Mai 2011 im Internet Archive) Abgerufen am 3. Juni 2011.
Weblinks
- Lastverteilung in einer clusterbasierten verteilten virtuellen Umgebung (abgerufen am 24. Juli 2017)
- Lastverteilung in verteilten Multi-Agenten-Simulationen (abgerufen am 24. Juli 2017)
- Lastverteilung – Verteilte Systeme (abgerufen am 24. Juli 2017)
- Konzepte der parallelen Programmierung (abgerufen am 24. Juli 2017)
- Konzeption einer Hochverfügbarkeitslösung für LAMP-Systeme mit Open-Source-Software und Standard-Hardware (abgerufen am 24. Juli 2017)