Quickselect
Quickselect (englisch quick, deutsch ‚schnell‘ und to select ‚auswählen‘) ist ein Auswahlverfahren aus der Informatik, um das k-kleinste Element in einer ungeordneten Liste zu finden. Es bezieht sich auf den Quicksort-Sortieralgorithmus. Wie Quicksort wurde es von Tony Hoare entwickelt und ist daher auch als Hoare-Auswahlalgorithmus bekannt.[1] Wie Quicksort ist es in der Praxis effizient und hat einen guten Average Case, jedoch auch eine schlechte Leistung im Worst Case. Quickselect und seine Varianten sind die am häufigsten verwendeten Selektionsalgorithmen in effizienten Implementierungen in der Praxis.
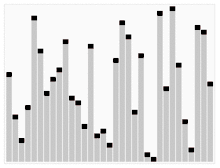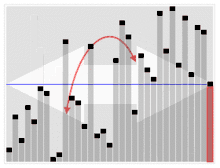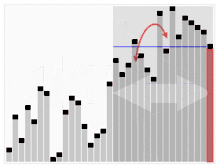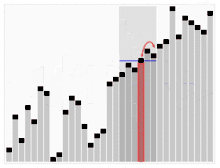
Quickselect verwendet den gleichen Gesamtansatz wie Quicksort, wählt ein Element als Pivot und teilt die Daten in zwei Teile, basierend auf dem Pivot, entsprechend kleiner oder größer als der Pivot. Anstatt jedoch, wie bei Quicksort, in beide Seiten zurückzukehren, kehrt die Schnellauswahl nur in eine Seite zurück – die Seite mit dem gesuchten Element. Dies reduziert die durchschnittliche Komplexität von auf , mit einem Worst Case von .



Wie bei Quicksort ist die Schnellauswahl im Allgemeinen als In-Place-Algorithmus implementiert, und über die Auswahl des k'ten Elements hinaus sortiert sie die Daten teilweise auch.
Prinzip
In Quicksort gibt es eine Unterprozedur namens partition, die in linearer Zeit eine Liste (von links nach rechts) in zwei Teile gruppieren kann: diejenigen, die kleiner als ein bestimmtes Element sind, und solche, die größer als oder gleich dem Element sind. Hier ist Pseudocode, der eine Partition über die Elementliste[pivotIndex] ausführt:
Funktion partition(Liste, links, rechts, pivotIndex)
pivotWert := Liste[pivotIndex]
swap Liste[pivotIndex] und Liste[rechts] // Pivot ans Ende verschieben
speicherIndex := links
für i von links bis rechts-1
falls Liste[i] < pivotWert
swap Liste[speicherIndex] und Liste[i]
inkrementiere speicherIndex
swap Liste[rechts] und Liste[speicherIndex] // Pivot an die finale Stelle verschieben
return speicherIndex
Dies ist bekannt als das Lomuto-Partitionsschema, das einfacher, aber weniger effizient ist als das ursprüngliche Partitionsschema von Hoare.
In Quicksort sortieren wir beide Zweige rekursiv, was zu einer optimalen Zeit führt. Bei der Auswahl wissen wir jedoch bereits, in welcher Partition sich unser gewünschtes Element befindet, da sich der Pivot in seiner endgültigen sortierten Position befindet, mit allen, die ihm in einer unsortierten Reihenfolge vorausgehen und allen, die ihm in einer unsortierten Reihenfolge folgen. Daher findet ein einziger rekursiver Aufruf das gewünschte Element in der richtigen Partition, und darauf aufbauend, entsteht der Quickselect-Algorithmus:

// Gibt das k-kleinste Element der Liste zurück inklusive Rechts-/Linkselement
// (z.B. links <= k <= rechts).
// Der Speicherbedarf des Datenfelds der Suche ändert sich mit jeder Rund, aber die Liste
// behält immer die gleiche Größe. Deswegen muss der Wert k nicht jede Runde aktualisiert werden.
Funktion auswählen(Liste, links, rechts, k)
falls links = rechts // falls Liste nur ein Element enthält,
return Liste[links] // return dieses Element
pivotIndex := ... // Auswahl eines Pivotelements zwischen links und rechts,
// z.B., links + floor(rand() % (rechts - links + 1))
pivotIndex := partition(Liste, links, rechts, pivotIndex)
// Pivot in seiner endgültigen sortierten Position
falls k = pivotIndex
return Liste[k]
sonst falls k < pivotIndex
return auswählen(Liste, links, pivotIndex - 1, k)
sonst
return auswählen(Liste, pivotIndex + 1, rechts, k)
Beachten Sie die Ähnlichkeit mit Quicksort: So wie der minimal-basierte Selectionsort ein Teilselectionsort ist, so ist dies eine Teilquicksort, bei der nur seiner -Partitionen erzeugt und partitioniert wird. Dieses einfache Verfahren hat eine erwartete lineare Laufzeit und, wie Quicksort, in der Praxis eine recht gute Leistung. Es ist auch ein In-Place-Algorithmus, der nur konstanten Speicher-Overhead erfordert, wenn die Endrekursionsoptimierung verfügbar ist, oder wenn die Endrekursion mit einer Schleife eliminiert wird:

Funktion auswählen(Liste, links, rechts, k)
loop
falls links = rechts
return Liste[links]
pivotIndex := ... // Auswahl PivotIndex zwischen links und rechts
pivotIndex := partition(Liste, links, rechts, pivotIndex)
falls k = pivotIndex
return Liste[k]
sonst falls k < pivotIndex
rechts := pivotIndex - 1
sonst
links := pivotIndex + 1
Zeitkomplexität
Wie Quicksort hat auch der Quickselect eine gute durchschnittliche Leistung, ist aber empfindlich gegenüber dem gewählten Pivot. Wenn gute Pivots gewählt werden, d. h. solche, die den Suchsatz konsequent um einen bestimmten Bruchteil verringern, dann nimmt der Suchsatz exponentiell ab und durch Induktion (oder Summierung der geometrischen Reihen) sieht man, dass die Leistung linear ist, da jeder Schritt linear ist und die Gesamtzeit eine konstante Zeit ist (abhängig davon, wie schnell sich der Suchsatz verringert). Wenn jedoch konsequent schlechte Pivots gewählt werden, wie z. B. die Verringerung um jeweils nur ein einziges Element, dann ist die Worst-Case Performance quadratisch: . Dies geschieht z. B. bei der Suche nach dem maximalen Element einer Menge, wobei das erste Element als Pivot verwendet wird und die Daten sortiert werden.
Einzelnachweise
- C. A. R. Hoare: Algorithm 65: find. Hrsg.: Communications of the ACM. Volume 4, Issue 7, Juli 1961, S. 321–322 (acm.org).