Kryptographische Hashfunktion
Eine kryptologische Hashfunktion oder kryptografische Hashfunktion ist eine Hashfunktion (Streuwertfunktion) mit besonderen, für die Kryptographie erwünschten Eigenschaften. Eine Hashfunktion erzeugt aus einem Eingabewert (z. B. eine Nachricht oder eine Datei) einen meist ganzzahligen Ausgabewert („Hash“) in einem gegebenen Wertebereich auf eine regellos erscheinende Weise. Kryptologisch bzw. kryptografisch ist die Funktion, wenn sie außerdem folgende Eigenschaften hat:[1]
- Sie kann jede beliebige Bit- oder Bytefolge verarbeiten und erzeugt daraus einen Hash von fixer Länge.
- Sie ist stark kollisionsresistent: Es ist praktisch nicht möglich, zwei unterschiedliche Eingabewerte zu finden, die einen identischen Hash ergeben.
- Sie ist eine Einwegfunktion: Es ist praktisch nicht möglich, aus dem Hash den Eingabewert zu rekonstruieren.
Solche Hashfunktionen werden vor allem zur Integritätsprüfung von Dateien oder Nachrichten eingesetzt. Dafür wird die Funktion auf die zu prüfende Datei angewendet und mit einem bekannten früheren Hash verglichen. Weicht der neue Hash davon ab, wurde die Datei verändert.[2] Weiter dienen kryptografische Hashfunktionen zur sicheren Speicherung von Passwörtern und digitalen Signaturen. Wenn ein System ein Passwort oder eine Signatur prüft, vergleicht es dessen bzw. deren Hash mit einem gespeicherten Hash. Stimmen beide Werte überein, ist das Passwort bzw. die Signatur richtig. So kann vermieden werden, das Passwort oder die Signatur jemals im Klartext abzuspeichern, was sie verwundbar machen würde.[3] Außerdem können kryptografische Hashfunktionen als Pseudo-Zufallszahlengeneratoren und zur Konstruktion von Blockchiffren eingesetzt werden.
Es gibt viele kryptografische Hashfunktionen. Viele davon gelten nicht mehr als sicher, weil kryptanalytische Angriffe gegen sie bekannt sind. Zu den in der Praxis oft verwendeten Funktionen, die noch als sicher gelten, gehören die Algorithmenfamilien SHA-2 und SHA-3.
Klassifizierung
Eine Hashfunktion ist eine Abbildung, die effizient eine Zeichenfolge beliebiger Länge (Eingabewert) auf eine Zeichenfolge mit fester Länge (Hashwert) abbildet.[4] Daraus ergibt sich notwendigerweise, dass verschiedenen Eingabewerten derselbe Hashwert zugeordnet wird, die Abbildung ist also nicht injektiv. Es ist also grundsätzlich möglich, zwei Eingabewerte zu finden, die denselben Hashwert ergeben.
Kryptologische Hashfunktionen werden in schlüssellose und schlüsselabhängige eingeteilt: Eine schlüssellose Hashfunktion hat nur einen Eingabewert, während eine schlüsselabhängige Hashfunktion einen geheimen Schlüssel als zweiten Eingabewert benötigt.[4]
Die schlüssellosen Hashfunktionen werden ferner unterteilt in Einweg-Hashfunktionen (englisch One-Way Hash Function, kurz OWHF) und kollisionsresistente Hashfunktionen (englisch Collision Resistant Hash Function, kurz CRHF).
Eine Einweg-Hashfunktion erfüllt folgende Bedingungen:
- Einwegfunktion (englisch: preimage resistance): Es ist praktisch unmöglich, zu einem gegebenen Ausgabewert einen Eingabewert zu finden, den die Hashfunktion auf abbildet: .
- Schwache Kollisionsresistenz (englisch: weak collision resistance oder auch 2nd-preimage resistance): Es ist praktisch unmöglich, für einen gegebenen Wert einen davon verschiedenen Wert zu finden, der denselben Hashwert ergibt: .





Für eine kollisionsresistente Hashfunktion gilt zusätzlich:
- Starke Kollisionsresistenz (englisch: collision resistance): Es ist praktisch unmöglich, zwei verschiedene Eingabewerte und zu finden, die denselben Hashwert ergeben. Der Unterschied zur schwachen Kollisionsresistenz besteht darin, dass hier beide Eingabewerte und frei gewählt werden dürfen.
Man kann zusätzlich eine Resistenz gegen Beinahe-Kollision fordern (englisch: near-collision resistance). Hierbei soll es praktisch unmöglich sein, zwei verschiedene Eingabewerte und zu finden, deren Hashwerte und sich nur in wenigen Bits unterscheiden.


Zu den schlüsselabhängigen Hashfunktionen zählen Message Authentication Codes (MAC). Zu diesen zählen Konstrukte wie HMAC, CBC-MAC oder UMAC.
Konstruktion
Die meisten kryptographischen Hashfunktionen teilen die zu hashende Nachricht in Abschnitte gleicher Länge , die nacheinander in einen Datenblock der Länge eingearbeitet werden. Die Nachricht wird ggfs. auf ein Vielfaches von verlängert, wobei oft auch eine Kodierung der Länge der Ausgangsnachricht angefügt wird. Es gibt eine Verkettungsfunktion, die einen Nachrichtenabschnitt und den aktuellen Wert des Datenblocks als Eingabe erhält und den nächsten Wert des Datenblocks berechnet. Manche Hashalgorithmen sehen noch weitere Eingaben in die Verkettungsfunktion vor, zum Beispiel die Zahl der bis dahin verarbeiteten Nachrichtenblöcke oder -bits, siehe etwa das HAIFA-Verfahren. Die Größe des Datenblocks beträgt typischerweise 128 bis 512 Bit, teils auch mehr (bei SHA-3 z. B. 1600 Bit.). Nach Verarbeitung des letzten Nachrichtenabschnitts wird der Hashwert dem Datenblock entnommen, teils wird zuvor noch eine Finalisierungsfunktion darauf angewandt.


Die Verkettungsfunktion folgt für die Abbildung eines Nachrichtenabschnitts auf die Ausgabe den Prinzipien der Konfusion und der Diffusion, um zu erreichen, dass man nicht durch gezielte Konstruktion der eingegebenen Nachrichtenabschnitte zwei verschiedene Nachrichten erzeugen kann, die den gleichen Hashwert ergeben (Kollisionssicherheit).
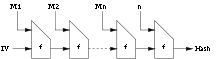
Die meisten Hashfunktionen, die vor 2010 entwickelt wurden, folgen der Merkle-Damgård-Konstruktion. Im Zuge des SHA-3-Wettbewerbs wurde diese Konstruktion durch verschiedene weitere Methoden ergänzt oder modifiziert.
Merkle-Damgård-Verfahren
In der Merkle-Damgård-Konstruktion wird eine Kompressionsfunktion als Verkettungsfunktion genutzt, die kollisionssicher ist, d. h. es ist schwer, verschiedene Eingaben zu finden, die die gleiche Ausgabe liefern. Daraus ergibt sich auch die Eigenschaft einer Einwegfunktion, d. h. man kann nur schwer zu einer gegebenen Ausgabe einen passenden Eingabewert finden. Die Kompressionsfunktion kann auf verschiedene Arten dargestellt werden, oft wird sie aus einer Blockchiffre konstruiert.
Bei der Merkle-Damgård-Konstruktion wird die eingegebene Nachricht zuerst erweitert und dabei auch eine Kodierung der Nachrichtenlänge angefügt. Dann wird sie in Blöcke bis der Länge geteilt. Die Kompressionsfunktion erhält einen Nachrichtenblock und den Verkettungsblock als Eingabe und gibt den nächsten Verkettungsblock aus. IV bezeichnet einen konstanten Startwert für den Verkettungsblock (initial value). Der Hashwert der gesamten Nachricht ist der Hashwert des letzten Blocks:





Blockchiffre-basierte Kompressionsfunktionen
Die Kompressionsfunktion wird aus einer Blockverschlüsselung konstruiert. soll die Verschlüsselung von mit der Blockchiffre unter dem Schlüssel bezeichnen. steht für das bitweise XOR. Wie oben sind die Nachrichtenblöcke und die Werte des Verkettungsblocks. Einige verbreitete Kompressionsfunktionen sind:







Davies-Meyer (wird unter anderem in MD4, MD5 und SHA verwendet) verschlüsselt den Verkettungsblock mit dem Nachrichtenabschnitt als Schlüssel, der Schlüsseltext wird dann noch mit dem Verkettungsblock verknüpft, typisch per XOR:
- .

Matyas-Meyer-Oseas verschlüsselt umgekehrt den Nachrichtenabschnitt mit dem Verkettungsblock. Dabei dient die Funktion zur Anpassung der Blockgrößen und ist häufig die Identität:

- .

Miyaguchi-Preneel ist sehr ähnlich wie Matyas-Meyer-Oseas:
- .

Hirose nutzt einen Verkettungsblock von der doppelten Breite eines Klar- bzw. Schlüsseltextblocks der Blockchiffre. bezeichnet die Hälften des Verkettungsblocks. Hier ist eine fixpunktfreie Funktion, die simpel gehalten werden kann (es genügt z. B. nur ein Bit zu invertieren), und bezeichnet die Konkatenation, d. h. das Aneinanderfügen zweier Bitblöcke:


- ,
- .


Die Hashfunktion MDC-2 beruht im Wesentlichen auf der zweifachen Anwendung der Matyas-Meyer-Oseas-Konstruktion. bzw. bezeichnen die linke bzw. rechte Hälfte eines Datenblocks (und damit ein Viertel eines Verkettungsblocks):



- ,
- .


Kompressionsfunktionen, die auf algebraischen Strukturen basieren
Um die Sicherheit der Kompressionsfunktion auf ein schwieriges Problem reduzieren zu können, wird deren Operation in entsprechenden algebraischen Strukturen definiert. Der Preis für die beweisbare Sicherheit ist ein Verlust an Geschwindigkeit. MASH (Modular Arithmetic Secure Hash) verwendet einen RSA-ähnlichen Modulus , mit und Primzahlen. Die Kompressionsfunktion ist im Kern: , wobei A für eine Konstante und für bitweises inklusives Oder steht.





Sponge-Verfahren
Sponge-Konstruktionen haben grundsätzlich andere Eigenschaften als Merkle-Damgård-Konstruktionen. Der bekannteste Vertreter dieser Klasse ist SHA-3.
Angriffe
Angriffe gegen Hashfunktionen können allgemeiner Art sein, und nur von der Bit-Länge des Hashwerts abhängen und den Hash-Algorithmus als Black-Box behandeln. Sie können sich andererseits gegen die Kompressionsfunktion richten. Bei Hashfunktionen, die auf einem Block-Chiffre basieren, kann ein Angriff gegen die zugrundeliegende Block-Chiffrierung erfolgen. Überdies sind Angriffe auf die Implementierung des Hash-Algorithmus möglich.
Black-Box-Angriffe
Black-Box-Angriffe sind Angriffe auf Hashfunktionen, bei denen über die eigentliche Funktionsweise der Hashfunktion nichts bekannt ist. Lediglich die Länge des Hashwerts wird als bekannt vorausgesetzt und man nimmt an, dass die Hashwerte gleichverteilt sind.
- Raten (englisch: 2nd preimage): Der Angreifer wählt zufällig eine Nachricht und vergleicht deren Hashwert mit dem einer gegebenen Nachricht. Die Erfolgsrate bei diesem Vorgehen liegt bei für einen Bit langen Hashwert.
- Kollisionsangriff: Der Angreifer erzeugt viele Variationen einer echten Nachricht und viele Variationen einer gefälschten Nachricht. Anschließend vergleicht er die beiden Mengen und sucht nach zwei Nachrichten, und , die den gleichen Hashwert haben. Eine Kollision ist nach Versuchen zu erwarten.




Angriffe auf die Kompressionsfunktion
- Meet-in-the-Middle
- Der Angreifer erzeugt Variationen der ersten Hälfte einer gefälschten Nachricht und Variationen der zweiten Hälfte. Er berechnet die Hashwerte vorwärts beim Startwert IV beginnend und rückwärts vom Hash-Resultat aus und versucht eine Kollision am Angriffspunkt zu finden. Das heißt, er muss die Kompressionsfunktion effizient invertieren können: gegeben ein Paar finden, so dass gilt .
- Correcting Block Attack
- Der Angreifer ersetzt alle Blöcke einer Nachricht bis auf einen – etwa den ersten. Anschließend legt er diese Variable so fest, dass sie im Laufe der Verkettung den gewünschten Gesamt-Hashwert liefert.
- Fixed Point Attack
- Der Angreifer sucht nach einem und , so dass . In diesem Fall kann er an diesem Punkt Nachrichtenblöcke einfügen, ohne den Hashwert zu ändern.
- Differenzielle Kryptanalyse
- Differenzielle Kryptanalyse ist ein Angriff auf Blockchiffriersysteme, die auf Hashfunktionen übertragen werden kann. Hierbei werden Eingabedifferenzen und die korrespondierenden Ausgabedifferenzen untersucht. Eine Differenz von Null entspricht dann einer Kollision.
- Boomerang Attack
- Der Boomerang-Angriff ist eine Erweiterung der differenziellen Kryptanalyse. Er verbindet zwei unabhängige Differentialpfade zu einem Angriff.[5]
- Rebound Attack
- Die innere Struktur einer Hashfunktion wird als dreiteilig betrachtet, mit E=E(bw)·E(in)·E(iw). Die Inboundphase ist ein Meet-in-the-Middle-Angriff, dem vorwärts wie rückwärts eine differenzielle Kryptanalyse folgt.[6]
- Herding
- Hierbei bildet der Angreifer aus zahlreichen Zwischenwerten eine Struktur (sog. Diamond Structure). Von jedem der Zwischenwerte ausgehend kann eine Nachricht erstellt werden, die denselben Hashwert H ergibt. Bei einer gegebenen Nachricht P (preimage) sucht der Angreifer einen einzelnen Block, der an P angehängt einen der gespeicherten Zwischenwerte in der Struktur ergibt. Dann erzeugt der Angreifer eine Folge von Nachrichtenblöcken, die diesen Zwischenwert mit H verbinden.[7]






Angriffe auf die Blockchiffrierung
Schwachstellen eines Blockchiffrierverfahrens, die, solange das Verfahren zur Verschlüsselung verwendet wird, eigentlich irrelevant sind, können bedeutende Auswirkungen haben, wenn es zur Konstruktion eines Hash-Verfahrens herangezogen wird. Diese wären z. B. schwache Schlüssel oder eine Komplementäreigenschaft.
Übersicht von Hashfunktionen
- Snefru
- wurde 1990 von Ralph Merkle entworfen. Der Kern der Hashfunktion ist ähnlich dem Blockchiffriersystem Khafre (Merkle). Snefru gilt als unsicher.
- N-Hash
- wurde 1990 bei Nippon Telephone and Telegraph entwickelt. Der Algorithmus ähnelt dem Blockchiffriersystem FEAL (Nippon T&T). N-Hash gilt als unsicher.[8]
- FFT-Hash
- ist eine Hashfunktion auf der Basis der Fast-Fourier-Transformation. Sie wurde von Schnorr 1991 erstmals vorgestellt, aber bald geknackt.[9] Später folgte eine zweite Version.[10] Sie gilt als unsicher.
- MD4
- wurde 1990 von Ronald Rivest entwickelt.[11] Sie erzeugt nach drei Runden einen 128 Bit langen Hashwert. Zu Beginn wird die Länge der Nachricht auf ein ganzzahliges Vielfaches von 512 Bit gebracht. Dazu wird sie mit einer „1“ und entsprechend vielen „0“ aufgefüllt, so dass ist. Ihr wird die Länge der ursprünglichen Nachricht in 64-Bit-Darstellung angehängt. Als Nächstes wird der Puffer initialisiert. Die Hauptschleife besteht aus drei Runden mit je 16 Schritten. Jede Runde erhält als Eingabe einen 512 Bit langen Nachrichtenblock und den 128 Bit langen Pufferinhalt. Jede Runde benutzt 16-mal eine nichtlineare Rundenfunktion. Der ausgegebene Hashwert ist die Konkatenation (Verkettung) der letzten 32-Bit-Worte im Puffer.[12] MD4 gilt als unsicher.
- MD5
- 1991 veröffentlichte Rivest ein verbessertes Hash-Verfahren, noch bevor eine ernsthafte Schwäche von MD4 aufgedeckt wurde.
Die wesentlichen Veränderungen sind: MD5 hat eine vierte Runde. Die vierte Runde hat eine neue Rundenfunktion; die der zweiten Runde wurde durch eine neue Funktion ersetzt. Die additiven Konstanten wurden neu definiert.
Der erste partielle Angriff auf MD5 von 1993 fand Pseudokollisionen, d. h., es können zu einem Nachrichtenblock zwei sich in nur wenigen Bits voneinander unterscheidende Verkettungsvariablen V1 und V2 gefunden werden, die denselben Output ergeben.[13] Der Angriff hatte allerdings keine schwerwiegenden Konsequenzen. Ein neuer effizienter Angriff erfolgte 2005.[14] Hierbei suchten die Autoren nach einem Nachrichtenpaar mit je zwei Blöcken, die nach Verarbeitung des zweiten Blocks eine Kollision erzeugen. MD5 gilt als unsicher. - SHA
- Das NIST schlug 1993 den Secure Hash Algorithm (SHA) vor. Zwei Jahre später wurde er durch SHA-1 ersetzt. SHA-1 unterscheidet sich von seinem Vorgänger nur durch eine zusätzliche 1-Bit-Rotation.
Die Nachricht wird wie bei MD4 aufgefüllt. Der Puffer wird mit fünf Konstanten initialisiert. Die Hauptschleife besteht aus vier Runden mit je 20 Schritten.
1998 wurde eine differentielle Analyse gegen SHA-0 und SHA-1 durchgeführt.[15]
2002 wurden vom NIST drei weitere Varianten des Algorithmus veröffentlicht, die größere Hashwerte erzeugen. Es handelt sich dabei um SHA-256, SHA-384 und SHA-512, wobei die angefügte Zahl jeweils die Länge des Hashwerts in Bit angibt.
2004 wurde ein verbesserter Angriff auf SHA-0 beschrieben.[16] Hier fanden die Autoren Beinahe-Kollisionen, sowie Kollisionen für eine auf 65 Runden reduzierte Version von SHA. Ein Jahr später berichten dieselben Autoren von einem Angriff auf die volle Rundenzahl von SHA-0 mit einer Komplexität von 251.[17] Im selben Jahr gelang ein verbesserter Angriff gegen SHA-0 mit einer Komplexität von 239 Hash-Operationen[18] und gegen SHA-1 mit einer Komplexität von 269.[19] Im Februar 2017 wurde die erste Kollision für SHA-1 veröffentlicht.[20] - RIPEMD
- RIPE-MD wurde 1992 im Rahmen des Projekts RACE Integrity Primitives Evaluation (RIPE) der Europäischen Union entwickelt. 1996 wurde die ursprüngliche Hashwert-Länge von 128 auf 160 Bits erweitert.[21] Außerdem wurden die Varianten RIPEMD-256 und RIPEMD-320 eingeführt.
Die Nachricht wird wie bei MD4 aufgefüllt. Der Puffer wird mit fünf Konstanten initialisiert. Die Hauptschleife besteht aus fünf Runden mit je 16 Schritten. Der Algorithmus läuft in zwei Ausführungen parallel. Nach jedem Block werden die beiden Ausgabewerte beider Linien zu den Verkettungsvariablen addiert.
Im ursprünglichen RIPEMD konnten mit einer Komplexität von Kollisionen gefunden werden,[22] so dass es nicht verwendet werden sollte. - HAVAL
- wurde 1992 vorgestellt und gehört ebenfalls zur MD4-Familie. Die Nachrichten werden in 1024 Bit langen Blöcken verarbeitet. Der Hashwert kann 128, 160, 192, 224 oder 256 Bit lang sein. Auch die Rundenzahl kann von drei bis fünf variieren. Jede Runde besteht aus 16 Schritten.[23]
2003 konnten für HAVAL mit drei Runden Kollisionen gefunden werden. Der Angriff gelingt gegen alle möglichen Ausgabelängen. Die Komplexität entspricht dabei 229 Rechenschritten der Kompressionsfunktion. HAVAL sollte deswegen nicht für Applikationen verwendet werden, die Kollisionsresistenz erfordern.[24] - Tiger
- wurde 1996 von Anderson und Biham entwickelt. Nachrichtenpadding ist wie bei MD4, d. h., der Nachricht wird eine „1“ plus eine Folge von „0“ sowie die Nachrichtenlänge als ein 63-Bit-Wort angehängt. Das Resultat wird in 512 Bit lange Blöcke geteilt. Der Hashwert enthält 192 Bits. Aus Gründen der Kompatibilität sind TIGER/128 oder TIGER/160 definiert, die die ersten 128 bzw. 160 Bits von TIGER/192 verwenden.[25]
- PANAMA
- ist von Daemen und Clapp und stammt von 1998.[26] Es verarbeitet Nachrichtenblöcke mit 256 Bit Länge und gibt einen Hashwert mit 256 Bit aus. Der Puffer ist ein lineares Schieberegister mit 32 Zuständen mit je acht Worten.
Einer der Autoren konnte Kollisionen in nur 26 Auswertungen der Update-Funktion erzeugen, so dass Panama nicht als kollisionsresistent gelten kann.[27] - Whirlpool
- wurde von Rijmen und Barreto entworfen. Es beruht auf dem Miyaguchi-Preneel-Schema.
Die Nachricht wird wie bei MD4 aufgefüllt. Die aufgefüllte Nachricht wird in 512 Bit lange Blöcke geteilt. Der Hashwert ist 512 Bit lang. Whirlpool verwendet als Funktion eine AES-Variante in 10 Runden.[28] - SMASH
- wurde 2005 von Knudsen entwickelt. Nach dem Nachrichtenpadding zu Beginn wird die Nachricht wahlweise in 256 bzw. 512 Bit langen Blöcken verarbeitet und liefert einen 256 bzw. 512 Bit langen Hashwert. Die Hauptrunde besteht aus mehreren Runden, die H-Runden und L-Runden genannt werden. Drei verschiedene H-Runden sind definiert. Jede H-Runde enthält eine eigene S-Box (Substitutionstabelle), die an die des Blockchiffrierverfahrens Serpent angelehnt ist. In der L-Runde werden Links- oder Rechtsverschiebungen durchgeführt.[29]
SMASH wurde bald erfolgreich angegriffen und gilt als unsicher.[30] - FORK-256
- wurde beim Cryptographic Hash Workshop von Hong et al. vorgestellt.[31] Es verarbeitet 512 Bit lange Nachrichtenblöcke, unterteilt in 16 Worte und liefert einen 256 Bit langen Hashwert. Die Hauptschleife besteht aus vier Verzweigungen und acht Schritten je Zweig. FORK-256 gilt als unsicher.
- SHA-3 (Keccak)
- Das Design-Prinzip von SHA-3 unterscheidet sich von den Hash-Funktionen der MD-Gruppe einschließlich SHA-2. Es ist eine sog. sponge construction (Schwamm-Konstruktion). Die Sponge-Construction ist eine iterative Funktion, bei der der State (Anzahl Bits im internen Zustand) größer ist als das Output (Ausgabebits). Damit sollen generische Angriffe wie etwa eine Kollision mit Komplexität unter abgewehrt werden.
- BLAKE
- 2008 von Jean-Philippe Aumasson, Luca Henzen, Willi Meier und Raphael C.-W. Phan entwickelt; war einer der Finalisten im SHA-3-Auswahlverfahren.



Siehe auch
Literatur
- Alfred J. Menezes, Paul C. van Oorschot, Scott A. Vanstone: Handbook of Applied Cryptography. CRC Press, 1996, S. 321–384.
- Bart Preneel: Cryptographic Primitives for Information Authentication – State of the Art. State of the Art in Applied Cryptography, LNCS 1528. Springer-Verlag, 1998, S. 49–104.
- Douglas R. Stinson: Cryptography – Theory and Practice. Chapman&Hall / CRC, 2002, S. 117–154.
Weblinks
- Übersicht über Hash-Funktionen (englisch)
- NIST-Ausschreibung (englisch)
- Kandidaten der Hashfunktion-Ausschreibung (englisch)
- Keccak-Spezifikation
Einzelnachweise
- William Easttom: Modern Cryptography: Applied Mathematics for Encryption and Information Security. Springer International Publishing, Cham 2021, ISBN 978-3-03063114-7, S. 206, doi:10.1007/978-3-030-63115-4 (springer.com [abgerufen am 21. Juli 2021]).
- Easttom 2021, S. 207 f.
- Easttom 2021, S. 208 f.
- Alfred Menezes, Paul van Oorschot, Scott Vanstone: Handbook of Applied Cryptography. CRC Press, 1996, Kap. 9, S. 324 (uwaterloo.ca [PDF]).
- Antoine Joux, Thomas Peyrin: Hash Functions and the (Amplified) Boomerang Attack. Advances in Cryptology-CRYPTO2007, LNCS4622. Springer-Verlag, 2007, S. 244–263
- Florian Mendel, Christian Rechberger, Martin Schlaffer, Soren S. Thomsen: The Rebound Attack: Cryptanalysis of Reduced Whirlpool and Grostl. Fast Software Encryption, LNCS5665. Springer-Verlag, 2009, S. 260–276
- John Kelsey, Tadayoshi Kohno: Herding Hash Functions and the Nostradamus Attack. (iacr.org [PDF]).
- Bruce Schneier: Angewandte Kryptographie. Addison-Wesley, 1996, S. 491–524
- Serge Vaudenay: FFT-Hash is not yet Collision-free. Advances in Cryptology-CRYPTO 92, LNCS 740. Springer-Verlag, 1993, S. 587–593.
- Claus-Peter Schnorr, Serge Vaudenay: Parallel FFT-Hashing, Fast Software Encryption, LNCS 809. Springer-Verlag, 1994, S. 149–156.
- Ronald L. Rivest: The MD4 Message Digest Algorithm, Advances in Cryptology-CRYPTO 90, LNCS 537. Springer Verlag, 1991, S. 303–311.
- William Stallings: Cryptography and Network Security. Prentice Hall, 1999, S. 271–297.
- Bert den Boer, Antoon Bosselaers: Collisions for the Compression Function of MD5, Advances in Cryptology-EUROCRYPT 93, LNCS 765. Springer-Verlag, 1994, S. 293–304.
- Xiaoyun Wang, Hongbo Yu: How to Break MD5 and Other Hash Functions, Advances in Cryptology-EUROCRYPT 2005, LNCS 3496. Springer-Verlag, 2005, S. 19–35.
- Florent Chabaud, Antoine Joux: Differential Collisions in SHA-0, Advances in Cryptology-CRYPTO 98, LNCS 1462. Springer-Verlag, 1999, S. 56–71.
- Eli Biham, Rafi Chen: Near-Collisions of SHA-0, Advances in Cryptology-CRYPTO 2004, LNCS 3152. Springer-Verlag, 2005, S. 290–305.
- Eli Biham, Rafi Chen et al.: Collisions of SHA-0 and Reduced SHA-1, Advances in Cryptology-EUROCRYPTO 2005, LNCS 3494. Springer-Verlag, 2005, S. 526–541.
- Xiaoyun Wang, Hongbo Yu, Yiqun Lisa Yin: Efficient Collision Search Attacks on SHA-0, Advances in Cryptology-CRYPTO 2005, LNCS 3621. Springer-Verlag, 2006, S. 1–16.
- Xiaoyun Wang, Hongbo Yu, Yiqun Lisa Yin: Finding Collisions in the Full SHA-1, Advances in Cryptology-CRYPTO 2005, LNCS 3621. Springer-Verlag, 2006, S. 17–36.
- Marc Stevens, Elie Bursztein, Pierre Karpman, Ange Albertini, Yarik Markov. The first collision for full SHA-1
- Hans Dobbertin, A. Basselaers, Bart Preneel: RIPEMD-160:A Strengthened Version of RIPEMD, Fast Software Encryption, LNCS 1039. Springer-Verlag, 1996, S. 71–79.
- Xiaoyun Wang et al.: Cryptanalysis of the Hash Functions MD4 and RIPEMD, Advances in Cryptology-EUROCRYPT 2005, LNCS 3494. Springer-Verlag, 2005, S. 1–18.
- Yuliang Zheng, Josef Pieprzyk, Jennifer Seberry: HAVAL-A one-way hashing algorithm with variable length of output, AUSCRYPT 92, LNCS 718. Springer-Verlag, 1993, S. 83–104.
- Bart Van Rompay, Alex Biryukov, Bart Preneel, Joos Vandewalle: Cryptanalysis of 3-Pass HAVAL, Advances in Cryptology-ASIACRYPT 2003, LNCS 2894. Springer-Verlag, 2003, S. 228–245.
- Tiger: A Fast New Hash Function. (Designed in 1995)
- Joan Daemen, Craig Clapp: Fast Hashing and Stream Encryption with PANAMA, Fast Software Encryption, LNCS 1372. Springer-Verlag, 1998, S. 60–74.
- Joan Daemen, Gilles van Assche: Producing Collisions for PANAMA, Instantaneously, Fast Software Encryption, LNCS 4593. Springer-Verlag, 2007, S. 1–18.
- The WHIRLPOOL Hash Function (Memento vom 8. April 2006 im Internet Archive)
- Lars R. Knudsen: SMASH-A Cryptographic Hash Function, Fast Software Encryption, LNCS 3557. Springer-Verlag, 2005, S. 228–242.
- Norbert Pramstaller, Christian Rechberger, Vincent Rijmen: Smashing SMASH, Cryptology ePrint Archive Report 2005/081
- http://csrc.nist.gov/groups/ST/hash/first_workshop.html