Barabási-Albert-Modell
Das Barabási-Albert-Modell[1] (englisch Barabási–Albert (BA) model) beschreibt einen stochastischen Algorithmus aus dem Bereich der Graphentheorie zur Generierung ungerichteter skalenfreier Netzwerke. Das Modell wurde von Albert-László Barabási und seiner Doktorandin Réka Albert formuliert und seine wesentlichen Merkmale sind ein sukzessives Wachstum des Netzwerks, also das Hinzufügen von neuen Knoten im Laufe der Zeit, und deren Anbindung an das bestehende Netzwerk. Letzteres ist ein Zufallsprozess, der aber einer sogenannten bevorzugten Bindung (englisch preferential attachment) unterliegt. Die Auswahl der Nachbarn eines neuen Knotens wird mit höherer Wahrscheinlichkeit zugunsten von Knoten entschieden, die bereits einen hohen Grad aufweisen. In den so entstehenden Netzwerken kommen dementsprechend einige relativ bedeutende Knoten (englisch Hubs) vor, deren Grade signifikant höher sind als die der überwiegenden Mehrheit mit vergleichsweise kleinen Graden. Man spricht dann von einem skalenfreien Netzwerk, da die Gradverteilung (englisch degree distribution) einem Potenzgesetz folgt; der Charakter eines solchen Netzwerks ist demnach unabhängig von seiner Größe. Es gilt als das bekannteste Modell zur Generierung von Netzwerken.[2]
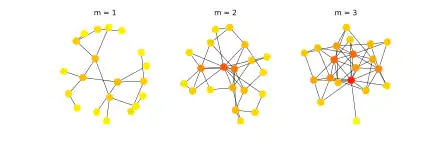

Konzept
Viele reale Netzwerke, wie beispielsweise das Internet, besitzen eine Gradverteilung mit schweren Rändern, was schon 1955 von Herbert A. Simon erkannt worden war.[3] Demzufolge ist die Gradverteilung sehr heterogen und es gibt mit hoher Wahrscheinlichkeit wenige extrem gut vernetzte Knoten, deren Grad signifikant höher ist als der Mittelwert. Dies ist auch in skalenfreien Netzwerken der Fall, ob aber die Gradverteilung aus empirischen Daten tatsächlich exakt einem Potenzgesetz unterliegt, ist relativ schwierig nachzuweisen.[4] Dennoch sind skalenfreie Netzwerke in mehreren Hinsichten empirischen Netzwerken sehr ähnlich, was zumindest anhand der Entstehungsmechanismen deutlich wird. So ist z. B. beim klassischen Zufallsgraph nach dem Modell von Paul Erdős und Alfréd Rényi (Erdős-Rényi-Modell)[5] die Anzahl der Knoten fix. Ein solcher ER-Zufallsgraph hat also eine finite, fest definierte Größe und diese ist zeitlich nicht variabel. Weil alle möglichen Kanten mit der gleichen Wahrscheinlichkeit realisiert werden, sind Knoten im Prinzip gleichwertig und ihr Grad streut relativ eng mit einer Poisson-Verteilung um den Mittelwert. Reale Netzwerke sind jedoch zeitlich variabel und weisen eindeutig eine hohe Varianz in ihrer Gradverteilung auf.[6] So kommen beispielsweise im World Wide Web ständig neue Seiten hinzu, die mit hoher Wahrscheinlichkeit mit bereits bestehenden, „wichtigen“ Seiten verlinkt werden. Die Bedeutung einer Seite kann dabei anhand der Anzahl ihrer Verlinkungen, also ihrem Grad, festgemacht werden (vgl. PageRank). Skalenfreie Netzwerke finden sich auch beim Web of Trust von Pretty Good Privacy.[7] Ebenso ist in einem Netzwerk aus wissenschaftlichen Publikationen (Knoten) und deren Referenzierung (Kanten) die Wahrscheinlichkeit höher, dass eine neue Publikation auf bereits bestehende, reputable bzw. vielbeachtete Veröffentlichungen verweist, als auf unbekannte.[8][9]
Das BA-Modell formuliert diese beiden Eigenschaften realer Netzwerke für die Entstehung ähnlicher Zufallsnetzwerke explizit. Die Kernelemente sind demnach:
- Wachstum: Das Netzwerk wächst in jedem Zeitschritt um einen Knoten an, welcher mit einer festen Anzahl bereits existierender Knoten verbunden wird.
- Bevorzugte Verbindung: Die Auswahl der neu verknüpften Verbindungen ist abhängig von der Wichtigkeit, bzw. ihrem Grad, der in Frage kommenden Knoten.
Mathematische Formulierung


Man beginne mit einem Netzwerk mit Knoten, wobei die Kanten willkürlich gewählt werden können, solange jeder Knoten mindestens einen Nachbar besitzt. In jedem Zeitschritt wird ein neuer Knoten hinzugefügt, der mit bereits vorhandenen Knoten verbunden wird. Die Wahrscheinlichkeit , mit der ein Knoten dafür ausgewählt wird, ist proportional zu dessen Grad . Formal lässt sich das schreiben als





- ,

wobei die Anzahl der aktuellen Knoten ist.

Damit ergibt sich die Netzwerkgröße mit und die Anzahl der Kanten als , wobei die anfängliche Kantenanzahl darstellt.



Probleme ergeben sich aufgrund der Tatsache, dass im originalen Modell nicht definiert ist, wie genau die anfänglichen Kanten verteilt sind und ob die neu hinzukommenden simultan oder sukzessiv verteilt werden. Ist die Vergabe der neuen Kanten unabhängig, ergibt sich die Möglichkeit mehrfach vergebener Kanten. Es bleibt dadurch ebenfalls unklar, ob Loops (Kanten deren zwei Endknoten ein und derselbe sind) erlaubt sind oder nicht. Eine mathematisch konkrete Definition, die diese Unklarheit beseitigt, wurde von Bollobás et al. unter dem Namen Linearized Chord Diagram (LCD) vorgeschlagen.[10]
Eigenschaften
Graddynamik
Da der Grad eines Knotens zeitabhängig ist, lohnt sich für das BA-Modell eine Betrachtung der Dynamik. Nimmt man approximativ an, dass , stellt das eine Art Erwartungswert dar (tatsächlich ist immer eine natürliche Zahl). Die Rate, mit der ein Knoten neue Kanten akkumuliert, ist damit

- .

Vereinfacht man für große Zeiten, ergibt sich nach Integration
- ,

wobei den Zeitpunkt darstellt, an dem Knoten hinzugefügt wird und .


Eine Konsequenz dieser Dynamik ist, dass die Konkurrenz um neue Kanten mit wachsender Netzwerkgröße stärker wird und somit die Rate der Akkumulation mit zunehmender Zeit kleiner. Zudem ergibt sich eine first-mover advantage, ältere Knoten bekommen also tendenziell mehr neue Kanten.
Gradverteilung
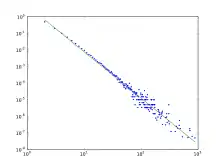

Die Gradverteilung eines mit dem BA-Modell generierten Netzwerkes folgt grob einem Potenzgesetz der Form
- .

Approximativ (besonders für große ) lässt sich das reduzieren auf

- .

Eine exakte Lösung liefert die LCD Methode mit
- .

In beiden Fällen wird der skaleninvariante Charakter des Modells erkennbar, da die Gradverteilung sowohl unabhängig von der Netzwerkgröße als auch vom Zeitpunkt ist.
Mittlerer Grad
Jeder Knoten hat einen mittleren Grad (durchschnittliche Anzahl Verbindungen zu anderen Knoten) von
- ,

wobei diese Aussage für einzelne, zufällig gewählte Knoten unbedeutend ist, da die Varianz für große Netzwerke unbeschränkt wächst.
Durchmesser
Der Durchmesser , also der längste der kürzesten Pfade zwischen allen Knoten, eines BA-Zufallsgraphen ist ungefähr

- .



Geschichte
Die ersten Beobachtungen von Verteilungen, die einem Potenzgesetz folgen, gehen auf den Ökonomen Herbert A. Simon zurück. Seine Arbeit aus dem Jahr 1955 bezog sich u. a. auf die Vermögensverteilung, allerdings nicht explizit auf Netzwerke. Er konnte zeigen, dass Gewinne bei Investitionen größer sind, je mehr ursprünglich investiert wurde: Das Prinzip the rich get richer führt also zu einer Vermögensverteilung in Form eines Potenzgesetzes.[3] Simon nannte diesen Mechanismus Yule process, da George Udny Yule ähnliche Untersuchungen schon mehrere Jahre zuvor angestellt hatte. In den 1970er Jahren wurde die Frage nach der konkreten Ursache von Derek de Solla Price erneut aufgeworfen. Er übernahm die von Simon erarbeiteten Mechanismen mit wenigen Änderungen, übertrug sie auf Netzwerke und nannte das Prinzip den kumulativen Vorteil (englisch cumulative advantage). Seine Arbeit bezog sich hauptsächlich auf ein Netzwerk aus wissenschaftlichen Publikationen und er entwickelte das Price-Modell (englisch Price's model), welches anhand relativ weniger Annahmen und einfacher Mechanismen deren tatsächliche Verteilung nachbilden kann.[2]
Barabási und Albert nannten denselben Effekt, den auch schon Simon und Price herausgearbeitet hatten, preferential attachment. Ihr Modell wurde in den 1990er Jahren unabhängig vom Price-Modell entwickelt und ist diesem zwar ähnlich, unterscheidet sich aber dennoch in einigen wesentlichen Merkmalen. So wächst bei beiden das Netzwerk im Entstehungsprozess, jedoch werden – anders als bei Price – beim BA-Modell jedem neuen Knoten eine feste Anzahl Kanten hinzugefügt. Der kleinstmögliche Grad entspricht also genau dieser Anzahl. Zudem werden Kanten beim BA-Modell als ungerichtet angesehen. Heute zählt das BA-Modell als das am besten bekannte Modell zur Generierung von Netzwerken.[2]
Literatur
- Albert-László Barabási: The Barabási-Albert Model. In: Network Science. Cambridge University Press, 2016, ISBN 978-1-107-07626-6, Kapitel 5, S. 1–45. (networksciencebook.com)
- Albert-László Barabási, Réka Albert: Emergence of Scaling in Random Networks. In: Science. Band 286, 1999, S. 509–512, doi:10.1126/science.286.5439.509. (barabasi.com)
- Steven H. Strogatz: Exploring complex networks. In: Nature. Band 410, 2001, S. 268–276, doi:10.1038/35065725. (math.wsu.edu)
Einzelnachweise
- André Krischke, Helge Röpcke: Graphen und Netzwerktheorie: Grundlagen – Methoden – Anwendungen. Carl Hanser, 2014, ISBN 978-3-446-44184-2, S. 174–181.
- Mark Newman: Networks. 2. Auflage. Oxford University Press, New York 2010, ISBN 978-0-19-920665-0.
- Herbert A. Simon: On a Class of Skew Distribution Functions. In: Biometrika. Band 42, Nummer 3, 1955, S. 425–440, doi:10.2307/2333389.
- A. Clauset, C. R. Shalizi, M. E. J. Newman: Power-Law Distributions in Empirical Data. In: SIAM Review. Band 51, Nummer 4, 2009, S. 661–703, doi:10.1137/070710111.
- Paul Erdős, Alfréd Rényi: On random graphs I. In: Publicationes Mathematicae. (Debrecen) 6, 1959, S. 290–297.
- Albert-László Barabási, Eric Bonabeau: Scale-Free Networks. In: Scientific American. Band 288, Nummer 5, 2003, S. 60–69, JSTOR 26060284.
- Oliver Richters, Tiago P. Peixoto: Trust Transitivity in Social Networks. In: PLOS ONE. 2011, doi:10.1371/journal.pone.0018384.
- Mingyang Wang, Guang Yu, Daren Yu: Measuring the preferential attachment mechanism in citation networks. In: Physica. A. Band 387, Nummer 18, 2008, S. 4692–4698, doi:10.1016/j.physa.2008.03.017.
- S. Redner: How popular is your paper? An empirical study of the citation distribution. In: The European Physical Journal. B. Band 4, Nummer 2, 1998, S. 131–134, doi:10.1007/s100510050359.
- B. Bollobás, O. Riordan, J. Spencer, G. Tusnády: The degree sequence of a scale-free random graph process. In: Random Structures and Algorithms. Band 18, 2001, S. 279–290, doi:10.1002/rsa.1009.