x87
x87 (auch numeric processor extension[1], NPX) bezeichnet eine Untermenge des Befehlssatzes der x86-Architektur für Gleitkommaberechnungen. Es ist die älteste Befehlssatzerweiterung für diese Architektur. Ihre Befehle sind nicht notwendig, um funktionierende Programme zu erzeugen, aber sie bieten Hardwareimplementierungen für häufige numerische Aufgaben, die damit wesentlich (10× bis 30×) schneller erledigt werden. Bevor die x87-Befehle von den Prozessoren verarbeitet werden konnten, mussten Compiler oder Programmierer langsame Software-Bibliotheksprozeduren aufrufen, um derartige Gleitkommaoperationen durchzuführen. Diese Vorgehensweise ist in vielen preiswerten eingebetteten Systemen noch immer häufig notwendig. Alternativ wird in Systemen, die keine Gleitkommaeinheit aufweisen, Festkommaarithmetik eingesetzt, da diese in Integer-Recheneinheiten effizient implementiert werden kann.
Bis zum Intel 80386 bzw. i486SX wurden die x87-Befehle durch einen separaten Koprozessor implementiert. Dieser Koprozessor musste gesondert erworben und in den dafür vorgesehenen Sockel auf der Hauptplatine eingesetzt werden. Gegenüber der Emulation durch Software war die Gleitkommarechnung auf einer 80x87-FPU 75- bis 100-mal schneller.[2]
In späteren x86-Prozessorgenerationen, aber schon ab dem (teureren) i486DX war der FPU-Teil meist schon im Hauptprozessor integriert. Der Begriff x87 wird aber immer noch verwendet, um die Untermenge des Befehlssatzes zu bezeichnen, die ursprünglich in den x87-Koprozessoren verarbeitet wurde. Seit der Einführung von SSE2 haben x87-Einheiten viel von ihrer früheren Bedeutung verloren. Für Berechnungen, die eine Mantisse von 64 Bit erfordern, wie sie mit den 80 Bit breiten x87-Registern möglich ist, sind sie aber weiterhin wichtig.
Implementierung
Die x87-Familie verwendet keine direkt adressierbaren Register wie die Hauptregister der x86-Prozessoren; stattdessen bilden die x87-Register einen acht Stufen tiefen Stack, der von st0 bis st7 läuft. Die x87-Befehle arbeiten, indem sie Werte auf den Stack legen, dort für Berechnungen verwenden und sie wieder herunternehmen. Der x87-Koprozessor funktioniert daher ähnlich wie Taschenrechner, die für umgekehrte polnische Notation ausgelegt sind. Zweistellige Operationen wie FADD, FSUB, FSUBR, FMUL, FDIV, FDIVR, FCOM, ... nutzen ST0 und ein anderes Register ST0...ST7 (Zählung relativ zur Stackspitze ST0) bzw. einen Speicheroperanden, führen die Operation aus und schreiben das Ergebnis nach ST0. Bei Registeroperationen ist als Ziel auch der zweite Operand möglich:
FADD ST0, f32[mem] Notation: FADD ST0, f64[mem] f32,f64:Gleitkommazahl FADD ST0, i16[mem] i16, i32: Ganzahl FADD ST0, i32[mem] (mit Anzahl der Bits) FADD ST0, STn [men]: Speicheradresse FADD STn, ST0 STn: n-tes Register im Stack FADDP STn, ST0
Für die nicht kommutativen Operationen FSUB und FDIV kann mit FSUBR und FDIVR auch die Reihenfolge der Operanden vertauscht werden.
ST0 kann daher als Akkumulator (ein Register, das sowohl Zielregister ist, als auch einen Operanden enthält) verwendet werden und es kann auch mit einem anderen Stackregister mit Hilfe des Befehls fxch st(x) getauscht werden. Der x87-Stack kann also als sieben frei adressierbare Register und als ein Akkumulator verwendet werden. Das ist besonders auf superskalaren x86-Prozessoren (wie den Pentiums ab 1993) nützlich, wo diese Exchange-Befehle so optimiert sind, dass sie nachfolgende FPU-Instruktionen nicht verzögern. Dazu wird für jeden fxch-Befehl nicht die FPU, welche die folgenden Gleitkommaoperationen behandelt, sondern ein anderes Rechenwerk benutzt.
Die im Pentium MMX eingeführte Erweiterung der x86-Architektur namens MMX verwendet die gleichen physischen Register wie die Gleitkommaeinheit. Dies vereinfachte die Markteinführung von MMX, da bei einem Taskwechsel keine zusätzlichen Register gesichert werden müssen und somit keine Anpassungen im Betriebssystem für MMX notwendig sind. Es ist Aufgabe des Anwendungsprogrammes, den Prozessor vom x87- in den MMX-Modus und wieder zurück zu schalten. Allerdings sind diese Moduswechsel vergleichsweise langsam, so dass Intel und AMD bei den späteren Befehlserweiterungen (SSE und Nachfolger) einen anderen Weg gingen.
IEEE-Kompatibilität
Die x87-Befehle sind kompatibel mit der Norm IEEE 754. Der Gleitkommaprozessor kann Gleitkommazahlen mit einfacher Genauigkeit (32 Bit, float oder real in den meisten Sprachen) doppelter Genauigkeit (64 Bit, double) oder vollen 80 Bit (long double oder extended) verarbeiten. Da die Prozessoren intern die vollen 80 Bit verwenden (um den Erhalt von Genauigkeit über viele Berechnungen zu ermöglichen), werden Rundungen jedoch nicht genau so durchgeführt, wie die strikten 32- und 64-Bit-Formate des IEEE 754 es verlangen, sofern nicht ein spezieller Rundungsmodus über ein Statusregister eingestellt ist. Eine Folge von arithmetischen Operationen kann sich daher leicht abweichend von strengen IEEE-754-Formaten verhalten.[3]
Unterschiede im Ergebnis einer Berechnungskette können sich auch allein durch die Aktivierung der Optimierung beim Kompilieren ergeben.[4] Eine optimierte Version eines Programms wird also ein (in der Regel geringfügig) anderes Ergebnis liefern als eine nicht optimierte Version, wie sie oft zum Debuggen verwendet wird.
x87-Koprozessoren von Intel
8087
Der 8087 war der erste mathematische Koprozessor für 16-Bit-Prozessoren von Intel (der 8231 war älter, aber für den 8-Bit-8080 entworfen); er wurde gebaut, um mit dem 8088 und dem 8086 zusammen verwendet zu werden.

80287
Der 80287 (i287) war der mathematische Koprozessor für die Intel-80286-Serie. Intel und seine Konkurrenten führten später den 80287XL ein, der eigentlich ein 80387SX mit einer zum 80287 kompatiblen Pinbelegung war. Der 80287XL enthielt einen 3:2-Taktmultiplizierer, damit Hauptplatinen, die den Koprozessor mit nur zwei Drittel des CPU-Takts betrieben, die Gleitkommaeinheit mit voller (= der gleichen wie die CPU) Geschwindigkeit betreiben konnten.
Der 80287 und 80287XL funktionierten auch mit dem 80386 und waren bis zur Einführung des 80387 1987 die einzigen für den 80386 erhältlichen Koprozessoren. Außerdem konnten sie auch mit dem Cyrix Cx486SLC eingesetzt werden. Jedoch wurde für beide Prozessoren aus Performancegründen und wegen der besseren Möglichkeiten des Befehlssatzes der 80387 bevorzugt.
Folgende Modelle des 80287 wurden hergestellt:
- i80287-3 (6 MHz)
- i80287-6 (6 MHz)
- i80287-8 (8 MHz)
- i80287-10 (10 MHz)
- i80287-12 (12,5 MHz)
- i80287XL (12,5 MHz, 387SX-Kern)
- i80287XLT (12,5 MHz, Laptop-Version)

80387
Der 80387 (387 oder i387) war der erste Intel-Koprozessor, der vollständig mit der IEEE-754-Norm kompatibel war. Bei seiner Einführung 1987, volle zwei Jahre nach dem 80386, war der i387 wesentlich schneller als der 80287 und enthielt deutlich verbesserte trigonometrische Funktionen. Funktionsumfang (FSIN, FCOS und FSINCOS kamen hinzu) sowie erlaubter Wertebereich (FPATAN: beliebige Argumente für arctan(a/b) statt |a| ≤ |b|, FPTAN: beliebige Argumente statt |x| ≤ π/4) wurden erweitert.
Der i387 wurde mit CMOS-III-Technologie in 1,5 µm gefertigt, seine Die-Größe betrug 7 mm × 7,5 mm.
Versionen
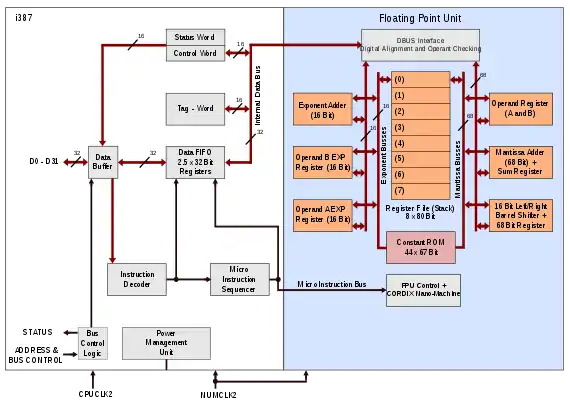
Vom i387 wurden später drei weitere Versionen hergestellt:
- i387DX
Der i387DX wurde 1989 eingeführt und war nur mit dem 386DX-Prozessor kompatibel. Er wurde mit CHMOS-IV-Technologie in 1,0 µm produziert, seine Die-Größe betrug 5,5 mm × 5,5 mm.
- i387SX
Der i387 war nur mit dem Standard-80386, der einen 32-Bit-Prozessorbus hatte, kompatibel. Der spätere, kostenreduzierte i386SX mit einem schmaleren 16-Bit-Datenbus konnte nicht mit dem 32-Bit-Bus des i387 zusammengeführt werden. Der i386SX erforderte daher eine eigene Variante des Koprozessors, den i387SX, der mit dem schmaleren Bus des SX kompatibel war.
Wie der i387DX wurde auch der i387SX mit CHMOS-IV-Technologie in 1,0 µm gefertigt.
- i387SL Mobile
Diese speziell für i386SL-Prozessoren gedachte und ebenfalls mit CHMOS-IV-Technologie produzierte Variante wurde 1992 auf den Markt gebracht und verfügt wie der i386SL über ein integriertes Power-Management.
Der i387DX und der i387SX konnten mit einem zum Systemtakt asynchronen Takt (×0,8 bis ×1,25) betrieben werden.
80487
Der i487 ist ein FPU-Koprozessor für den i486SX. Er war grundsätzlich ein vollständiger i486DX-Chip. Wurde er in einem i486SX-System eingebaut, schaltete der i487 den Hauptprozessor aus und übernahm sämtliche CPU-Operationen. Theoretisch konnte ein solcher Computer auch dann arbeiten, wenn der eigentliche i486SX-Prozessor entfernt worden wäre. In der Praxis verhinderte ein Pin auf dem i487 jedoch die Benutzung als vollwertigen i486.
 8087-Koprozessor
8087-Koprozessor Variante des 80287-Koprozessor
Variante des 80287-Koprozessor i387-Koprozessor
i387-Koprozessor 487SX-Koprozessor, der letzte seiner Art
487SX-Koprozessor, der letzte seiner Art
Siehe auch
Literatur
- Intel Corporation: IA-32 Intel Architecture Software Developer's Manual Volume 1: Basic Architecture, order number 253665-017.
- Intel Corporation: IA-32 Intel Architecture Software Developer's Manual Volume 2A: Instruction Set Reference A–M (PDF; 2,3 MB), order number 253666-017.
- Intel Corporation: IA-32 Intel Architecture Software Developer's Manual Volume 2B: Instruction Set Reference N-Z (PDF; 1,9 MB), order number 253667-017.
- Christian Reinsch: Der Arithmetik-Prozessor INTEL 8087: eine komplette Implementierung des vorgeschlagenen IEEE-Standards für Gleitpunktarithmetik, „Elektronische Rechenanlagen“, 23 (1981), Heft 4, S. 173–178 (doi:10.1524/itit.1981.23.16.173).
Weblinks
Einzelnachweise
- 8087 Math Coprocessor. (PDF) Intel, Oktober 1989, S. 3, abgerufen am 4. Oktober 2018 (englisch).
- STEVE FARRER: High Speed Numerics with the 80186/80188 and 8087. Hrsg.: Intel Corporation. APPLICATION NOTE 258, 1986 (intel.com [PDF; 270 kB]).
- David Monniaux, The pitfalls of verifying floating-point computations, to appear in ACM TOPLAS
- http://gcc.gnu.org/bugzilla/show_bug.cgi?id=323