Rangkorrelationskoeffizient
Ein Rangkorrelationskoeffizient ist ein parameterfreies Maß für Korrelationen, das heißt, er misst, wie gut eine beliebige monotone Funktion den Zusammenhang zwischen zwei Variablen beschreiben kann, ohne irgendwelche Annahmen über die Wahrscheinlichkeitsverteilung der Variablen zu machen. Die namensgebende Eigenschaft dieser Maßzahlen ist es, dass sie nur den Rang der beobachteten Werte berücksichtigen, also nur ihre Position in einer geordneten Liste.
Anders als der Pearson’sche Korrelationskoeffizient benötigen Rangkorrelationskoeffizienten nicht die Annahme, dass die Beziehung zwischen den Variablen linear ist. Sie sind robust gegenüber Ausreißern.
Es gibt zwei bekannte Rangkorrelationskoeffizienten: den Spearman’schen Rangkorrelationskoeffizienten (Spearman’sches Rho) und den Kendall’schen Rangkorrelationskoeffizienten (Kendall’sches Tau). Zur Ermittlung der Übereinstimmung zwischen mehreren Beobachtern (Interrater-Reliabilität) auf Ordinalskalenniveau wird dagegen auf den mit den Rangkorrelationskoeffizienten verwandten Konkordanzkoeffizienten W, auch Kendall’scher Konkordanzkoeffizient, nach dem Statistiker Maurice George Kendall (1907–1983), zurückgegriffen.
Konzept
Wir beginnen mit Paaren von Messungen . Das Konzept der nichtparametrischen Korrelation besteht darin, den Wert einer jeden Messung durch den Rang relativ zu allen anderen in der Messung zu ersetzen, also . Nach dieser Operation stammen die Werte von einer wohlbekannten Verteilung, nämlich einer Gleichverteilung von Zahlen zwischen 1 und . Falls die alle unterschiedlich sind, kommt jede Zahl genau einmal vor. Falls manche identische Werte haben, wird ihnen der Mittelwert der Ränge zugewiesen, die sie erhalten hätten, wenn sie leicht unterschiedlich gewesen wären. In diesem Fall wird von Bindungen oder Ties gesprochen.[1] Dieser gemittelte Rang ist manchmal eine ganze Zahl, manchmal ein „halber“ Rang. In allen Fällen ist die Summe aller zugewiesenen Ränge gleich der Summe aller Zahlen von 1 bis , nämlich .






Anschließend wird genau dieselbe Prozedur mit den durchgeführt und jeder Wert durch seinen Rang unter allen ersetzt.


Durch das Ersetzen intervallskalierter Messwerte durch die entsprechenden Ränge geht Information verloren. Die Anwendung bei intervallskalierten Daten kann aber dennoch sinnvoll sein, da eine nichtparametrische Korrelation robuster ist als die lineare Korrelation, widerstandsfähiger gegen ungeplante Fehler und Ausreißerwerte in den Daten, genau wie der Median robuster ist als der Mittelwert. Liegen als Daten nur Rangreihen, also Daten auf Ordinalniveau vor, gibt es zudem keine Alternative zu Rangkorrelationen.
Spearman’scher Rangkorrelationskoeffizient
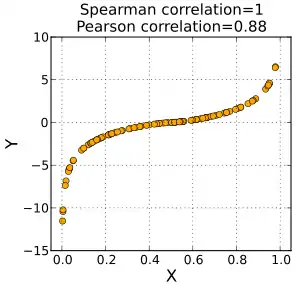
Der Spearman’sche Rangkorrelationskoeffizient ist benannt nach Charles Spearman und wird oft mit dem griechischen Buchstaben ρ (rho) oder – in Abgrenzung zum Pearson’schen Produkt-Moment-Korrelationskoeffizienten – als bezeichnet.

Definition
Gegeben sei ein Zufallsvektor mit den stetigen Randverteilungsfunktionen . Definiere den Zufallsvektor . Dann ist der Spearmansche Rangkorrelationskoeffizient für den Zufallsvektor gegeben durch:





Dabei handelt es sich bei um den gewöhnlichen Pearson'schen Korrelationskoeffizienten.

Man beachte, dass der Wert von unabhängig von den konkreten (Rand-)Verteilungsfunktionen ist. Tatsächlich hängt der stochastische Rangkorrelationskoeffizient nur von der Copula ab, die dem Zufallsvektor zugrunde liegt. Ein weiterer Vorteil im Vergleich zum Pearson’schen Korrelationskoeffizient ist die Tatsache, dass immer existiert, da die quadratisch integrierbar sind.


Unabhängigkeit von den Randverteilungen
Dass der Spearman’scher Rangkorrelationskoeffizient nicht von den Randverteilungen des Zufallsvektors beeinflusst wird, lässt sich wie folgt illustrieren: Gemäß dem Satz von Sklar existiert für den Zufallsvektor mit der gemeinsamen Verteilungsfunktion und den stetigen univariaten Randverteilungsfunktionen eine eindeutige Copula , so dass gilt:


- .

Nun wird der Zufallsvektor auf den Zufallsvektor transformiert. Da Copulas invariant unter strikt monoton steigenden Transformation sind, und wegen der Stetigkeit von hat dieselbe Copula wie . Darüber hinaus sind die Randverteilungen von uniform verteilt, da


für alle und .


Aus diesen beiden Beobachtungen folgt, dass zwar von der Copula von abhängt, aber nicht von seinen Randverteilungen.
Empirischer Spearman’scher Rangkorrelationskoeffizient
Im Prinzip ist ein Spezialfall des Pearson’schen Produkt-Moment-Korrelationskoeffizienten, bei dem die Daten in Ränge konvertiert werden, bevor der Korrelationskoeffizient berechnet wird:

Dabei ist
- der Rang von ,
- der Mittelwert der Ränge von ,
- die Standardabweichung der Ränge von und
- die Stichprobenkovarianz von und .







In der Praxis wird meistens eine einfachere Formel zur Berechnung von benutzt, die aber nur korrekt ist, wenn alle Ränge genau einmal vorkommen. Es liegen für zwei metrische Merkmale und die verbundenen Stichproben bzw. vor. Durch Rangskalierung der - bzw. -Werte ergeben sich die (verbundenen) Rangreihen bzw. . Wenn die - und -Reihe so verbunden sind, dass jeweils die kleinsten Werte, die zweitkleinsten Werte usw. miteinander korrespondieren, dann gilt , d. h., die beiden Rangreihen sind identisch. Stellt man nun die Rangzahlenpaare in der -Ebene als Punkte dar, indem man horizontal und vertikal aufträgt, so liegen die Punkte auf einer Geraden mit der Steigung . In diesem Fall spricht von einer perfekten positiven Rangkorrelation, der der maximale Korrelationswert zugeordnet ist. Um die Abweichung von der perfekten positiven Rangkorrelation zu erfassen, ist nach Spearman die Quadratsumme:[2]












der Rangdifferenzen zu bilden. Der Spearman’sche Rangkorrelationskoeffizient ist dann gegeben durch:


Sind alle Ränge verschieden, ergibt diese einfache Formel exakt dasselbe Ergebnis.
Bei Bindungen
Wenn identische Werte für oder (also Bindungen) existieren, wird die Formel etwas komplizierter. Aber solange nicht sehr viele Werte identisch sind, ergeben sich nur kleine Abweichungen:[3]

mit . Dabei ist die Anzahl der Beobachtungen mit gleichem Rang; wobei entweder für oder für steht.



Beispiel 1
Als Beispiel sollen Größe und Körpergewicht verschiedener Menschen untersucht werden. Die Paare von Messwerten seien 175 cm, 178 cm und 190 cm und 65 kg, 70 kg und 98 kg.
In diesem Beispiel besteht die maximale Rangkorrelation: Die Datenreihe der Körpergrößen wird nach Rang geordnet, und die Rangzahlen der Körpergrößen entsprechen auch den Rangzahlen der Körpergewichte. Eine niedrige Rangkorrelation herrscht, wenn etwa die Körpergröße im Verlauf der Datenreihe größer wird, das Gewicht jedoch abnimmt. Dann kann man nicht „Der schwerste Mensch ist der größte“ sagen. Der Rangkorrelationskoeffizient ist der zahlenmäßige Ausdruck des Zusammenhanges zweier Rangordnungen.
Beispiel 2
Gegeben sind acht Beobachtungen zweier Variablen a und b:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 2,0 | 3,0 | 3,0 | 5,0 | 5,5 | 8,0 | 10,0 | 10,0 | |
| 1,5 | 1,5 | 4,0 | 3,0 | 1,0 | 5,0 | 5,0 | 9,5 |


Um den Rang für die Beobachtungen von b zu ermitteln, wird folgendermaßen vorgegangen: Zunächst wird nach dem Wert sortiert, dann wird der Rang vergeben (d. h. neu durchnummeriert) und normiert, d. h. bei gleichen Werten wird der Mittelwert gebildet. Zuletzt wird die Eingangsreihenfolge wiederhergestellt, damit dann die Differenzen der Ränge gebildet werden können.
| Eingang | Sort(Wert) | Rang ermitteln | Sort(Index) |
|---|---|---|---|




Aus den zwei Datenreihen a und b ergibt sich folgende Zwischenrechnung:
| Werte von a | Werte von b | Rang von a | Rang von b | ||
|---|---|---|---|---|---|
| 2,0 | 1,5 | 1,0 | 2,5 | −1,5 | 2,25 |
| 3,0 | 1,5 | 2,5 | 2,5 | 0,0 | 0,00 |
| 3,0 | 4,0 | 2,5 | 5,0 | −2,5 | 6,25 |
| 5,0 | 3,0 | 4,0 | 4,0 | 0,0 | 0,00 |
| 5,5 | 1,0 | 5,0 | 1,0 | 4,0 | 16,00 |
| 8,0 | 5,0 | 6,0 | 6,5 | −0,5 | 0,25 |
| 10,0 | 5,0 | 7,5 | 6,5 | 1,0 | 1,00 |
| 10,0 | 9,5 | 7,5 | 8,0 | −0,5 | 0,25 |



Die Tabelle ist nach der Variablen a geordnet. Wichtig ist, dass sich Einzelwerte einen Rang teilen können. In der Reihe a gibt es zweimal „3“, und sie haben jeweils den „durchschnittlichen“ Rang (2+3)/2 = 2,5. Dasselbe geschieht bei der Reihe b.
| Werte von a | Werte von b | ||||
|---|---|---|---|---|---|
| 2,0 | 1,5 | 1 | 0 | 2 | 6 |
| 3,0 | 1,5 | 2 | 6 | - | - |
| 3,0 | 4,0 | - | - | 1 | 0 |
| 5,0 | 3,0 | 1 | 0 | 1 | 0 |
| 5,5 | 1,0 | 1 | 0 | 1 | 0 |
| 8,0 | 5,0 | 1 | 0 | 2 | 6 |
| 10,0 | 5,0 | 2 | 6 | - | - |
| 10,0 | 9,5 | - | - | 1 | 0 |






Mit der Korrektur nach Horn ergibt sich schließlich

Bestimmung der Signifikanz
Der moderne Ansatz für den Test, ob der beobachtete Wert von sich signifikant von null unterscheidet führt zu einem Permutationstest. Dabei wird die Wahrscheinlichkeit berechnet, dass für die Nullhypothese größer oder gleich dem beobachteten ist.
Dieser Ansatz ist traditionellen Methoden überlegen, wenn der Datensatz nicht zu groß ist, um alle notwendigen Permutationen zu erzeugen, und weiterhin, wenn klar ist, wie man für die gegebene Anwendung sinnvolle Permutationen für die Nullhypothese erzeugt (was aber normalerweise recht einfach ist).
Kendall’sches Tau
Im Gegensatz zum Spearman’schen nutzt das Kendall’sche nur den Unterschied in den Rängen und nicht die Differenz der Ränge. In der Regel ist der Wert des Kendall’schen etwas kleiner als der Wert des Spearman’schen . erweist sich darüber hinaus auch für intervallskalierte Daten als hilfreich, wenn die Daten nicht normalverteilt sind, die Skalen ungleiche Teilungen aufweisen oder bei sehr kleinen Stichprobengrößen.

Kendall’sches Tau für Zufallsvariable
Sei ein bivariater Zufallsvektor mit Copula und Randverteilungsfunktionen . Damit hat gemäß dem Satz von Sklar die gemeinsame Verteilungsfunktion . Das Kendall'sches Tau für den Zufallsvektor ist dann definiert als:



Man bemerke, dass unabhängig von den Randverteilungen des Zufallsvektors ist. Der Wert hängt daher nur von seiner Copula ab.
Empirisches Kendall’sches Tau
Um das empirische zu berechnen, betrachten wir Paare von nach sortierten Beobachtungen und mit und . Es gilt also:




Dann wird das Paar 1 mit allen folgenden Paaren () verglichen, das Paar 2 mit allen folgenden Paaren () usw. Es werden also insgesamt Paarvergleiche durchgeführt. Gilt für ein Paar:



- und , so heißt es konkordant oder übereinstimmend,
- und , so heißt es diskonkordant oder uneinig,
- und , so ist es eine Bindung in ,
- und , so ist es eine Bindung in und
- und , so ist es eine Bindung in und .







Die Anzahl der Paare, die
- konkordant oder übereinstimmend sind, wird mit ,
- diskonkordant oder uneinig sind, wird mit ,
- die Bindungen in sind, wird mit ,
- die Bindungen in sind, wird mit und
- die Bindungen in und sind, wird mit bezeichnet.




Das Kendall’sche Werte vergleicht nun die Zahl der konkordanten und der diskonkordanten Paare:

Ist das Kendall’sche positiv, so gibt es mehr konkordante Paare als diskonkordante, d. h. es ist wahrscheinlich, dass wenn ist, dann auch gilt. Ist das Kendall’sche Tau negativ, so gibt es mehr diskonkordante Paare als konkordante, d. h. es ist wahrscheinlich, dass wenn ist, dann auch gilt. Der Wert normiert das Kendall’sche , so dass gilt:





Test des Kendall’schen Taus
Betrachtet man die Zufallsvariable , so hat Kendall herausgefunden, dass für den Test
- vs.


diese unter Nullhypothese approximativ normalverteilt ist: . Neben dem approximativen Test kann auch ein exakter Permutationstest durchgeführt werden.

Weitere τ-Koeffizienten
Mit den obigen Definitionen hatte Kendall insgesamt drei -Koeffizienten definiert:
- (siehe oben)



Das Kendall’sche Tau kann nur auf Daten ohne Bindungen angewandt werden. Das Kendall’sche erreicht auf nicht quadratischen Kontingenztabellen nicht die Extremwerte bzw. und berücksichtigt, da nicht einfließt, keine Bindungen in und . Bei Vierfeldertafeln ist mit dem Vierfelderkoeffizienten (Phi) und, wenn die Ausprägungen der beiden dichotomen Variablen jeweils mit 0 und 1 kodiert sind, auch mit dem Pearson’schen Korrelationskoeffizienten identisch.





Tetra- und polychorische Korrelation
Im Zusammenhang mit Likert-Items wird oft auch die tetra- (bei zwei binären Variablen) oder polychorische Korrelation berechnet. Dabei geht man davon aus, dass z. B. bei einer Frage mit der Antwortform (Trifft überhaupt nicht zu, …, Trifft vollständig zu) die Befragten eigentlich in einem metrischen Sinn geantwortet hätten, aber aufgrund der Antwortform sich für eine der Alternativen entscheiden mussten.
Das heißt hinter den beobachteten Variablen , die ordinal sind, stehen also unbeobachtete intervallskalierte Variablen . Die Korrelation zwischen den unbeobachteten Variablen heißt tetra- oder polychorische Korrelation.


Die Anwendung der tetra- bzw. polychorischen Korrelation bei Likert-Items empfiehlt sich, wenn die Zahl der Kategorien bei den beobachteten Variablen kleiner als sieben ist.[4] In der Praxis wird stattdessen oft der Bravais-Pearson-Korrelationskoeffizient zu Berechnung der Korrelation benutzt, jedoch kann man zeigen, dass damit die wahre Korrelation unterschätzt wird.[5]
Schätzverfahren für die tetra- oder polychorische Korrelation
Unter der Annahme, dass die unbeobachteten Variablen paarweise bivariat normalverteilt sind, kann man mit Hilfe der Maximum-Likelihood-Methode die Korrelation zwischen den unbeobachteten Variablen schätzen. Dafür gibt es zwei Verfahren:
- Man schätzt zuerst die Intervallgrenzen für jede Kategorie für jede unbeobachtete Variable (unter Annahme der univariaten Normalverteilung für die jeweilige unbeobachtete Variable). Danach wird in einem zweiten Schritt die Korrelation mit den zuvor geschätzten Intervallgrenzen nur noch die Korrelation mit der Maximum-Likelihood-Methode geschätzt (twostep Methode).
- Sowohl die unbekannten Intervallgrenzen als auch die unbekannte Korrelation gehen als Parameter in die Maximum-Likelihood-Funktion ein. Sie werden dann in einem Schritt geschätzt.
Approximationsformel für die tetrachorische Korrelation
| \ | 0 | 1 |
|---|---|---|
| 0 | ||
| 1 |






Für zwei binäre Variablen kann mit Hilfe der Kreuztabelle rechts eine Näherungsformel für die tetrachorische Korrelation angegeben werden:

Eine Korrelation von liegt genau dann vor, wenn . Entsprechend liegt eine Korrelation von genau dann vor, wenn .




Einzelnachweise
- Fahrmeir et al.: Statistik. 2004, S. 142.
- Werner Timischl: Angewandte Statistik. Eine Einführung für Biologen und Mediziner. 3. Auflage. 2013, S. 303.
- D. Horn: A correction for the effect of tied ranks on the value of the rank difference correlation coefficient. In: Educational and Psychological Measurement, 3, 1942, S. 686–690.
- D. J. Bartholomew, F. Steele, J. I. Galbraith, I. Moustaki: The Analysis and Interpretation of Multivariate Data for Social Scientists. Chapman & Hall / CRC, 2002
- K. G. Jöreskog, D. Sorbom: PRELIS, a program for multivariate data screening and data summarization. Scientific Software, Mooresville 1988