POW!
POW! (Programmers Open Workbench)[1] ist eine in Oberon-2 geschriebene Programmierumgebung. Oberon und Oberon-2 sind konsequente Weiterentwicklungen der Programmiersprache Pascal, wobei es auch noch den Zwischenschritt Modula-2 gibt. Die integrierte Entwicklungsumgebung hat Ähnlichkeiten mit der IDE des Vorläufers Turbo Pascal. POW! wurde in den 1990er Jahren an der Johannes Kepler Universität Linz, vorwiegend durch Studenten unter der Leitung von Prof. Mühlbacher für Microsoft Windows entwickelt. POW! ist kostenlos erhältlich und die Quelltexte sind sowohl auf der Homepage[1] als auch auf Github zu finden.[2] Der Installer lässt sich unter Windows 10 nicht ohne Weiteres starten, eine mit Wine (Version 4.0) unter Linux (Debian 10, Buster) installierte Version startet aber problemlos. POW! unterstützt die Programmiersprachen Oberon-2, C, C++ und Java.[3]
| POW! | |
|---|---|
| Beeinflusst von: | Oberon |
| Betriebssystem: | Windows |
Verwendung
POW! eignet sich vorwiegend zum Programmieren von einfachen und komplexeren, mathematischen Programmen. Im Modul ColorPlane sind zwar auch einfache Grafikoptionen zu programmieren, dennoch sind keine komplexen grafisch-orientierten Programme möglich. Die Darstellung von Objekten und Grafiken beansprucht eine hohe Rechenleistung und benötigt daher viel Zeit. POW! eignet sich trotz seiner einfachen Struktur zum objektorientierten und rekursiven Programmieren. Damit kann das Programm Sachverhalte schneller lösen. Die Stärke dieser Programmiersprache liegt in der Erfüllung der Aufgaben, auch von komplexen Programmen. Die Darstellung gestaltet sich hingegen schwieriger, da es keine Optionen für Tabellen oder ähnliche Vorlagen gibt. Durch die Verwendung von einfachen und komplexen Datentypen kann der benötigte Speicherplatz sehr gering gehalten werden. Durch die Aufteilung in verschiedene Module kann die Aufgabe auf verschiedene Weisen mit den bestehenden Mittel bestmöglich erfüllt werden. Es werden nur die benötigten Funktionen aktiviert. Dadurch wird Arbeitsspeicher sowie Zeit für das Lösen der Algorithmen gespart.
Funktionen
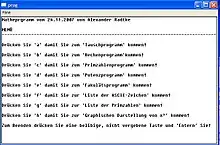
Ein Programm kann in mehrere Teilprogramm gesplittet werden, die wiederum verschiedene Module enthalten. Dabei kann ein Modul ein bereit existierendes Teilprogramm sein oder ein selbst geschriebenes Programm. Jedes Teilprogramm kann aus einzelnen Prozeduren bestehen, die wieder rum in anderen Modulen aufgerufen werden können oder aber auch nur für das Modul, indem es enthalten ist, zugänglich ist.
Module
Oberon-POW! verfügt über eine Anzahl von einfachen, sowie komplexeren Modulen. Mithilfe von einfachen Modulen, wie zum Beispiel Display, Import, Export, können Zeichen, Zahlen und Texte ausgegeben werden. Unter Verwendung des Modul ColorPlane können Objekte grafisch dargestellt werden. Komplexe grafische Objekte wie Kreise müssen berechnet und Punktweise (Pixel weise) ausgegeben werden. Die führt zu einer langen Rechenzeit. Daher ist POW! für die Ausgabe solcher Objekte eher ungeeignet. Durch die Benutzung von weiteren Modulen sind Funktionen wie Wurzel ziehen, Zeit ermitteln, speichern, laden oder Zufallszahl ermitteln möglich. Dem User stehen von Anfang an durch POW! bereits einige Module zur Verfügung.[4] Dabei erzeugen einige Module ein eigenes Fenster und dienen der Darstellung andere hingegen sind nur für die reinen Rechenoperationen vorgesehen.

Die sogenannten „Grundbausteine“ sind:
- Strings
- Float
- Utils
- OOBase
- Param
- Process
Dann gibt es bestimmte „Benutzerschnittstellen“. Das sind die Module, die für eine Ausgabe von Zeichen und Grafiken benötigt werden:
- Display
- ColorPlane
Des Weiteren sind Module für das Speichern und Laden der eingegebenen Dateien vorhanden. Zu diesem „Dateisystem-Zugang“ zählen:
- File
- Volume
POW! verfügt auch über ein Modul, das das Ausdrucken der Ausgabe ermöglicht. Dies ist im folgenden Modul enthalten:
Zu guter Letzt verfügt POW! über weitere Module, die den sogenannten „Kompatibilitätsmodule entsprechend den Oakwook-Richtlinien“ zugeordnet werden können. Dazu zählen:
- In
- Out
- XYplane
Es gibt weitere Module die nicht von POW! aus zur Verfügung stehen, die aber kostenlos geladen, benutzt und sogar verändert werden können. Diese Programme wurden von Michael W. Kühn entwickelt und laufen unter dem Namen MK Software.[5] Folgende Module stehen zur Verfügung:
Prozeduren
Prozeduren dienen dazu, den Quelltext übersichtlicher zu gestalten und dass immer wiederkehrende Aufgaben nicht mehrere Male geschrieben werden müssen. Eine Prozedur kann Informationen entgegennehmen und ausgeben sowie bestimmte Zustände ändern. Je mehr Parameter entgegengenommen werden, umso weitläufiger lässt sich die Prozedur einsetzten.
Jede Prozedur kann auf seine lokalen und die globalen Variablen bzw. Datentypen zugreifen. Eine Prozedur entsteht durch die sinnvolle Aneinanderreihung von einzelnen Befehlen, die die Programmiersprache zur Verfügung stellt. Solche Befehle können Aus- oder Eingabebefehle sein, es können Rechenoperationen oder Schleifen. Wobei Schleifen, Rechenoperationen und Umwandelbefehle in jedem Modul gleich, Aus- und Eingabebefehle jedoch unterschiedlich sein können. Darüber hinaus gibt es Befehle, die nur in einzelnen Modulen enthalten sind wie zum Beispiel das Wurzel ziehen oder die Übergabe einer bestimmten Koordinate.
Prozeduren können entweder Modul-intern oder -extern sein. Interne Prozeduren können in dem ganzen Modul genutzt werden. Dafür muss die entsprechende Prozedur im Hauptprogramm aufgerufen werden. Des Weiteren gibt es die Möglichkeit Prozeduren im Hauptprogramm zu nutzen, auch wenn diese in anderen Modulen enthalten sind. Dafür muss die entsprechende Prozedur freigegeben werden. Dies erfolgt durch das Sternsymbol (*). Außerdem muss das Modul, in dem die besuchte Prozedur ist, in dem Modul importiert werden, welches das Hauptprogramm enthält.
Die wichtigste Prozedur in einem POW!-Programm ist das Hauptprogramm (ProgMain*). Dieses Programm ist für die Ausgabe verantwortlich. Im Hauptprogramm müssen die verwendeten Prozeduren direkt oder indirekt, durch andere Prozeduren in denen sie verwendet werden, aufgerufen werden. Das Hauptprogramm kommuniziert mit dem Compiler und der Windows-Oberfläche. Es muss daher auch veröffentlicht werden und wird daher auch mit dem Sternsymbol erweitert.
Befehle
Jede Programmiersprache besteht aus Befehlen, die sinnvoll aneinandergereiht die Prozeduren und den Quelltext ergeben. Solche Befehle können entweder modulabhängig sein oder von der Programmiersprache vorgegeben sein. Modulabhängig sind Einlese- oder Ausgabebefehle. Diese unterscheiden sich unter den verschiedenen Modulen. Unabhängig sind hingegen Wiederholungsanweisungen, Wertzuweisungen und Auswahlanweisungen. Bei den Wertzuweisungen wird den Variablen ein bestimmter Zustand oder Wert, je nach Datentyp, zugeordnet. Die Wiederholungsanweisungen dienen dazu, eine bestimmte Bedingung abzuwarten oder sich selbst so lange zu wiederholen, bis die Abbruchbedingung zutrifft. Die einfachste dieser Anweisungen ist die FOR-Schleife. Hierbei wird von vornherein eine bestimmte Anzahl an Durchläufen vorgegeben. Der Inhalt der Schleife wird so oft wiederholt, bis die Anzahl der Wiederholungen erreicht ist. Eine zweite Art von Wiederholungsanweisungen ist die REPEAT-Anweisung. Diese Schleife läuft so oft durch, bis die Abbruchbedingung bei UNTIL zutrifft. Dabei ist zu beachten, dass diese Schleife mindestens einmal durchläuft. Im Gegensatz dazu gibt es die WHILE-Schleife. Diese überprüft ganz am Anfang, ob die Bedingung für einen Schleifendurchlauf zutrifft oder nicht. Diese Anweisung kann auch keinmal durchlaufen werden. Wenn die Auswahlbedingung nicht zutrifft, läuft die Schleife nicht. Die letzte Möglichkeit ist der LOOP. Diese Anweisung verfügt über keine Abbruchbedingung und muss durch eine separate Prüfung abgebrochen werden. Wenn die Prüfung ein Ergebnis bringt, dann wird der Befehl EXIT gegeben, wodurch diese Schleife beendet wird.
Eine weitere Art von Befehlen sind die Auswahlanweisungen. Zu ihnen gehören CASE und IF. Bei der CASE-Anweisung wird eine Variable überprüft, ob sie eine der entsprechenden Bedingungen erfüllt. Je nach Lösung wird der besagte "Zweig" ausgeführt. Die IF-Anweisung ist die Überprüfung, ob eine Bedingung zutrifft oder nicht. Trifft die Bedingung zu, wird der Inhalt der IF-Anweisung ausgeführt. Ansonsten wird der ELSE-Zweig ausgeführt. Sollte dieser nicht vorhanden sein, wird die Anweisung übersprungen.
Datentypen
Im Gegensatz zu manch anderen Programmiersprachen, muss bei Oberon-POW! der Datentyp, in den die Informationen gespeichert werden, festgelegt werden. Ähnlich wie Prozeduren können auch Datentypen für andere Module freigegeben werden. Es gibt drei Möglichkeiten die Variablen zu vereinbaren. Die erste Möglichkeit ist die lokale Vereinbarung. Hierbei kann die Variable ausschließlich für die Prozedur verwendet werden. Vor allem Hilfsvariablen (Laufvariablen) werden lokal vereinbart. Die zweite Möglichkeit ist die globale Bestimmung des Datentyp. Die Variablen müssen dafür im Hauptprogramm oder vor der ersten Prozedur festgelegt werden. Diese Variablen können im ganzen Modul verwendet werden und stellen den überwiegenden Teil der Speicherplatzzuweisungen dar. Die dritte Art von Variablen können in allen Modulen benutzt werden. Hierfür muss wie bei den Prozeduren verfahren werden. Die Variable muss mit dem Sternsymbol (*) freigegeben werden und das Modul, in dem die Variable bestimmt wird, muss importiert werden. Diese Art der Zuweisung erfolgt bei langen Programmen, die über mehrere Module arbeiten.
Einfache Datentypen
Einfache Datentypen sind diejenigen, in denen nur ein Wert gespeichert werden kann. Dabei wird nach der Art der Datei unterschieden.
Folgende Strukturen sind einfache Datentypen:
| Typ | Bereich | Speicherbedarf | Art der Dateistruktur |
|---|---|---|---|
| Shortinteger | −128 bis 127 | 1 Byte | ganze Zahlen |
| Integer | −32768 bis 32767 | 2 Byte | ganze Zahlen |
| Longinteger | −2.15*e9 bis 2.15*e9 | 4 Byte | ganze Zahlen |
| Real | −3.4*e28 bis 3.4*e28 | 4 Byte | reelle Zahlen |
| Longreal | −1.79*e308 bis 1.79*e308 | 8 Byte | reelle Zahlen |
| Boolean | TRUE / FALSE | 1 Byte | Wahrheitswert |
| Charakter | ASCII CODE 32–255 | 1 Byte | Zeichen des ASCII-Code |
| Set | Menge der Zahlen von 0 bis 31 | max. 64 Byte | Wird für bestimmte Operationen benötigt |
Es gibt die Möglichkeit die einzelnen, einfachen Datenstrukturen in andere abstrakte Datenstrukturen umzuwandeln. Diese Befehle sind Modul extern und können immer angewandt werden.
Abstrakte Datentypen
Komplexe Datentypen können sowohl einfache als auch komplexe Datentypen enthalten. Dies können sein
Array
Ein ARRAY ist eine Aneinanderreihung von einfachen Datentypen desselben Typs. Arrays, Listen, Matrizen und Strings sind solche komplexen Datentypen. Ein Array besteht aus einer vorherbestimmten Anzahl an Elementen, welche systematisch durchnummeriert sind, wodurch jedem Element eine Zahl zugeordnet werden kann. Der Inhalt dieses Elements ist die gespeicherte Datei. Eine Liste hingegen enthält nur so viele Elemente, wie auch "besetzt" sind. Dadurch kann Speicherplatz gespart werden. Jedoch sind die Elemente nicht durchnummeriert. Um an den Inhalt eines Elementes zu gelangen muss erst die ganze Liste durchgegangen werden bis zu dem besagten Element. Ein String kann ein Wort, ein Satz oder sogar ein Text sein. Es ist eine Aneinanderreihung von Charakter, also von einzelnen Zeichen. Die Länge dieses Feldes ist durch die Art des Feldes vorherbestimmt. Es kann auf jeden Charakter durch seine Nummer zugegriffen werden. Der String ist somit ein Array von Charakter. Der Inhalt jedes Feldes dieses Arrays ist das Zeichen. Eine Matrix ist ein Array, bei dem jedes Element ein Array enthält. Aus einer eindimensionalen Speicherplatz-Bestimmung wird eine zweidimensionale. Die Art des Datentyp muss vorher festgelegt werden.
TYPE Kette = ARRAY 20 OF CHAR;
Der vorliegende Dateityp ist eine Kette von 20 Elementen, wobei die Nummerierung bei 0 beginnt, wovon jedes Element Charakter ist. Dieser Datentyp muss dann noch als Variable vereinbart werden
VAR Kettenelement:Kette;
Der Aufruf erfolgt beispielsweise in der folgenden Art und Weise:
Kettenelement[2]:= "W";
Dem 2. Element aus der Kette wird der Wert "W" zugewiesen.
Matrix
Eine Matrix sind zwei Arrays, die ein Feld aufspannen. Jedes Feld ist durch zwei Zahlen genau definiert, zum Beispiel ([1,3] oder [45,2]). Die Matrix ist vor allem dann gut zu Verwenden, wenn ein System mit Spalten und Zeilen gefragt ist. Alle Daten dieses Datentyp müssen das gleiche Format haben. Dieses muss vorher festgelegt werden und entspricht einem einfachen Datentyp. Dabei kann sich die Anzahl der Spalten von der Anzahl der Zeilen jedoch unterscheiden. Die Matrix ist ein erweitertes Array und kann zu den Arrays gezählt werden. Die Matrix kann wie folgt vereinbart:
TYPE Kette = ARRAY 20,14 OF INTEGER;
Hier kann auf jedes einzelne Element genau zugegriffen werden. Dies ist die Matrix im eigentlichen Sinne. Es ist auch möglich jedem Array ein Array als Datentyp zuzuordnen. Dabei kann jedoch nur auf das Element zugegriffen werden. Auf das einzelne Glied des Arrays aus dem jedes Element besteht kann nicht zugegriffen werden. Dieser Datentyp der ein Art Verbindung zwischen Array und Matrix wird wie folgt deklariert:
TYPE Element = ARRAY 20 OF INTEGER;
Matrixarray = ARRAY 14 OF Element;
VAR Hybrid:Matrixarray;
Du beachten ist hier, welche Art von Datentyp in jedem Element gespeichert werden kann. In diesem Fall ist das die Integerzahl. Der Vorteil liegt darin begründet, dass das Array "Element" auch noch eigenständig verwendet werden kann.
VAR Elementarray:Element;
So kann mit einer Vereinbarung das Array "Element" für verschiedenen Zwecke verwendet werden.
Record
Der RECORD hingegen ist eine Verbindung von unterschiedlichen Datentypen. Er kann auch ARRAYs enthalten oder einfache Datenstrukturen. Der RECORD ist der komplexeste der vorhandenen Datenstrukturen. Er kann die unterschiedlichen Datentypen enthalten und lässt sich genau eingrenzen. Ein Record wird immer mit der Variablen .Record-glied aufgerufen. Der Punkt stellt dabei die Trennung her zwischen der Variablen, die den Record enthält und der Variablen, die in dem Record enthalten ist.
Der Record muss ebenso vorherbestimmt sein.
TYPE Beispiele = RECORD Name:Kette;
Alter:INTEGER;
aktiv:BOOLEAN;
END;
Der RECORD muss dann wieder einer Variablen zugewiesen werden. Wobei es sich bei der Variablen wieder um ein ARRAY handeln kann. Dies ist möglich, da das ARRAY jedes Mal den gleichen Datentyp, einen RECORD enthalten würde.
TYPE Recordarray = ARRAY-10-OF-Beispiele; VAR Wikirecord:Recordarray;
Damit ist eine Kette von 10 RECORDs geschaffen, die ihrerseits wiederum ARRAYs enthalten. Der Aufruf erfolgt zunächst wie ein ARRAY, an den dann der Aufruf eines RECORDS angehängt wird.
Wikirecord[5].Name[2]:= "G"; Wikirecord[5].Alter:= 23;
Das fünfte Elementen der Kette, welche den Record enthält wird ausgewählt. Von diesem Element wird das Recordglied "Name" ausgewählt. Da nur ein Zeichen bestimmt werden soll, kann dieses genau angesprochen werden ([2]). Es besteht auch die Möglichkeit ein Wort zu notieren. Dies würde so aussehen:
Wikirecord[5].Name:= "Hallo Wiki";
Mit Hilfe von solchen komplexen Datenstrukturen ist es möglich sehr komplexe Probleme zu lösen. Mit dem gezeigten Beispiel können zum Beispiel Karteien angelegt werden.
Liste
Die letzte Form der abstrakten (oder komplexen) Datentypen stellt die Liste dar. Sie ist an das ARRAY angelehnt unterscheidet sich dennoch grundlegend. Es sind nur jeweils so viele Elemente, wie benötigt enthalten. Bei einer Liste werden die Elemente nicht durchnummeriert und das Element kann nicht direkt angesteuert werden.
In POW! sieht die Vereinbarung einer Liste so aus:
TYPE ListenzeigerT = POINTER TO DatenelemenT;
DatenelemenT = RECORD Inhalt:INTEGER;
next:ListenzeigerT;
END;
Der "Pointer" ist der Zeiger, der auf das Datenelement zeigt. Der Pointer teilt dem Programm mit, bei welchem Element er Anfangen soll, welcher Speicherplatz der Erste ist. Die Variable "next" ist jeweils der Zeiger, der auf das nächste Element deutet. In dem "Inhalt" ist die Datei abgespeichert. Der letzte Zeiger muss auf das Ende zeigen. Dieses ist in POW! bei dem feststehenden Komplex "NIL" gegeben. Um ein Element auszugeben muss es erst gefunden werden. Dabei wird jedes Element geprüft ob es den gesuchten Inhalt enthält. Diese Art und Weise der Suche macht den Zugriff langsamer und komplizierter. Dafür wird nur stets soviel Platz reserviert, wie auch benötigt wird.
PROCEDURE Elementsuchen(VAR a:ListenzeigerT; n: INTEGER);
VAR lauf,hilf:ListenzeigerT;
BEGIN
lauf:=a;
WHILE lauf.next#NIL DO
IF lauf.Inhalt=n THEN
Display.WriteStr("Element gefunden");
Display.WriteLn;
END;
lauf:=lauf.next;
END;
END Elementsuchen;
PROCEDURE Elementsuchen(VAR a:ListenzeigerT; n: INTEGER);
VAR lauf,hilf:ListenzeigerT; e:INTEGER;
BEGIN
lauf:=a; e:=0;
WHILE lauf.next#NIL DO
IF lauf.Inhalt=n THEN
e:=e+1;
END;
lauf:=lauf.next;
END;
D.WriteStr("Der gesuchte Wert wurde");
D.WriteInt(e,3);
D.WriteStr(" mal gefunden");
END Elementsuchen;
Hier wird ein Element gesucht. Der Benutzer kann den gesuchten Wert/Zustand eingeben. Diesem Wert wird die Variable "n" zugewiesen. Danach wird die Liste systematisch abgesucht ob ein Element den gesuchten Inhalt hat. Jedes Mal wen so ein Element gefunden wurde wird der Satz "Element gefunden" ausgegeben und eine Zeile nach unten gerutscht. Bei der 2. Variante wird die Anzahl der „Treffer“ gezählt und diese ausgegeben. Die Anwendung dieser Art von Listen ist vor allem dann sinnvoll, wenn sie die Anzahl der gespeicherten Dateien ständig ändert oder immer weiter verlängert werden soll, ohne dass der Quelltext verändert werden muss.
Grenzen
Es gibt einige Grenzen für diese Programmiersprache oder für deren Anwendung:
- Es sind nur eine begrenzte Anzahl an Zeichen je Modul möglich. Wird diese Anzahl überschritten, versagt das Compiler-Programm, und es kann nicht geprüft werden, ob das geschriebene Programm Fehler enthält. Durch ausschalten der Compiler-Funktion ist es zwar noch zu starten, aber dies ist nicht empfehlenswert. Das Programm sollte in Teilprogramme, in einzelne Module gesplittet werden.
- Durch die Einteilung in Datentypen kann es zu Problemen bei der Berechnung kommen. So kann bei dem Ziehen einer Wurzel aus einer Integerzahl eine Realzahl werden.
- Speichern und Laden von Dateien, die im Programm eingegeben wurden, ist sehr aufwendig. Daher eignet es sich vorwiegend nur für Programme, bei denen die Ergebnisse von vorherigen Berechnungen unwichtig sind.
- Die Darstellung von Bildern ist möglich,[8] jedoch wird jedes einzelne Pixel dafür berechnet. Gleiches gilt für komplexe mathematische Figuren oder Schaubilder.
- Eine zu komplexe Rekursion kann zum Absturz des Programmes führen.
- Der Compiler kann unter Umständen, vor allem bei sehr komplexen Programmen, falsche Korrekturvorschläge anzeigen.
Literatur
- Mühlbacher, Leisch, Kreuzeder: Programmieren mit Oberon-2 unter Windows. Hanser, München / Wien 1995, ISBN 3-446-18406-6
Weblinks
Einzelnachweise
- POW! – Programmers Open Workbench
- Github/Spirit of Oberon/POW abgerufen im Juli 2020
- Das Projekt POW! (Microsoft Word; 1,5 MB) abgerufen im Juni 2011
- Module in POW!
- Michael Kühn Software
- MK Turtle
- POW! Zufallsgenerator
- Darstellen von Bilddateien (Memento des Originals vom 1. Januar 2010 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis.