Huffman-Kodierung
Die Huffman-Kodierung ist eine Form der Entropiekodierung, die 1952 von David A. Huffman entwickelt und in der Abhandlung A Method for the Construction of Minimum-Redundancy Codes publiziert wurde.[1] Sie ordnet einer festen Anzahl an Quellsymbolen jeweils Codewörter mit variabler Länge zu. In der Informationstechnik ist sie ein Präfix-Code, die üblicherweise für verlustfreie Kompression benutzt wird. Ähnlich anderer Entropiekodierungen werden häufiger auftauchende Zeichen mit weniger Bits repräsentiert als seltener auftauchende.
Grundlagen
Um Daten möglichst redundanzfrei darzustellen, müssen die Quellsymbole mit Codewörtern unterschiedlicher Wortlängen kodiert werden. Die Länge der Codewörter entspricht dabei idealerweise ihrem Informationsgehalt. Um einen Code auch wieder eindeutig dekodieren zu können, muss er die Kraftsche Ungleichung erfüllen und zusätzlich noch präfixfrei sein, d. h. kein Codewort darf der Beginn eines anderen sein.
Die Grundidee ist, einen k-nären Wurzelbaum (ein Baum mit jeweils k Kindern je Knoten) für die Darstellung des Codes zu verwenden. In diesem sog. Huffman-Baum stehen die Blätter für die zu kodierenden Zeichen, während der Pfad von der Wurzel zum Blatt das Codesymbol bestimmt. Im Gegensatz zur Shannon-Fano-Kodierung wird der Baum dabei von den Blättern zur Wurzel (englisch bottom-up) erstellt.
Im Unterschied zum Morse-Code benötigt man bei einer Huffman-Codierung keine Trennzeichen. Eine Trennung der Codewörter ist nicht notwendig, da die Codierung präfixfrei ist. Dadurch ist kein Codewort Anfang eines anderen Codewortes.
Der bei der Huffman-Kodierung gewonnene Baum liefert garantiert eine optimale und präfixfreie Kodierung. D. h. es existiert kein symbolbezogenes Kodierverfahren, das einen kürzeren Code generieren könnte, wenn die Auftrittswahrscheinlichkeiten der Symbole bekannt sind.
Geschichte
Im Jahre 1951 hatten David A. Huffman und seine Klassenkameraden am MIT im Kurs Informationstheorie die Wahl zwischen einer Seminararbeit und einer Abschlussprüfung. Die Seminararbeit, betreut von Professor Robert M. Fano, sollte die Findung des effizientesten binären Codes thematisieren. Huffman, der nicht in der Lage war, die Effizienz eines Codes zu beweisen, war nur knapp vor dem Entschluss, aufzugeben und sich für die Abschlussprüfung vorzubereiten, als er auf die Idee stieß, einen frequenzsortierten Binärbaum zu verwenden, und somit in kürzester Zeit jene Methode als effizienteste beweisen konnte.
Auf diese Weise übertraf Huffman seinen Professor Fano, der gemeinsam mit dem Begründer der Informationstheorie Claude Shannon einen ähnlichen Code entwickelte. Indem Huffman den Baum von unten nach oben anstatt von oben nach unten erstellte, vermied er die größte Schwachstelle der suboptimalen Shannon-Fano-Kodierung.[2]
Algorithmus
Definitionen
- X ist das Quellsymbolalphabet – der Zeichenvorrat, aus dem die Quellsymbole bestehen
- px ist die A-priori-Wahrscheinlichkeit des Symbols x (die relative Häufigkeit)
- C ist das Codealphabet – der Zeichenvorrat, aus dem die Codewörter bestehen
- m ist die Mächtigkeit des Codealphabetes C – die Anzahl der verschiedenen Zeichen

Aufbau des Baumes
- Ermittle für jedes Quellsymbol die relative Häufigkeit, d. h. zähle, wie oft jedes Zeichen vorkommt, und teile durch die Anzahl aller Zeichen.
- Erstelle für jedes Quellsymbol einen einzelnen Knoten (die einfachste Form eines Baumes) und notiere im/am Knoten die Häufigkeit.
- Wiederhole die folgenden Schritte so lange, bis nur noch ein Baum übrig ist:
- Wähle die m Teilbäume mit der geringsten Häufigkeit in der Wurzel, bei mehreren Möglichkeiten die Teilbäume mit der geringsten Tiefe.
- Fasse diese Bäume zu einem neuen (Teil-)Baum zusammen.
- Notiere die Summe der Häufigkeiten in der Wurzel.
Konstruktion des Codebuchs
- Ordne jedem Kind eines Knotens eindeutig ein Zeichen aus dem Codealphabet zu.
- Lies für jedes Quellsymbol (Blatt im Baum) das Codewort aus:
- Beginne an der Wurzel des Baums.
- Die Codezeichen auf den Kanten des Pfades (in dieser Reihenfolge) ergeben das zugehörige Codewort.
Kodierung
- Lies ein Quellsymbol ein.
- Ermittle das zugehörige Codewort aus dem Codebuch.
- Gib das Codewort aus.
Mittlere Wortlänge
Die mittlere Länge eines Codeworts kann auf drei Arten berechnet werden.
- Über die gewichtete Summe der Codewortlängen:
- Die Summe aus der Anzahl der Schritte im Baum multipliziert mit der Häufigkeit eines Symbols.

- Indem man die Auftrittswahrscheinlichkeiten an allen Zwischenknoten des Huffman-Baums summiert.
- Bei ausschließlich gleicher Häufigkeit der zu codierenden Elemente ist die mittlere Länge
- mit als Anzahl der zu codierenden Elemente.


Beispiel
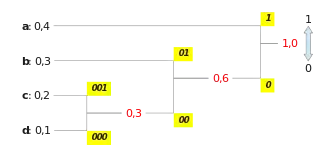
Das Quellalphabet enthält die Zeichen: Als Codealphabet wählen wir den Binärcode: und . Der Text a ab abc abcd soll (ohne die Leerzeichen) komprimiert werden.



Bestimme die relativen Häufigkeiten:
- pa = 0,4 ; pb = 0,3 ; pc = 0,2 ; pd = 0,1
Konstruiere einen Huffman-Baum und trage anschließend die Codewörter an den Kanten ein. (Siehe Bild rechts)
Codebuch:
| a | 1 |
| b | 01 |
| c | 001 |
| d | 000 |
Kodiere den ursprünglichen Text:
| Original: | a | a | b | a | b | c | a | b | c | d |
| Kodiert: | 1 | 1 | 01 | 1 | 01 | 001 | 1 | 01 | 001 | 000 |
Mittlere Codewortlänge:
- Bei einer naiven Kodierung würde jedes Zeichen mit kodiert.
- Diese Huffman-Kodierung kodiert jedes Zeichen mit


- Die Entropie liegt bei

Dadurch, dass der Informationsgehalt je Quellsymbol keine Ganzzahl ist, verbleibt bei der Kodierung eine Rest-Redundanz.
Dekodierung
Zur Dekodierung eines Huffman-kodierten Datenstroms ist (beim klassischen Verfahren) die im Kodierer erstellte Codetabelle notwendig. Grundsätzlich wird dabei umgekehrt wie im Kodierungsschritt vorgegangen. Der Huffman-Baum wird im Dekodierer wieder aufgebaut und mit jedem eingehenden Bit – ausgehend von der Wurzel – der entsprechende Pfad im Baum abgelaufen, bis man an einem Blatt ankommt. Dieses Blatt ist dann das gesuchte Quellsymbol und man beginnt mit der Dekodierung des nächsten Symbols wieder an der Wurzel.
Beispiel
Der Dekodierer hat das Codebuch:
| a | 1 |
| b | 01 |
| c | 001 |
| d | 000 |
und eine empfangene Nachricht: 1101101001101001000.
Jetzt wird für jedes empfangene Bit ausgehend von der Wurzel der Pfad im Baum (siehe oben) abgelaufen, bis ein Blatt erreicht wurde. Sobald ein Blatt erreicht wurde, zeichnet der Dekodierer das Symbol des Blattes auf und beginnt wieder bei der Wurzel, bis das nächste Blatt erreicht wird.
| Teil-Pfad: | 1 | 1 | 01 | 1 | 01 | 001 | 1 | 01 | 001 | 000 |
| Entsprechendes Blatt: | a | a | b | a | b | c | a | b | c | d |
Optimalität
Für mittlere Codewortlänge eines Huffman-Codes gilt (siehe auch [3])


Das bedeutet, im Mittel benötigt jedes Codesymbol mindestens so viele Stellen wie sein Informationsgehalt, höchstens jedoch eine mehr.
gilt genau dann, wenn alle Wahrscheinlichkeiten Zweierpotenzen sind (). In dem Fall sagt man, die Codierung sei optimal bezüglich der Entropie.


Fasst man Quellsymbole zu einem großen Symbol zusammen, so gilt für die mittleren Codesymbollängen



- ,

das heißt, mit zunehmender Anzahl gemeinsam kodierter Quellsymbole geht die mittlere Codewortlänge asymptotisch gegen die Entropie – die Kodierung ist asymptotisch optimal.
Adaptive Huffman-Kodierung
Die adaptive Huffman-Kodierung aktualisiert laufend den Baum. Der anfängliche Baum wird erzeugt, indem eine vorgegebene Wahrscheinlichkeitsverteilung für alle Quellsymbole angenommen wird (bei völliger Unkenntnis der Quelle eine Gleichverteilung). Mit jedem neuen Quellsymbol wird dieser aktualisiert, wodurch sich ggf. auch die Codesymbole ändern. Dieser Aktualisierungsschritt kann im Dekodierer nachvollzogen werden, so dass eine Übertragung des Codebuchs nicht nötig ist.
Mit dieser Methode kann ein Datenstrom on-the-fly kodiert werden. Er ist jedoch erheblich anfälliger für Übertragungsfehler, da ein einziger Fehler zu einer – ab der Fehlerstelle – komplett falschen Dekodierung führt.
Literatur
- Thomas M. Cover, Joy A. Thomas: Elements of Information Theory
Weblinks
- Paul E. Black: Huffman Coding, 12. Dezember 2011, NIST Dictionary of Algorithms and Data Structures.
- Eine Huffman-Bäume erzeugende Webapp
- Erklärung
Einzelnachweise
- D. A. Huffman: A method for the construction of minimum-redundancy codes. (PDF) In: Proceedings of the I.R.E.. September 1952, S. 1098–1101.
- Profil: David A. Huffman
- Strutz: Bilddatenkompression, SpringerVieweg, 2009