Data Stream Management System
Ein Data Stream Management System (DSMS) ist ein Software-System zur Verwaltung von kontinuierlichen Datenströmen. Es ist vergleichbar mit einem Datenbankverwaltungssystem (DBMS), welches für Datenbanken eingesetzt wird. Im Gegensatz zu einem DBMS, in dem Anfragen auf statischen Daten kurzzeitig ausgeführt werden, muss ein DSMS kontinuierliche Anfragen auf Datenströmen ausführen können. Zur Formulierung von Anfragen können spezielle Anfragesprachen wie beispielsweise die Continuous Query Language (CQL) eingesetzt werden.
Data Stream Management Systeme sind in der Datenbankwelt noch relativ neu. Einige erste Entwicklungen für allgemeine Zwecke sind:
- Stanford Stream Data Manager (STREAM) an der Stanford University
- Aurora an der Brandeis University, Brown University und dem MIT
- TelegraphCQ in Berkeley
- PipelineDB (wie TelegraphCQ ein Ableger von PostgreSQL)
Daneben gibt es eine wachsende Zahl kleinerer Projekte mit verschiedenen Schwerpunkten. Im Gegensatz zu nicht-strömenden Daten, die fast ausschließlich mit universellen Datenbankverwaltungssystemen verwaltet werden, werden für strömende Daten allerdings noch in der Regel Systeme verwendet, die speziell für den Anwendungsfall entwickelt oder angepasst werden.
Unterschiede zu DBMS
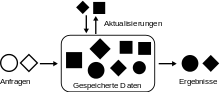
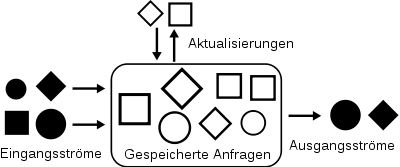
In herkömmlichen Datenbanksystemen werden kurzzeitig laufende Anfragen auf eine während der Datenauswertung gleichbleibende Datenbasis gestellt (siehe Transaktionssystem). Die Anfragen werden gestartet und bleiben solange im System, bis die Ergebnisse berechnet und ausgegeben wurden. Danach sind die Anfragen nicht mehr im System vorhanden. Man spricht auch davon, dass die Daten persistent und die Anfragen flüchtig sind. In einem Data Stream Management System werden die Anfragen einmalig installiert und bleiben im System bestehen, bis sie explizit wieder entfernt werden. Die Anfragen werden auf sich laufend ändernden Daten ausgewertet, nämlich auf Datenströmen. Die Ergebnisse der Anfragen werden ebenfalls kontinuierlich aktualisiert, ergeben also selbst auch einen Datenstrom. Man spricht auch davon, dass die Anfragen persistent und die Daten flüchtig sind. Diese beiden komplementären Prinzipien sind beispielsweise auch beim Information Retrieval als Ad-hoc-Anfragen (neue Anfragen an gleiche Dokumente) und Routing-Aufgaben (neue Dokumente zu vorgegebenen Anfragen) bekannt.[1]
Die folgende Tabelle gibt einen Vergleich verschiedener Merkmale eines Database Management Systems (DBMS) und eines Data Stream Management Systems (DSMS):
| Database Management System (DBMS) | Data Stream Management System (DSMS) |
|---|---|
| Persistente Daten (Relationen) | Flüchtige Datenströme |
| Random Access | Sequentieller Zugriff |
| Einmalige Anfragen | Kontinuierliche Anfragen |
| (Theoretisch) unbeschränkter Sekundärspeicher | Beschränkter Hauptspeicher |
| Nur der aktuelle Zustand ist relevant | Berücksichtigung der Eingangs-Reihenfolge |
| relativ niedrige Update-Rate | möglicherweise extrem hohe Update-Rate |
| keine oder geringe Zeitanforderungen | Echtzeitanforderungen |
| Exakte Daten werden angenommen | Veraltete / Ungenaue Daten |
| Planbare Anfragebearbeitung | Variable Datenankunft und -merkmale |
Grundlegende Konzepte
Ein DSMS hat, wie in der oberen Tabelle bereits ersichtlich, einige grundlegende Konzepte, die sich von einem herkömmlichen DBMS unterscheiden. Die wichtigsten Konzepte sind kontinuierliche Anfragen sowie Fenster.
Kontinuierliche Anfragen
Eine kontinuierliche Anfrage wird einmalig im System installiert und läuft solange, bis sie wieder entfernt wird. Die Anfrage hat einen oder mehrere Eingangsdatenströme und einen oder mehrere Ausgangsdatenströme. Das Ergebnis einer solchen Anfrage ist also kein einmaliger Satz an Daten, wie bei einer Anfrage in einem DBMS, sondern selbst ein Datenstrom. Die Ergebnisse sollten in nahezu Echtzeit erstellt werden, womit die Latenz zwischen der Ankunft neuer Daten und der Ausgabe eines neuen Ergebnisses von hoher Relevanz ist[2].
Wichtig bei einer kontinuierlichen Anfrage ist die Definition, wann eine neue Ausgabe produziert wird. Ein zeitgetriebenes Modell (engl. time-driven model) erzeugt neue Ausgaben anhand des zeitlichen Fortschritts einer Uhr, zum Beispiel der Systemzeit. So könnte eine neue Ausgabe einmal pro Minute erzeugt werden. Ein anderer Ansatz sind ereignisgetriebene Modelle (engl. event-driven model), bei denen neue Ausgaben erzeugt werden, wenn gewisse Ereignisse im Datenstrom auftreten. So könnte z. B. jedes neue Datenelement in einem Strom eine neue Ausgabe erzeugen, da dieses Datenstromelement das Ergebnis für diesen Zeitpunkt beeinflussen kann. Dann spricht man auch von einem tupelgetriebenen Modell (engl. tuple-driven model)[2].
Fenster
Datenströme sind potentiell unendlich, erzeugen also eine potentiell unendliche Menge an Daten. Während der Verarbeitung von kontinuierlichen Anfragen, die zumeist im Hauptspeicher passiert, steht allerdings nur eine begrenzte Menge an Speicher zur Verfügung. Fenster sind eine Möglichkeit, die Menge an Daten, die im Speicher gehalten werden muss, zu begrenzen. Eine weitere Motivation für die Verwendung von Fenstern ist der Verwendungszweck von kontinuierlichen Anfragen. Diese sollen Ergebnisse für die aktuellen Daten liefern, die mit dem Datenstrom in das DSMS fließen. Deshalb sind häufig nur die aktuellen Daten relevant, während ältere Daten nicht mehr für die aktuellen Ergebnisse benötigt werden. Um eine Begrenzung der Gültigkeit von Datenelementen ausdrücken zu können, werden Fenster verwendet.
Fenster begrenzen die Sicht auf den Datenstrom auf die neuesten Elemente des Stroms. Verbreitet sind zeit- und elementbasierte (auch: tupelbasierte) Fenster[2]. In zeitbasierten Fenstern werden die Elemente im Datenstrom eine gewisse, vorgegebene Zeit im System gehalten, zum Beispiel 30 Minuten. In einem elementbasierten Fenster enthält das Fenster maximal eine vorgegebene Menge an Elementen, zum Beispiel die neuesten 1000 Elemente. Ein Beispiel für eine Anfrage mit einem zeitbasierten Fenster ist: „Berechne den Durchschnitt des Attributs ‚x‘ von allen Datenstromelementen der letzten 30 Minuten.“
Element- und zeitbasierte Fenster können unterschiedlich definiert werden. Hier wird hauptsächlich zwischen gleitenden (engl. sliding) und taumelnden bzw. springenden (engl. tumbling) Fenstern unterschieden. Der Unterschied besteht in der Schrittgröße des Fensters, auch Periodizität genannt. Ein gleitendes Fenster schreitet mit dem Fortschritt des Datenstroms so voran, dass die Schrittweite minimal ist. In einem elementbasierten Fenster würde für ein neues Element, dass in das Fenster aufgenommen wird, also genau ein Element wieder entfernt werden. Die Schrittweite kann soweit verändert werden, dass sie die Größe des Fensters hat, dies nennt man dann ein taumelndes Fenster (engl. tumbling window). Hier wird ein Fenster bis zur angegebenen Größe gefüllt. Beim Eintreffen des nächsten Elementes, womit die angegebene Größe des Fensters überschritten werden würde, werden alle vorherigen Elemente gleichzeitig ungültig, und das neue Fenster wird schrittweise aufgebaut, bis es wieder die maximale Größe erreicht hat. In zeitbasierten Fenstern geschieht dies analog. Ein taumelndes Fenster wäre zum Beispiel ein Fenster der Größe von 30 Minuten und einer Schrittweite von 30 Minuten[2].
One-pass Paradigma
Die Ressourcen im Sinne von Rechenzeit und Speicherplatz zur Berechnung von Ergebnissen auf Datenströmen sind begrenzt. Algorithmen, die Datenströme verarbeiten, speichern die Daten deshalb typischerweise nicht erst vollständig und iterieren dann über den gesamten Datensatz, um Ergebnisse zu erzeugen, sondern verarbeiten jedes einzelne Element im Datenstrom nur einmal. Dies nennt man One-Pass Paradigma: Ein Datenelement durchläuft einen Algorithmus nur einmal[2]. Erreicht ein neues Element den Algorithmus, wird das Ergebnis der Berechnung angepasst und es ist kein neuer Zugriff auf das Element zu einem späteren Zeitpunkt mehr notwendig. Deshalb muss der Algorithmus keine alten Elemente speichern, sondern nur das aktuelle Zwischenergebnis.
Dies funktioniert zum Beispiel bei einem einfachen Zähler. Die Anzahl der Objekte soll gezählt werden. Kommt ein neues Element bei dem Algorithmus an, wird der Zähler um eins erhöht, gespeichert und das Element kann gelöscht werden. Nur der aktuelle Zählerstand muss gespeichert werden.
Verarbeitung von Strömen und Relationen
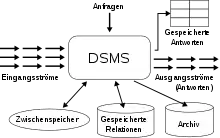
Während in herkömmlichen (relationalen) Datenbanksystemen die Daten in Tabellen (Relationen) verwaltet werden, kommen in einem DSMS als grundlegende Datenobjekte Datenströme hinzu. Datenströme können als kontinuierliche Folge von Zeit-Wertepaaren aufgefasst werden. Da Datenströme prinzipiell unendlich sind, müssen sie zur Verarbeitung zwischenzeitlich in Relationen umgewandelt werden. Umgekehrt können Relationen wieder in Datenströme umgewandelt werden (siehe Abbildung). Die Verarbeitung von reinen Relationen kann mit herkömmlichen Methoden stattfinden. Die Umwandlung von Strömen in andere Ströme findet über den Umweg von Relationen statt. Die auf SQL aufbauende Continuous Query Language bietet dazu verschiedene Operatoren an.
Formulierung, Planung und Optimierung von Anfragen
Ebenso wie in herkömmlichen Datenbanksystemen werden Anfragen in einer deklarativen Sprache formuliert und zur Ausführung mit Hilfe eines Anfrageplans optimiert. Da möglichst viele Anfragen gleichzeitig abgearbeitet werden sollen, werden die gespeicherten Anfragen möglichst geschickt kombiniert, so dass Teilanfragen mehrfach verwendet werden können.
Die Komponenten eines Plans sind Operatoren, Warteschlangen und Zustände. Die Operatoren entsprechen den aus herkömmlichen Datenbanken bekannten Operatoren wie beispielsweise die Filterung, Sortierung, Join, mathematische Operatoren etc. sowie die Ein- und Ausgabe von Datenströmen. Die einzelnen Operatoren eines Planes sind durch Warteschlangen verbunden, in die Datenobjekte sequentiell hineingeschrieben und in der gleichen Reihenfolge vom nächsten Operator ausgelesen werden. Als Zwischenergebnisse gibt es Zustände wie beispielsweise der Inhalt eines festgelegten Fensters.
Beispiel
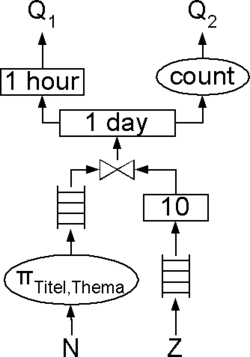
Ein Nachrichtenportal möchte auf seiner Seite aktuelle Nachrichten zu den zurzeit am meisten besprochenen Themen sowie die Nachrichtenmenge eines Tages anzeigen. In einem Datenstrom kommen Nachrichten und in einem anderen Datenstrom als „Zeitgeist“ die aktuell wichtigen Themen an. Jede Nachricht ist einem Thema zugeordnet. Konkret sollen die Nachrichtentitel der letzten Stunde zu den 10 letzten Themen sowie die Anzahl aller dazu passenden Nachrichten innerhalb der letzten 24 Stunden angezeigt werden. In CQL formuliert sind dies zwei Anfragen:
Q1: SELECT Titel FROM Nachrichten N [Range 1 HOUR], Zeitgeist Z [RANGE 10] WHERE N.Thema = Z.Thema
Q2: SELECT COUNT(*) FROM Nachrichten N [RANGE 1 DAY], Zeitgeist Z [RANGE 10]
WHERE N.Thema = Z.Thema
Das DSMS erstellt nun aus diesen Anfragen einen möglichst effizienten Plan, der beispielsweise wie in nebenstehender Abbildung angegeben aussehen könnte. Von den Nachrichten werden zunächst die Titel und Themen projiziert und kommen in eine Warteschlange. Die Themen kommen zunächst in eine Warteschlange und von dort in ein Fenster der Länge 10. Nachrichten und Fenster werden durch einen JOIN-Operator verknüpft und gelangen in ein Fenster das alle Nachrichten eines Tages enthält. Aus diesem Fenster wird über den COUNT-Operator das Ergebnis der Anfrage Q2 ermittelt. Für die Anfrage Q1 schließt sich an das größere Fenster ein kleineres Fenster mit dem Umfang einer Stunde an.
Literatur
- Brian Babcock, Shivnath Babu, Mayur Data, Rajeev Motwani, Jennifer Widom. Models and Issues in Data Stream Systems. In: Proceedings of 21st ACM Symposium on Principles of Database Systems (PODS 2002)
- Don Carney, Ugur Centintemel, Mitch Cherniack, et al.: Monitoring Streams - A New Class of Data Management Applications (PDF; 685 kB). (VLDB 2002)
- Sandra Geisler: Data Stream Management Systems. Dagstuhl Follow-Ups. Vol. 5. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2013.
- Rajeev Motwani, Jennifer Widom, Arvind Arasu, Brian Babcock, Shivnath Babu, Mayur Datar, Gurmeet Manku, Chris Olston, Justin Rosenstein und Rohit Varma: Query Processing, Resource Management, and Approximation in a Data Stream Management System. Stanford, 2002 (CIDR 2003)
- Golab L., Ozsu M.T. Issues in data stream management, ACM SIGMOD Record Volume 32, Issue 2, S. 5–14, Juni 2003.
- Michael Cammert, Christoph Heinz, Jürgen Krämer, Bernhard Seeger: Anfrageverarbeitung auf Datenströmen. Datenbank-Spektrum 11: 5–13, (2004).
- Jürgen Krämer: Continuous Queries over Data Streams - Semantics and Implementation. Dissertation, Philipps-Universität Marburg, (2007).
- Jürgen Krämer, Bernhard Seeger: Semantics and implementation of continuous sliding window queries over data streams. (ACM TODS 2009).
Weblinks
- STREAM, Stream Team Homepage
- AURORA, StreamBase Systems, Inc.
- TelegraphCQ
- NigaraST (Memento vom 13. Oktober 2007 im Internet Archive)
- QStream
- PIPES, RTM Analyzer
- StreamGlobe
- Odysseus
- PipelineDB
- RethinkDB
Einzelnachweise
- Data – English Test Questions (Topics) Files List (englisch) National Institute of Standards and Technology. Abgerufen am 14. Februar 2019.
- Sandra Geisler: Data Stream Management Systems. In: Phokion G. Kolaitis and Maurizio Lenzerini and Nicole Schweikardt (Hrsg.): Dagstuhl Follow-Ups. Band 5. Schloss Dagstuhl--Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany 2013, ISBN 978-3-939897-61-3, S. 275–304, doi:10.4230/DFU.Vol5.10452.275 (dagstuhl.de).