BIRCH
BIRCH (Akronym für balanced iterative reducing and clustering using hierarchies, deutsch etwa balanciertes iteratives Reduzieren und Clustering unter Verwendung von Hierarchien) ist ein Verfahren der Clusteranalyse für große Datenmengen.[1] Ein Vorteil von BIRCH ist die Fähigkeit, neue multivariate Objekte (auch: Beobachtungen oder Instanzen) aus einem Datenstrom effizient zu clustern. Auf der Basis von BIRCH wurde von SPSS das Two-Step-Clustering entwickelt.[2][3]
BIRCH
Die Effizienz beruht auf der Tatsache, dass in den meisten Fällen nur ein Durchlauf über die Datenbank benötigt wird. Zusätzlich behaupten die BIRCH-Entwickler, dass BIRCH der erste Algorithmus im Bereich von Datenbanken ist, der Rauschen (Datenpunkte, die nicht Teil der zugrundeliegenden Struktur sind) behandelt (“first clustering algorithm proposed in the database area to handle ‘noise’ (data points that are not part of the underlying pattern) effectively”[1]) und DBSCAN um zwei Monate schlug.
Probleme mit früheren Verfahren
Frühere Clusterverfahren waren wenig effektiv bei großen Datenmengen und haben den Fall, dass die Daten nicht in den Arbeitsspeicher passen, nicht berücksichtigt. Daher war eine Menge Verwaltungsaufwand notwendig, um Zugriffe auf die Daten außerhalb des Arbeitsspeichers zu minimieren. Für die meisten von BIRCHs Vorgängeralgorithmen gab es keine Heuristik, um zu entscheiden, ob ein Objekt zu einem bestimmten Cluster gehört. Daher war es notwendig auf alle Objekte (oder zumindest alle bis dahin gebildeten Cluster) zuzugreifen.
Vorteile
- Die Zuordnung zu einem Cluster ist eine lokale Entscheidung, d. h., es müssen nicht alle Objekte oder Cluster untersucht werden.
- Der Algorithmus nutzt aus, dass die Objekte nicht gleichmäßig verteilt sind bzw. dass die Objekte für das Clustering nicht alle gleich wichtig sind.
- Er nutzt den zu Verfügung stehenden Arbeitsspeicher voll aus, um die Zugriffskosten auf die Datenbank zu minimieren.
- Er ist eine inkrementelle Methode, die nicht die Kenntnis aller Objekte erfordert. Sie kann damit auch zum Clustern von Datenströmen eingesetzt werden.
Clustering-Algorithmus
Jeder Cluster wird mit folgenden Parametern beschrieben:
- die Anzahl der Objekte im Cluster ,
- den Vektor der Summe der Beobachtungswerte und
- den Vektor der Summe der quadrierten Beobachtungswerte .




Die Parameter nennt man die Clustering-Funktion . Dabei sind und d-dimensionale Vektoren mit d die Anzahl der Variablen (auch: Attribute oder Features). Aus kann das Clusterzentrum als arithmetisches Mittel berechnet werden und der Clusterradius aus und als die totale Varianz der Beobachtungen im Cluster.


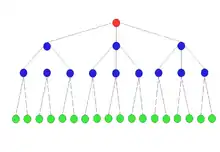
Die Clusterfunktionen werden in einem CF-Baum, einem balancierten Baum mit festgelegter Maximalhöhe, organisiert. Zur Generierung des CF-Baums werden zwei Parameter benötigt:
- der Verzweigungsfaktor B und
- die Schwelle T.
Jeder Nicht-Blatt-Knoten (rot oder blau in der Grafik) enthält höchstens B Einträge in der Form , wobei ein Zeiger auf den i-ten Kind-Knoten und die Clustering-Funktion des damit verbundenen Unterclusters ist. Jeder Blattknoten (grün in der Grafik) enthält höchstens Einträge der Form . Der Clusterradius eines Blattknotens darf den Schellwert T nicht überschreiten. Des Weiteren enthält jeder Blattknoten noch zwei Zeiger Prev und Next und diese verbinden alle Blattknoten als Kette. Die Baumgröße, die Anzahl der Knoten im Baum, hängt von der Schwelle T ab. Ein Knoten darf eine vorher festgelegten Maximalgröße im Arbeitsspeichers nicht überschreiten; damit sind die Maximalwerte P für B bzw. L festgelegt. Der Parameter P wird als Tuningparameter verwendet. Der CF-Baum ist eine sehr kompakte Darstellung der Daten, da jeder Eintrag im CF-Baum selbst ein Cluster ist.





Um ein neues Objekt in den CF-Baum aufzunehmen, wird der abstandsmäßig nächste Clustereintrag im Wurzelknoten (rot in der Grafik) bestimmt. Danach wird in den entsprechenden Kindknoten verzweigt und der Prozess wiederholt, bis ein Clustereintrag in einem Blattknoten gefunden wurde.
- Fall 1: Wenn durch Hinzufügen des Objektes die Bedingung Clusterradius < T nicht verletzt wird, dann kann es hinzugefügt werden. Dann müssen die Clustereinträge in den Knoten zwischen dem Blattknoten und dem Wurzelknoten upgedatet werden.
- Fall 2: Wird der Clusterradius zu groß, dann muss ein neuer Clustereintrag erstellt werden. Ist die Maximalzahl der Clustereinträge überschritten, muss der Blattknoten aufgespalten werden in zwei neue Blattknoten. Dabei werden die Clustereinträge, die am weitesten voneinander entfernt sind, in die beiden neuen Blattknoten übertragen. Jeder Clustereintrag des alten Blattknoten wird dann einem der beiden neuen Blattknoten zugeordnet, je nachdem zu welchem Clustereintrag er näher liegt. Auch hier müssen alle Clustereinträge in den Knoten zwischen den neuen Blattknoten und dem Wurzelknoten upgedatet werden.
Der BIRCH-Algorithmus wird in vier Schritten durchgeführt:
- Der Algorithmus baut aus allen Objekten einen ersten CF-Baum, der in den Arbeitsspeicher passt.
- (optional) Danach wird der Baum verkleinert. Dabei werden auch Ausreißer in den Daten und zu volle Knoten umgeordnet.
- Auf den Clustereinträgen in den Blattknoten wird eine agglomerative hierarchische Clusteranalyse durchgeführt.
- (optional) Durch einen weiteren Lauf über die Datenbank können die Cluster verbessert, z. B. durch Zuordnen von Objekten zu einem anderen Clustereintrag, sowie Ungenauigkeiten korrigiert werden.
Distanzmaße
Die verwendeten Distanzmaße im BIRCH Algorithmus lehnen sich bei der hierarchischen Clusteranalyse an:
- Euklidische Distanz (D0) zwischen den Clusterzentren
- Manhattan-Distanz (D1) zwischen den Clusterzentren
- Average-Linkage (D2): die Distanz zwischen zwei Clustern ist der mittlere Abstand zwischen allen Paaren von Objekten in beiden Clustern, wobei die Objekte aus verschiedenen Cluster kommen
- Average-Group-Linkage (D3): die Distanz zwischen zwei Clustern ist der mittlere Abstand zwischen allen Paaren von Objekten in beiden Clustern, wobei die Objekte auch aus demselben Cluster kommen können
- Wards minimum variance (D4): der Zuwachs der totalen Varianz, also die Differenz der totale Varianz des merged cluster, minus der beiden totalen Varianzen der Einzelcluster.
Alle diese Distanzmaße können effizient nur mit Hilfe Cluster-Funktion und der Lance und Williams Formel berechnet werden.
Auszeichnungen
Der BIRCH-Artikel wurde 2006 mit dem SIGMOD Test of Time Award ausgezeichnet.[4]
Two-Step-Clustering
Für die Statistiksoftware SPSS wurde auf Basis von BIRCH das Two-Step-Clustering entwickelt. Der BIRCH Algorithmus funktioniert nur, wenn die Variablen kontinuierlich sind. In der Praxis enthalten viele Datensätze jedoch auch (oder sogar nur) kategoriale Variablen. Damit der BIRCH Algorithmus auch für solche Datensätze funktioniert, mussten entsprechende Distanzmaße benutzt werden.
Daher bietet SPSS für Clustering, wenn nur kontinuierliche Variablen vorliegen, die euklidische Distanz wie auch in BIRCH an. Ist jedoch eine der Variablen kategorial, dann wird ein Maximum-Likelihood-Ansatz für die Clusterfunktion verfolgt:
- Für jede kontinuierliche Variable wird der Mittelwert und die Standardabweichung gespeichert. Mittelwert und Standardabweichungen können beim Mergen oder Splitten von Clustern durch Pooling effizient berechnet werden.
- Für jede kategoriale Variable werden einfach die absoluten Häufigkeiten für alle Merkmalsausprägungen gespeichert.
Auf dieser Basis wird der Wert der maximierten Likelihood-Funktion berechnet. Für jede kontinuierliche Variable unter der Annahme, dass die Beobachtungen in einem Cluster einer Normalverteilung folgen. Für jede kategoriale Variable unter der Annahme, dass die Beobachtungen in einem Cluster einer Multinomialverteilung folgen. Die Gesamtlikelihood für ein Cluster ergibt sich dann als Produkt der einzelnen maximierten Likelihood-Funktion aller Variablen. Dies unterstellt, dass die einzelnen Variablen unabhängig sind. Obwohl sowohl die Verteilungsannahmen für die Variablen als auch die Unabhängigkeitsbedingung in der Praxis nicht erfüllt sind, haben Tests der Entwickler bei SPSS gute Clusterresulate bei vielen Datensätzen ergeben. Eine Vergleich von Clusterbeispielen in verschiedenen Softwarepaketen ergab jedoch nur ein mäßiges Resultat.[5]

Als Distanz zwischen zwei Clustern wird dann, analog zur Ward minimum variance in BIRCH, der Zuwachs der maximierten Likelihood-Funktionen verwendet.

Einzelnachweise
- T. Zhang, R. Ramakrishnan, M. Livny: BIRCH: an efficient data clustering method for very large databases. In: ACM SIGMOD Record, Vol. 25, No. 2, 1996, S. 103–114.
- The SPSS TwoStep cluster component. (PDF) White paper – technical report. SPSS Inc., Chicago 2001.
- TwoStep Cluster Analysis. Technical report. SPSS Inc., Chicago 2004.
- 2006 SIGMOD Test of Time Award. Archiviert vom Original am 23. Mai 2010. Abgerufen am 10. Oktober 2014.
- J. Bacher, K. Wenzig, M. Vogler: SPSS twostep cluster: A first evaluation. 2004, S. 578–588, Lehrstuhl für Soziologie.