Sensordatenfusion
Als Sensordatenfusion wird allgemein die Verknüpfung der Ausgabedaten mehrerer Sensoren bezeichnet. Ziel ist fast immer die Gewinnung von Informationen besserer Qualität. Die Bedeutung von "bessere Qualität" hängt dabei immer von der Applikation ab: So können beispielsweise die Daten zweier Radaranlagen zur Erfassung eines größeren Detektionsbereiches zusammengefasst (fusioniert) werden. Eine andere Anwendung der Sensordatenfusion besteht beispielsweise in der Fusion von Kamera- und Radardaten, um Objekte zu klassifizieren und die Detektionsleistung des Sensorsystems zu erhöhen.
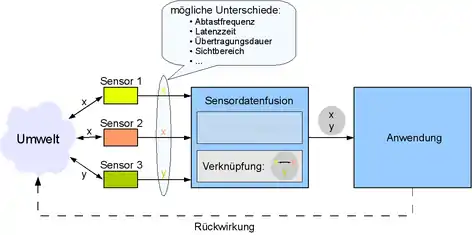
Die Informationsfusion umfasst auch Methoden, andere Informationsquellen als Sensoren zu verknüpfen mit dem Ziel, neues und präziseres Wissen über Messwerte und Ereignisse zu gewinnen.
Die Multi-Sensor-Datenfusion (engl. multi-sensor data fusion, kurz oft auch nur Data Fusion genannt) bezeichnet die Zusammenführung und Aufbereitung von bruchstückhaften und teilweise widersprüchlichen Sensordaten in ein homogenes, für den Menschen verständliches Gesamtbild der aktuellen Situation.
Geschichte
Die theoretischen Ursprünge gehen auf das Ende der sechziger Jahre zurück. Allerdings wurden diese mathematischen Prinzipien erst später auf die Technik übertragen – zunächst im Bereich der Künstlichen Intelligenz (KI). In dieser Disziplin wurde oftmals die Biologie, insbesondere das menschliche Gehirn, als Vorbild zur Modellierung technischer Systeme herangezogen. Berücksichtigt man die Leistungsfähigkeit des Gehirns bei der Fusion von Daten aus den unterschiedlichen Sinnesorganen, so ist es nicht verwunderlich, dass die ersten Ansätze gerade aus der KI stammen.
Ziele und Potentiale der Sensordatenfusion
Bei der Auswahl von Sensoren für eine Anwendung stehen neben den Kosten vor allem Vollständigkeit, Widerspruchsfreiheit, Genauigkeit und Sicherheit der erfassten Daten im Vordergrund. Die Nutzung mehrerer Sensoren inklusive einer geschickten Verknüpfung der Ausgabedaten macht das Erreichen dieser Ziele zumindest potentiell wahrscheinlicher als die Verwendung nur eines Sensors:
- Die Zuverlässigkeit des Gesamtsystems wird durch die Verwendung mehrerer Sensoren in der Regel erhöht. Es ist zum einen leichter, den Ausfall eines Sensors zu erkennen und zum anderen wird die Kompensation des Ausfalls möglich. Ein ausgefallener Sensor bedeutet also noch nicht zwangsweise den kompletten Ausfall des Gesamtsystems.
- Bei Verwendung mehrerer Sensoren – vor allem, wenn sie nach unterschiedlichen Messprinzipien arbeiten – erhöht sich auch die Detektionswahrscheinlichkeit. Das heißt, Phänomene werden vom Gesamtsystem auch dann erkannt, wenn einzelne Sensoren aufgrund von Umweltbedingungen in ihrer Wahrnehmung eingeschränkt oder "blind" sind.
- Ein wichtiges Ziel bei der Verknüpfung von Daten mehrerer Sensoren ist die Erhöhung der Genauigkeit. Voraussetzung ist, dass die Messfehler der Sensoren nicht korreliert sind, gewissen Wahrscheinlichkeitsdichtefunktionen genügen müssen (z. B. Normalverteilung) oder vom System anders identifizierbar und quantisierbar sein müssen. Häufig werden hier Kalman-Filter verwendet und die erreichte finale Genauigkeit kann nach den Regeln der Fehlerfortpflanzung ermittelt werden.
- Die Sichtbereiche von Sensoren sind üblicherweise beschränkt, die Verwendung mehrerer Sensoren vergrößert den Sichtbereich des Gesamtsystems entsprechend.
- Die Auflösung von Mehrdeutigkeiten ist bei der Verwendung mehrerer Sensoren einfacher.
- Zusätzliche Sensoren liefern oft zusätzliche Informationen und erweitern so das Wissen des Gesamtsystems.
- Mehrere Sensoren, die dasselbe Phänomen im selben Sichtbereich erfassen, erhöhen effektiv die Messrate.
- Sensordatenfusion kann auch zur Kostenreduktion verwendet werden. In diesem Fall ersetzen mehrere, in Summe günstigere Sensoren einen besonders teuren Sensor.
Methoden
In den letzten Jahren haben sich einige systematische Fusionsansätze herauskristallisiert, von denen an dieser Stelle die wichtigsten kurz erörtert werden sollen. Dafür sei zunächst das Fusionsproblem als Parameterschätzmodell formuliert. Von einer Quelle wird ein Parameter emittiert, der eine Realisierung der Zufallsgröße darstellt. Bei der Zielgröße kann es sich um eine Messgröße handeln, aber auch um latente Konstrukte, die keinen Anspruch auf physikalische Realität haben müssen. Im letzteren Fall kann die Größe im platonischen Sinne als eine Idealisierung der Sensordaten verstanden werden, bei der gewünschte oder bekannte Eigenschaften der Zielgröße selbst berücksichtigt werden. Mit Hilfe mehrerer Sensoren werden die Daten erfasst, welche ebenfalls als Realisierungen eines Zufallsprozesses aufzufassen sind. Die Messung entspricht einer Abbildung , die sich mathematisch mittels der bedingten Wahrscheinlichkeitsverteilung (WV) von beschreiben lässt. Im Folgenden sei angenommen, dass es sich bei und um kontinuierliche Größen handelt, die WV anhand einer Wahrscheinlichkeitsdichtefunktion beschrieben wird.








Klassische Statistik
Der klassischen Statistik liegt eine empirische, frequentistische Interpretation von Wahrscheinlichkeiten zugrunde, bei der zwar die Sensordaten als Zufallsgrößen angesehen werden, nicht jedoch die Messgröße selbst. Die Schätzung von anhand der Sensordaten stützt sich auf die sogenannte Wahrscheinlichkeitsdichtefunktion , die dafür als Funktion von aufgefasst und maximiert wird:


Der zugehörige Wert heißt Maximum-Likelihood- oder ML-Schätzwert.

Bayessche Statistik
In der Bayesschen Statistik wird auch die Messgröße als Realisierung einer Zufallsgröße aufgefasst, weshalb die a priori Wahrscheinlichkeitsdichtefunktion zur Bestimmung der a posteriori Wahrscheinlichkeitsdichtefunktion herangezogen wird:



Durch Maximierung dieser Gleichung erhält man die Maximum a posteriori (MAP) Lösung für den zu schätzenden Parameter :

Diese Vorgehensweise hat den wesentlichen Vorteil, dass sie die Angabe der WV für den zu schätzenden Parameter bei gegebenen Messdaten zulässt, wohingegen die Klassische Vorgehensweise lediglich die Angabe der WV für die Sensordaten bei gegebenem Parameterwert erlaubt.
Dempster-Shafer-Evidenztheorie
Die Evidenztheorie wird oftmals als eine Erweiterung der Wahrscheinlichkeitstheorie oder als eine Verallgemeinerung der Bayesschen Statistik betrachtet. Sie basiert auf zwei nichtadditiven Maßen – dem Grad des Dafürhaltens (englisch: degree of belief) und der Plausibilität – und bietet die Möglichkeit, Ungewissheit detaillierter auszudrücken. In praktischen Aufgabenstellungen ist es jedoch nicht immer möglich, das verfügbare Wissen über die relevanten Größen derart differenziert darzustellen und somit die theoretischen Möglichkeiten dieses Ansatzes voll auszuschöpfen.
Fuzzy-Logik
Die Fuzzy-Logik basiert auf der Verallgemeinerung des Mengenbegriffes mit dem Ziel, eine unscharfe Wissensrepräsentation zu erlangen. Dies erfolgt anhand einer sogenannten Zugehörigkeitsfunktion, die jedem Element einen Grad der Zugehörigkeit zu einer Menge zuordnet. Aufgrund der Willkür bei der Wahl dieser Funktion stellt die Fuzzy-Mengentheorie eine sehr subjektive Methode dar, die sich daher besonders zur Repräsentation von menschlichem Wissen eignet. In der Informationsfusion werden Fuzzy-Methoden eingesetzt, um Ungewissheit und Vagheit im Zusammenhang mit den Sensordaten zu handhaben.
Neuronale Netze
Eine weitere Methode zur Fusion von Information sind die künstlichen Neuronalen Netze (KNN). Diese können auf durch Software simulierten Verarbeitungseinheiten basieren, die zu einem Netzwerk verschaltet werden, oder in Hardware realisiert sein, um bestimmte Aufgaben zu lösen. Ihr Einsatz ist besonders vorteilhaft, wenn es schwer oder nicht möglich ist, einen Algorithmus zur Kombination der Sensordaten zu spezifizieren. In solchen Fällen wird dem neuronalen Netz in einer Trainingsphase mit Hilfe von Testdaten das gewünschte Verhalten beigebracht. Nachteilig an neuronalen Netzen sind die mangelnden Möglichkeiten zur Einbindung von a priori Wissen über die an der Fusion beteiligten Größen.
Nachteile und Probleme der Sensordatenfusion
Neben den genannten Vorteilen existieren aber auch Probleme, die die Verwendung mehrerer Sensoren und Verknüpfung ihrer Ausgabedaten mit sich bringen können:
- Höhere Datenraten belasten die Kommunikationssysteme. Die Komplexität der Kommunikation steigt an, ebenso wie der Zeitbedarf für die Übertragung und die Verarbeitung.
- Die Komplexität des Gesamtsystems steigt an. Dies erhöht die Wahrscheinlichkeit von Fehlern bei Spezifikation und Implementierung des Systems.
- Die Integration der Sensoren (zum Beispiel in ein Fahrzeug) wird mit steigender Anzahl immer schwieriger. Dies liegt am Platzbedarf, an der begrenzten Anzahl der für die Messung günstigen Einbauorte und der notwendigen Kommunikations- und Versorgungseinrichtungen.
- Falls nicht mehrere, günstige Sensoren einen teuren Sensor ersetzen sollen, steigen die Kosten.
- Da die Messungen der einzelnen Sensoren typischerweise zu unterschiedlichen Zeitpunkten stattfindet und auch die Abtastzeit oft unterschiedlich ist, ergibt sich die Notwendigkeit der Synchronisation der Daten. Dies führt zu zusätzlichen Aufwänden in Software und Hardware (zum Beispiel Echtzeit-fähige Bussysteme).
Unterscheidungskriterien
Ansätze zur Sensordatenfusion lassen sich nach unterschiedlichen Kriterien unterscheiden:
Funktionalität
Brooks und Iyengar (1997) unterscheiden vier Arten der Sensordatenfusion hinsichtlich ihrer Funktion:
- Eine komplementäre Fusion hat das Ziel, die Vollständigkeit der Daten zu erhöhen. Unabhängige Sensoren betrachten hierfür unterschiedliche Sichtbereiche und Phänomene oder messen zu unterschiedlichen Zeiten.
- Bei der konkurrierenden Fusion erfassen Sensoren gleichzeitig denselben Sichtbereich und liefern Daten gleicher Art. Die (oft gewichtete) Verknüpfung solcher, "konkurrierender" Daten kann die Genauigkeit des Gesamtsystems erhöhen.
- Reale Sensoren erbringen die gewünschten Informationen oft nicht allein. So ergibt sich beispielsweise die benötigte Information erst aus dem Zusammensetzen der verschiedenen Ausgabedaten. Eine solche Fusion wird als kooperative Fusion bezeichnet.
- Ein Spezialfall ist die unabhängige Fusion. Streng genommen liegt keine echte Sensordatenfusion vor, weil hier Daten unterschiedlicher Sensoren nicht verknüpft, aber in einem gemeinsamen System verarbeitet werden.
In realen Systemen kommen typischerweise Mischformen bzw. die Kombination verschiedener Fusionstypen zum Einsatz (manchmal auch als hybride Fusion bezeichnet).
Ebenen der Sensordatenfusion
Hall & Llinas (1997) unterscheiden drei Ebenen der Sensordatenfusion:
- Bei der data fusion werden die rohen Sensordaten vor weiteren Signalverarbeitungsschritten miteinander verschmolzen. Beispiel: Geräuschunterdrückung mit Hilfe von Beamforming.
- Bei der feature fusion erfolgt vor der Verschmelzung eine Extraktion eindeutiger Merkmale. Die neu kombinierten Merkmalsvektoren werden im Anschluss weiterverarbeitet. Beispiel: Audiovisuelle Spracherkennung. Hierbei werden akustische und visuelle Merkmalsvektoren kombiniert um durch die Kombination von Sprachlauten und Lippenbewegungen auch in lauten Umgebungen oder bei gestörten Kanälen akzeptable Erkennraten zu erzielen.
- Bei der decision fusion erfolgt die Zusammenführung erst nachdem alle Signalverarbeitungs- und Mustererkennungsschritte durchgeführt wurden.
Fusionsarchitektur
Nach Klein (1999) lassen sich Fusionsansätze nach folgenden Architekturtypen unterscheiden:
- Bei der Sensor Level Fusion verarbeiten dem eigentlichen Fusionsmodul vorgeschaltete Module die Sensordaten und leiten sie dann an das Fusionsmodul weiter. Ein Beispiel für eine solche Vorverarbeitung ist die Merkmalsextraktion. Die Menge an zu fusionierenden Daten ist in einer solchen Architektur durch die Vorverarbeitungsschritte in der Regel reduziert. Die Fusion von Daten geschieht dann entweder auf der Ebene "feature fusion" oder "decision fusion".
- Dienen dem Fusionsmodul nur minimal vorverarbeitete Sensordaten als Eingangsdaten, so spricht man von einer Central Level Fusion. Weitergehende Signalverarbeitungsschritte erfolgen erst nach der Fusion, sodass die Ebene der Fusion typischerweise "data fusion" ist. Die Menge an zu fusionierenden Daten ist hier kaum gegenüber der Menge der Sensordaten reduziert.
- Bei Mischformen kommen Elemente von Central Level Fusion und Sensor Level Fusion zum Einsatz. Es werden also parallel sowohl vorverarbeitete Daten als auch Daten direkt vom Sensor fusioniert. Oft kommt hier die Bezeichnung Hybrid Fusion zum Einsatz, was Verwechslungen mit der Unterscheidung nach Funktionalität möglich macht.
Weitere Unterscheidungskriterien
Die Literatur beschreibt noch weitere Arten von Fusionstypen, hier nur kurz aufgeführt:
- Sensornetzwerke, sowohl statisch als auch dynamisch
- Homogene und heterogene Anordnungen, also die Verwendung von Sensoren gleichen oder unterschiedlichen Typs
- Algorithmenfusionen
Werkzeuge
Die Verknüpfung der Sensordaten findet meist innerhalb von Rechnern oder Steuergeräten statt. Es gibt sehr viele Algorithmen bzw. mathematische Verfahren, um Sensordaten aus verschiedenen Quellen miteinander zu fusionieren. Einige Beispiele sind:
- Klassifikationsverfahren
- stochastische Verfahren
- Kalman-Filter
- logische Verknüpfungen
- auf Regeln basierende Verfahren
Multi-Sensor Datenfusion
Das im Lauf der Daten-Fusion entstehende, sog. Lagebild stellt dann die Basis für einen weitergehenden fundierten Entscheidungsprozess dar. Das originäre Einsatzgebiet von Multi-Sensor-Data-Fusion-Systemen liegt im Bereich militärischer Führungssysteme (C3I), jedoch halten die dort entwickelten Systemkonzepte in zunehmendem Maß auch Einzug in die unternehmensweite Controlling-Systeme.
Anstatt des Begriffes Multi-Sensor-Datenfusion findet man in der englischsprachigen Fachliteratur auch die abgekürzten Begriffe Sensor Fusion, Data Fusion und Information Fusion als Überbegriff, der explizit auch andere Datenquellen als Sensoren einbezieht. Im Gegensatz zu dem im Kontext Data Warehouse auftretenden engeren Datenfusionsbegriff, der sich mit der rein informationstechnischen Zusammenführung von zwar lückenhaften, aber doch gleich/ähnlich strukturierten Daten beschäftigt, ist der Multi-Sensor-Datenfusionsansatz in folgenden Aspekten wesentlich weitreichender:
a) Nicht kommensurable Datenquellen: Ein umfassender Lageüberblick erfordert oft die Integration von Sensoren und Datenquellen, die nicht nur hinsichtlich ihrer Datenstruktur, sondern auch hinsichtlich ihres Inhalts höchst unterschiedlich sind. Eine Reihe von Verarbeitungsschritten ist dabei notwendig, um die Daten auf ein semantisches Niveau zu heben, auf dem sie tatsächlich kombinierbar sind. So müssen beispielsweise Radardaten erst zu Flugspuren (Tracks) aufbereitet und mit Informationen zur Identifikation kombiniert werden, bevor sie tatsächlich mit statischen Quellen wie etwa einem in einer Datenbank gespeicherten Flugplan verglichen werden können.
b) Information Aging: Die Frequenz der eingehenden Daten ist in der Regel unterschiedlich, das heißt, dass ein Multi-Sensor-Datenfusionssystem in der Lage sein muss, Informationen zu verarbeiten, die unterschiedlich alt sind. Das Alter der Daten spielt dabei nicht nur eine Rolle hinsichtlich der Frage, ob und wie relevant sie für die aktuelle Situation sind. Vielmehr müssen alte Daten oft in die Gegenwart extrapoliert werden, um zu entscheiden, ob die aktuellen Beobachtungen widersprüchlich zu alten Daten sind oder ob eine Entwicklung erkennbar ist. So muss beispielsweise entschieden werden, ob es sich bei von zwei Radarstationen im Abstand von 10 bis 15 sec an unterschiedlichen Positionen entdeckten Objekten um dasselbe Flugzeug handelt, das nur zum Zeitpunkt der zweiten Beobachtung bereits an einer anderen Position ist, oder ob von zwei unterschiedlichen Flugzeugen auszugehen ist.
c) Informationsgewichtung: Je nach der Auslegung der Sensorik und dessen lokaler Position können Informationen des jeweiligen Sensors mit unterschiedlicher Gewichtung ins Lagebild eingehen. So ist z. B. davon auszugehen, dass bei entsprechender Ausstattung die Bordsensoren eines Abfangjägers ein verlässlicheres Bild von der Nahsituation liefern, als Radarsysteme aus einer weiteren Distanz. Bei der Informationsgewichtung müssen deshalb unterschiedlichste Faktoren, wie Systemausstattung, Messbereiche, Scan-Frequenzen, aktuelle Positionen etc. verteilter Sensorsysteme einbezogen werden. Auf höherem Niveau geschieht diese Gewichtung auch bei der Harmonisierung von bereits fusionierten Daten, die mit anderen Führungssystem ausgetauscht werden.
d) Informations-Interpretation: Ein nach dem Prinzip "Die Gesamtheit ist mehr als die Summe der Einzelteile" aufgestelltes Lagebild erfordert die teilweise Interpretation von eingehenden Informationen. Einerseits muss dabei in Betracht gezogen werden, mit welcher qualitativen Güte die eingesetzte Sensorik in der Lage ist, Informationen zu liefern (manche Radarsysteme schätzen etwa die Geschwindigkeit eines Objektes, andere können diese messen; hochauflösende Laser-Entfernungsmesser werden akkuratere Informationen liefern als Radars). Andererseits muss berücksichtigt werden, in welchem Maße eine Verschiebung der Informations-Gewichtung das Lagebild verändert und welche potentielle Gefahr eine fehlerhafte Gewichtung verursachen könnte.
Anwendungsbeispiele
Inzwischen ist der Einsatz sehr breit und umfasst viele unterschiedliche Disziplinen – darunter Robotik, Mustererkennung, Medizin, zerstörungsfreie Prüfung, Geowissenschaften, Verteidigung und Finanzen. Obwohl die Literatur dazu sehr umfangreich ist, sind viele der darin angegebenen Verfahren jedoch wenig systematisch.
Ein weiteres Anwendungsgebiet sind Fahrerassistenzsysteme. Daten von Kameras werden hier zum Beispiel mit den Positionsangaben der Radarsensoren validiert, um Objekte/Hindernisse sicher erkennen zu können. In manchen Systemen erweitert man den Sichtbereich des Fernbereichs-Radars mit Radaren für den Nahbereich, um einen größeren Sichtbereich zu erhalten und zusätzliche Funktionen anbieten zu können.
Die Odometrie des europäischen Zugbeeinflussungssystems ETCS nutzt Sensordatenfusion, um die spezifischen Schwächen einzelner Sensortypen zur sicheren Wegmessung auszugleichen.
Literatur Allgemein
- D. L. Hall, J. Llinas: An introduction to multisensor data fusion. In: Proceedings of IEEE. Band 85, 1997, OCLC 926654310, S. 6–23.
- Richard R. Brooks, Sundararaja S. Iyengar: Multi-Sensor Fusion: Fundamentals and Applications with Software. Prentice Hall PTR, 1997, ISBN 0-13-901653-8.
- Lawrence A. Klein: Sensor Data Fusion. Artech House, 1999, ISBN 0-8194-3231-8.
- Yaakov Bar-Shalom (Hrsg.): Multitarget-multisensor tracking : applications and advances. Band I, Artech House, 1989, ISBN 0-89006-377-X.
Literatur zu Luftfahrtanwendungen
- J. Wendel: Integrierte Navigationssysteme – Sensordatenfusion, GPS und Inertiale Navigation. München 2007, ISBN 978-3-486-58160-7.
- S. Winkler: Zur Sensordatenfusion für integrierte Navigationssysteme unbemannter Kleinstflugzeuge. Shaker Verlag, Aachen 2007, ISBN 978-3-8322-6060-6.
Siehe auch
Weblinks
- http://www.elsevier.com/locate/inffus Information Fusion Journal
- http://www.informationsfusion.de Sensor- und Informationsfusion, Karlsruher Institut für Technologie (KIT)
- http://www.mrt.kit.edu/res3.php Informationsfusion, Karlsruher Institut für Technologie (KIT)
- http://www.isif.org/ International Society of Information Fusion