Semantic Web
Das Semantic Web erweitert das Web, um Daten zwischen Rechnern einfacher austauschbar und für sie einfacher verwertbar zu machen; so kann beispielsweise das Wort „Bremen“ in einem Webdokument um die Information ergänzt werden, ob hier der Begriff des Schiffs-, Familien- oder Stadtnamens gemeint ist. Diese zusätzlichen Informationen explizieren die sonst nur unstrukturiert vorkommenden Daten. Zur Realisierung dienen Standards zur Veröffentlichung und Nutzung maschinenlesbarer Daten (insbesondere RDF). Während Menschen solche Informationen aus dem gegebenen Kontext schließen können (aus dem Gesamttext, über die Art der Publikation oder der Rubrik in selbiger, Bilder etc.) und derartige Verknüpfungen unbewusst aufbauen, muss Maschinen dieser Kontext erst beigebracht werden; hierzu werden die Inhalte mit weiterführenden Informationen verknüpft. Das Semantic Web beschreibt dazu konzeptionell einen „Giant Global Graph“ (engl. ‚gigantischer globaler Graph‘). Dabei werden sämtliche Dinge von Interesse identifiziert und mit einer eindeutigen Adresse versehen als Knoten angelegt, die wiederum durch Kanten (ebenfalls jeweils eindeutig benannt) miteinander verbunden sind. Einzelne Dokumente im Web beschreiben dann eine Reihe von Kanten, und die Gesamtheit all dieser Kanten entspricht dem globalen Graphen.
Beispiel
Im folgenden Beispiel wird im Text „Paul Schuster wurde in Dresden geboren“ auf einer Webseite der Name einer Person mit dessen Geburtsort verknüpft. Das Fragment eines HTML-Dokuments zeigt, wie in RDFa-Syntax unter Verwendung des schema.org-Vokabulars und einer Wikidata-ID ein kleiner Graph beschrieben wird:
<div vocab="http://schema.org/" typeof="Person">
<span property="name">Paul Schuster</span> wurde in
<span property="birthPlace" typeof="Place" href="http://www.wikidata.org/entity/Q1731">
<span property="name">Dresden</span>
</span> geboren.
</div>

Das Beispiel definiert folgende fünf Tripel (dargestellt im Turtle-Format). Dabei repräsentiert jedes Tripel eine Kante (im Englischen edge genannt) im sich ergebenden Graphen: Der erste Teil des Tripels (das Subjekt) ist der Name des Knotens, wo die Kante beginnt, der zweite Teil des Tripels (das Prädikat) die Art der Kante, und der dritte und letzte Teil des Tripels (das Objekt) entweder der Name des Knotens, in dem die Kante endet, oder ein Literalwert (z. B. ein Text, eine Zahl usf.).
_:a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Person> .
_:a <http://schema.org/name> "Paul Schuster" .
_:a <http://schema.org/birthPlace> <http://www.wikidata.org/entity/Q1731> .
<http://www.wikidata.org/entity/Q1731> <http://schema.org/itemtype> <http://schema.org/Place> .
<http://www.wikidata.org/entity/Q1731> <http://schema.org/name> "Dresden" .
Die Tripel ergeben den nebenstehenden Graphen (obere Abbildung).
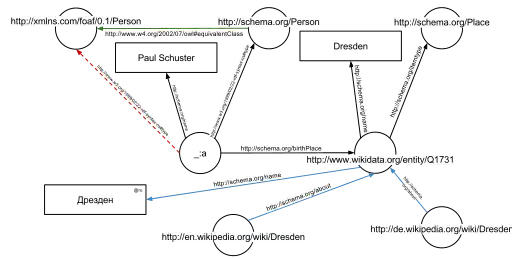
Einer der Vorteile, URIs zu verwenden, ist, dass diese über das Protokoll HTTP aufgelöst werden können und oft ein Dokument zurückgeben, welches der gegebene URI weiter beschreibt (das ist das sogenannte Prinzip Linked Open Data). Im gegebenen Beispiel etwa kann man die URIs der Knoten und Kanten (z. B. http://schema.org/Person, http://schema.org/birthPlace. http://www.wikidata.org/entity/Q1731) alle auflösen und erhält dann weitergehende Beschreibungen, z. B. dass Dresden eine Stadt in Deutschland ist, oder dass eine Person auch fiktiv sein kann.
Der nebenstehende Graph (untere Abbildung) zeigt das vorhergehende Beispiel, angereichert um (einige wenige beispielhafte) Tripel aus den Dokumenten die man erhält, wenn man http://schema.org/Person (grüne Kante) und http://www.wikidata.org/entity/Q1731 (blaue Kanten) auflöst.
Zusätzlich zu den explizit in den Dokumenten gegebenen Kanten kann man auch weitere Kanten automatisch schlussfolgern: das Tripel
_:a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Person> .
aus dem ursprünglichen RDFa-Fragment, zusammen mit dem Tripel
<http://schema.org/Person> <http://www.w3.org/2002/07/owl#equivalentClass> <http://xmlns.com/foaf/0.1/Person> .
aus dem Dokument, welches man in http://schema.org/Person fand (in der Grafik die grüne Kante), erlauben es unter der OWL-Semantik das folgende Tripel zu schlussfolgern (in der Grafik, die gestrichelte rote Kante):
_:a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> .
Begriff
Der Name Semantic Web (deutsch Semantisches Netz) hat oft zu Missverständnissen und Diskussionen geführt. Zahlreiche andere Begriffe wurden vorgeschlagen, die aber letztlich alle dasselbe Ziel haben:
- In Anlehnung an den Begriff Web 2.0 spricht man nach John Markoff vom Web 3.0, wenn zu den Konzepten des Web 2.0 noch die Konzepte des Semantic Web hinzukommen.[1][2]
- In Abgrenzung an den Begriff WWW hat Tim Berners-Lee, der Begründer des WWW, den Begriff Giant Global Graph (GGG) eingeführt, welcher die Struktur des Semantic Web als weltumspannende verknüpfte Graphstruktur betont.[3]
- Teilweise in Abgrenzung zum als schwergewichtig und kompliziert gesehenen Semantic Web wurde der Begriff Linked Open Data um 2007 eingeführt.
- Das W3C-Konsortium selbst wechselte im Dezember 2013 zum neuen Begriff Web of Data, Web der Daten
Grundlagen
Das Konzept beruht auf einem Vorschlag von Tim Berners-Lee, dem Begründer des World Wide Web: das Semantic Web ist eine Erweiterung des herkömmlichen Webs, in der Informationen mit eindeutigen Bedeutungen versehen werden, um die Arbeit zwischen Mensch und Maschine zu erleichtern („The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation“).[4] Das Semantic Web baut auf existierenden Web-Standards und Arbeiten im Bereich Wissensrepräsentation auf.
„Klassisches“ Web
Das „klassische“ (nur auf Text basierte) Web – also das Web der Dokumente, wie es von Tim Berners-Lee eingeführt und seitdem kontinuierlich erweitert wurde – basiert auf einer Reihe von Standards:
- HTML als Auszeichnungssprache für den Inhalt üblicherweise textueller Dokumente,
- URLs als Notation für Adressen von beliebigen Dokumenten (also Dateien) im Web und
- HTTP als Protokoll, um diese Dokumente abzurufen und zu bearbeiten.
Sehr bald wurden auch Bilder, in Formaten wie GIF und JPEG, in HTML-Dokumente eingebettet und ausgetauscht. Bereits im ursprünglichen Vorschlag von Tim Berners-Lee, von 1989, wies er darauf hin, dass diese Standards nicht nur zum Austausch von ganzen Dokumenten, sondern auch zum Austausch von miteinander vernetzten Daten verwendet werden können. Jedoch, wie auch andere Teile des Vorschlags (z. B. dass alle Seiten im Web leicht zu editieren sein sollten), ging das zunächst unter.
Somit sind die meisten Inhalte im heutigen Web, z. B.: natürlichsprachlicher Text, Bilder u. Videos, größtenteils unstrukturiert in dem Sinne, dass in der Struktur eines (klassischen) HTML-Dokumentes nicht ausdrücklich angegeben ist, ob es sich bei einem Stückchen Text um: einen Vornamen oder Nachnamen, den Namen einer Stadt oder eines Unternehmens, oder eine Adresse handelt. Das erschwert die maschinelle Verarbeitung der Inhalte, die angesichts der rasch wachsenden Menge an zur Verfügung stehenden Informationen wünschenswert wäre.
Die Standards des Semantic Webs sollen Lösungen für dieses Problem anbieten: einzelne Teile von Texten können nicht nur für ihr Aussehen formatiert, sondern auch mit ihrem Inhalt / ihrer Bedeutung ausgezeichnet werden, und ganze Texte strukturiert werden, so dass es Computern ermöglicht wird, Daten einfach aus den Dokumenten auszulesen.
Durch die Verwendung des gemeinsamen RDF-Datenmodells und einer standardisierten Ontologiesprache können zudem die Daten weltweit integriert und sogar implizites Wissen aus den Daten geschlossen werden.
Metadaten
HTML-Dokumente erhielten bereits die Möglichkeit, eine begrenzte Zahl von Metadaten festzuhalten – in dem Fall Daten über die jeweiligen Dokumente.
Mitte der 1990er Jahre begann Ramanathan V. Guha (ein Schüler McCarthys und Feigenbaums und ein Mitarbeiter des Cyc-Projektes) die Arbeit am Meta Content Framework (MCF), zunächst bei Apple und ab 1997 bei Netscape. Ziel des MCF war es, eine allgemeine Grundlage für Metadaten zu schaffen. Zur selben Zeit wurde beim Web-Standard Konsortium W3C an XML gearbeitet. Die Idee von MCF wurde dann mit der Syntax von XML verbunden, um die erste Version von RDF zu ergeben.
Der erste weit verbreitete Einsatz von RDF fand sich in RSS, einem Standard, um Feeds darzustellen und zu abonnieren. Dies fand vor allem in Blogs Anwendung, die dann durch RSS Reader abonniert werden konnten.
Obwohl zunächst meistens nur an Metadaten gedacht wurde – insbesondere Metadaten zu im Web vorhandenen Dokumenten, die dann von Indizier- und Suchmaschinen ausgewertet werden können – ist mit der Entwicklung von RDF und spätestens mit dem Artikel im Scientific American 2001 diese Beschränkung weggefallen. RDF ist ein Standard zum Austausch von Daten und keineswegs auf Metadaten beschränkt. Dennoch wird in vielen Texten zum Semantic Web veraltet nur von Metadaten gesprochen.
Die meisten Syntaxen zum Austausch von RDF – NTriples, N3, RDF/XML, JSON-LD – sind gar nicht in der Lage, direkt im Text zum Auszeichnen von Textstellen verwendet zu werden (im Gegensatz zu RDFa).
Entsprechend fand auch die Erweiterung von Uniform Resource Locators (URLs), die zum Adressieren von Dokumenten im Web verwendet werden, hin zu Uniform Resource Identifiers (URIs) statt, die zum Identifizieren beliebiger Sachen verwendet werden können, insbesondere also auch von Sachen, die in der Welt (z. B. Häuser, Personen, Bücher) oder auch nur abstrakt sind (z. B. Ideen, Religionen, Beziehungen).
Wissensrepräsentation
Ursprünge des Semantic Web liegen unter anderem im Forschungsgebiet der Künstlichen Intelligenz, insbesondere dem Unterbereich Wissensrepräsentation. Bereits MCF baute systematisch auf einer Prädikatenlogik auf.
Ursprünglich waren die Attribute für Metadaten in den Dokumenten eng begrenzt: in HTML war es möglich, Schlüsselwörter, Erscheinungsdaten, Autoren etc. anzugeben. Dieser Bereich wurde dann durch die Dublin-Core-Gruppe stark erweitert und systematisch ausgebaut, wobei sehr viel Erfahrungen aus den Bibliothekswissenschaften einflossen. Doch auch das führte zu einem begrenzten Vokabular, d. h. zu einer kleinen Menge von verwendbaren Attributen und Typen. Ein so kleines Vokabular kann mit vergleichsweise wenig Aufwand von einem Computerprogramm bearbeitet werden.
Ein Ziel des Semantic Webs war es aber, beliebige Daten darstellen zu können. Dazu war es notwendig, das Vokabular erweitern zu können, also beliebige Beziehungen, Attribute und Typen zu deklarieren. Um die Deklaration dieser Vokabulare, auch Ontologien genannt, auf einer soliden formalen Basis aufzubauen, entstanden unabhängig voneinander zwei Sprachen, die in den USA von der DARPA finanzierte DARPA Agent Markup Language (DAML) und die in der EU vom Forschungsrahmenprogramm finanzierte Ontology Inference Layer (OIL) in Europa. Beide bauten auf früheren Ergebnissen aus dem Bereich Wissensrepräsentation auf, insbesondere Frames, semantische Netze, Conceptual Graphs und Beschreibungslogiken. Die beiden Sprachen wurden um 2000 schließlich in einem gemeinsamen Projekt unter Federführung des W3C vereinigt, zunächst als DAML+OIL, und schließlich die 2004 veröffentlichte Ontologiesprache Web Ontology Language (OWL).
Standards
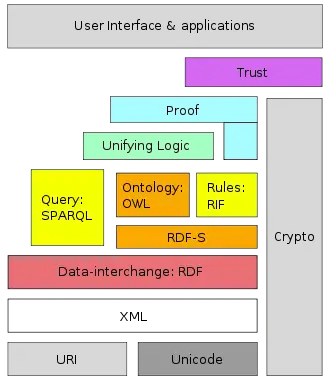
Zur Realisierung des Semantic Webs dienen Standards zur Veröffentlichung und Nutzung maschinenlesbarer Daten. Zentrale Standards dabei sind:
- URIs in der doppelten Rolle zur Identifizierung von Entitäten und zum Verweisen auf weitergehende Daten dazu
- RDF als gemeinsames Datenmodell zur Repräsentation von Aussagen
- RDFS zur Deklaration des Vokabulars, welches in RDF verwendet wird
- OWL zur formalen Definition des in RDFS deklarierten Vokabulars in einer Ontologie
- RIF für die Darstellung von Regeln
- SPARQL als Anfragesprache und -protokoll
- eine Reihe von verschiedenen Syntaxen um RDF-Graphen auszutauschen:
Bezeichner: URIs
URIs – engl. Uniform Resource Identifier – erfüllen eine zweifache Aufgabe im Semantic Web: Einerseits dienen sie als eindeutige, weltweit gültige Namen für sämtliche Sachen, die im Semantic Web bezeichnet werden. D. h., dass derselbe URI in verschiedenen Dokumenten ein und dieselbe Sache bezeichnet. Das erlaubt es, Daten einfach zusammenzufügen wie auch eindeutig zu übersetzen. Andererseits kann der URI auch als Adresse dienen, unter der man weitergehende Daten zu der bezeichneten Ressource abrufen kann, im Fall eines Dokuments das Dokument selbst. In diesem Fall ist der URI nicht von einer URL zu unterscheiden.
Obwohl jeder URI weltweit genau eine Sache identifiziert, ist es umgekehrt nicht der Fall, dass eine Sache weltweit genau von einem URI identifiziert wird – im Gegenteil, oft haben Sachen wie die Stadt Bremen, die Person Angela Merkel oder der Film Das Fenster zum Hof viele verschiedene URIs. Um die Verknüpfung zwischen diesen verschiedenen URIs zu vereinfachen, hat man verschiedene Möglichkeiten, um zu sagen, dass zwei URIs dieselbe Sache bezeichnen, z. B. durch Schlüssel oder durch explizites Verknüpfen zweier URIs mit der sameAs-Relation aus dem OWL-Vokabular.
Datenmodell: RDF
RDF als Datenmodell basiert auf Tripeln aus Subjekt, Prädikat und Objekt. Eine Menge von RDF-Tripeln ergeben einen RDF-Graphen. Hierbei werden das Subjekt und das Objekt als Knoten betrachtet, und das Prädikat ist der Name der gerichteten Kante von Subjekt zu Objekt. Prädikate sind immer URIs, Subjekte sind üblicherweise URIs, können aber auch unbenannte Knoten (en. blank nodes) sein, und Objekte sind entweder URIs, unbenannte Knoten oder Literale. Literale sind z. B. Texte, Zahlen, Datumsangaben etc.
Unbenannte Knoten sind im Gegensatz zu mit URIs benannten Knoten nur lokal benannt, d. h., sie haben keinen global eindeutigen Namen. Wenn zwei verschiedene RDF-Graphen je einen Knoten mit dem URI http://www.wikidata.org/entity/Q42 haben, dann bezeichnet dieser Knoten per Standard dieselbe Sache. So kann ein zweiter Graph weitergehende Aussagen über dieselben Sachen machen wie der erste Graph und erlaubt es so, jedem alles über alles zu sagen. Wird jedoch in einem RDF-Graphen ein unbenannter Knoten verwendet, kann ein zweiter Graph nicht direkt Aussagen über den unbenannten Knoten des ersten Graphen machen.
Vorteile von RDF-Graphen sind, dass sie sehr regelmäßig sind – es sind nur Mengen von Tripeln – und dass sie sehr einfach zusammenzufügen sind. Zwei Graphen ergeben einen Graphen, indem man einfach deren Mengen von Tripeln vereinigt. In manchen tripelbasierten Syntaxen wie NTripel bedeutet das, dass man einfach die Dateien aneinanderhängen kann.
Definition der Vokabulare: RDFS und OWL
Das RDF-Schema (RDFS, zunächst „RDF Vocabulary Description Language“ dann aber 2014 in „RDF Schema“ umbenannt) wurde definiert, um Klassen von Sachen und deren Eigenschaften zu definieren und diese dann in formale Beziehungen zueinander zu setzen. Zum Beispiel kann mit RDFS ausgesagt werden, dass die Eigenschaft http://purl.org/dc/elements/1.1/title im Englischen title und im Deutschen Titel genannt wird. Zudem kann eine Beschreibung aussagen, dass diese Eigenschaft für den Titel eines Buches benutzt werden soll. Neben diesen natürlichsprachlichen Beschreibungen, erlaubt RDFS es auch, formale Aussagen zu treffen: z. B. dass alles, was die genannte Eigenschaft hat, zur Klasse http://example.org/Buch gehört, oder dass alles, was zu dieser Klasse gehört, auch zur Klasse http://example.org/Medium gehört.
Die Web Ontology Language (OWL) erweitert RDFS um weitaus ausdrucksstärkere Elemente, um die Beziehungen zwischen Klassen und Eigenschaften weiter zu präzisieren. So erlaubt OWL z. B. die Aussage, dass zwei Klassen keine gemeinsamen Elemente enthalten können, dass eine Eigenschaft transitiv zu verstehen ist, oder dass eine Eigenschaft nur eine bestimmte Anzahl von verschiedenen Werten haben kann. Diese erweiterte Ausdrucksstärke wird vor allem in Biologie und Medizin eingesetzt. Vokabulare werden hierbei oft austauschbar als Ontologien bezeichnet, letztere sind öfter stärker formalisiert als Vokabulare.
Die Definition dieser Begriffe selbst findet nicht durch das W3C in einem allgemein gültigen Vokabular statt, sondern jeder kann, in derselben Weise wie auch die Daten selbst veröffentlicht werden, eigene Vokabulare veröffentlichen. Dadurch gibt es keine zentrale Institution, die alle Vokabulare definiert. Die Vokabulare sind insofern selbstbeschreibend, als sie, genauso wie die Daten, in RDF und als Linked Open Data veröffentlicht werden können und damit Teil des Semantic Webs selbst.
Über die Jahre wurden zahlreiche Vokabulare entwickelt, von denen aber sehr wenige einen weiteren Einfluss erreichen konnten. Nennenswert sind hierbei Dublin Core für Metadaten zu Büchern und anderen Medien, Friend Of A Friend zum Beschreiben eines sozialen Netzwerks, Creative Commons zur Darstellung von Lizenzen, und einige Versionen von RSS zum Darstellen von Feeds. Ein besonders weit verbreitetes Vokabular wurde das durch die Zusammenarbeit der größten Suchmaschinen und Portale 2011 gestartete Schema.org, welches viele verschiedene Bereiche abdeckt.
Serialisierungen
RDF ist ein Datenmodell und keine konkrete Serialisierung (sprich, in welcher Syntax die Daten genau ausgetauscht werden). Lange Zeit war RDF/XML das einzige standardisierte Serialisierungsformat, doch war es sehr bald klar, dass RDF – mit dem Graphenmodell und der Basis in Tripeln – und XML – welches auf einem Baummodell aufbaut – nicht besonders gut zueinander passen. So haben sich über die Jahre weitere Serialisierungsformate verbreitet, wie z. B. die miteinander verwandten N3 und Turtle, die dem Tripelmodell wesentlich näher sind.
Zwei Serialisierungsformate sind besonders erwähnenswert, weil sie pragmatisch neue Anwendungsfelder eröffneten, RDFa und JSON-LD.
RDFa ist eine Erweiterung der HTML-Syntax, die es erlaubt direkt in der Webseite selbst Daten einzubinden. Dadurch kann z. B. eine Person mit ihrer Adresse, ein Konzert mitsamt Ort und Zeit, ein Buch mitsamt Autor und Verlag etc., gleich in der Webseite selbst ausgezeichnet werden. Durch den Einsatz vor allem in Schema.org und der Verwendung in den meisten Suchmaschinen ist innerhalb von zwei Jahren die Menge an RDF im Web enorm gewachsen: 2013 hatten mehr als vier Millionen Domains RDF-Inhalte.
JSON-LD versucht für Webentwickler möglichst nah an der gewohnte Nutzung von JSON als Datenaustauschformat zu bleiben. Hierbei werden die meisten Daten als einfache JSON-Daten ausgetauscht, und in einem Kontext-Datensatz wird festgelegt, wie die JSON-Daten nach RDF umgewandelt werden können. JSON-LD findet heute recht weite Verbreitung, um Daten in anderen Formaten einzubetten, z. B. in E-Mails oder in HTML-Dokumenten.
Vergleichbare Technologien
Eine vergleichbare Technik für die Wissensrepräsentation stellt der ISO-Standard Topic Maps dar. Ein Hauptunterschied zwischen RDF und Topic Maps findet sich in den Assoziationen: während in RDF Assoziationen immer gerichtet sind, sind sie bei Topic-Maps ungerichtet und rollenbasiert.
Mikroformate und Microdata entstanden als alternative, leichtgewichtige Datenmodelle und Serialisierungen zu den Standards des Semantic Webs. Mikroformate entstanden in Fortsetzung der sehr spezifischen Standards zum Austausch von z. B. Adressdaten in vCard, Kalenderdaten in vCalendar etc.
Kritik
Das Semantic Web wird oft als zu kompliziert und zu akademisch beschrieben. Bekannte Kritiken sind:
- Clay Shirky, Ontology is Overrated (Memento vom 29. Juli 2013 im Internet Archive)[5]: Ontologien funktionieren schon nicht mehr bezogen auf Bibliotheken, aber sie auf das ganze Web auszudehnen ist hoffnungslos. Ontologien sind zu stark auf eine bestimmte Sichtweise hin ausgerichtet, sind zu sehr top-down erstellt (im Gegensatz zu den im Web 2.0 entstandenen Folksonomien), und die formale Grundlage von Ontologien ist zu strikt und zu unflexibel. Da das Semantic Web auf Ontologien aufbaut, kann es die Probleme von Ontologien nicht umgehen.
- Aaron Swartz, The Programmable Web: Swartz sah den Fehler des Semantic Web in der vorzeitigen Standardisierung von nicht ausreichend gereifter Technologie, und in der übermäßigen Komplexität der Standards, wobei er insbesondere XML attackierte, und etwa mit der Einfachheit von JSON verglich. Das Besondere an Swartz’ Kritik war, dass er die Technologien außerordentlich gut verstand und sich die Ziele des Semantic Web herbeisehnte, aber die tatsächlich verwendeten Standards und die Prozesse, die zu deren Entstehung führten, für ungenügend befand.
Semantic Web als Forschungsbereich
Im Gegensatz zu vielen anderen Webtechnologien, entwickelten sich um das Ziel des Semantic Web rege Forschungstätigkeiten. So gab es schon seit 2001 jährliche akademische Konferenzen (vor allem die International Semantic Web Conference und die Asian Semantic Web Conference), und auch die wichtigste akademische Konferenz zum Web, die International World Wide Web Conference, beanspruchte Forschungsergebnisse zum Semantic Web einen bemerkbaren Anteil. Forscher im Bereich Semantic Web kamen vor allem aus den Bereichen Wissensrepräsentation, Logik, insbesondere den Beschreibungslogiken, Web Services, und Ontologien.
Die Forschungsfragen sind vielfältig und oft interdisziplinär. So werden z. B. Fragen der Entscheidbarkeit der Kombination bestimmter Sprachelemente für Ontologiesprachen untersucht, wie automatisch Daten, die in verschiedenen Vokabularen beschrieben sind, integriert und gemeinsam abgefragt werden können, wie Benutzerschnittstellen zum Semantic Web aussehen können (so entstanden zahlreiche Browser für Linked Data), wie die Dateneingabe von Semantic Web Daten vereinfacht werden kann, wie Semantic Web Services, also Web Services mit semantisch beschriebenen Schnittstellen, automatisch zusammenarbeiten können, um komplexe Ziele zu erreichen, effektive Veröffentlichung und Verwendung von Semantic Web Daten, und vieles mehr.
Relevante Zeitschriften sind vor allem das Journal of Web Semantics bei Elsevier, das Journal of Applied Ontologies und das Semantic Web Journal bei IOS Press. Prominente Forscher im Bereich Semantic Web sind, u. a., Wendy Hall, Jim Hendler, Rudi Studer, Ramanathan Guha, Asuncíon Gómez-Pérez, Mark Musen, Frank van Harmelen, Natasha Noy, Ian Horrocks, Deborah McGuinness, John Domingue, Carol Goble, Nigel Shadbold, David Karger, Dieter Fensel, Steffen Staab, Chris Bizer, Chris Welty, Nicola Guarino. Forschungsprojekte mit Schwerpunkten auf dem Bereich Semantic Web sind oder waren, u. a. GoPubMed, Greenpilot, Medpilot, NEPOMUK, SemanticGov, Theseus.
Diese rege Forschungsarbeit hat sicherlich dazu beigetragen, dem Semantic Web den Ruf akademisch und komplex zu sein einzubringen. Aus dieser Forschung sind aber auch zahlreiche Ergebnisse abgeleitet.
Siehe auch
Literatur
- Aaron Swartz’s A Programmable Web: An unfinished Work. gespendet von seinem Verlag Morgan & Claypool Publishers nach Aaron Swartz’s Tod im Januar 2013.
- Tim Berners-Lee with Mark Fischetti: Weaving the web: the original design and ultimate destiny of the World Wide Web by its inventors. 1. Auflage. HarperCollins, San Francisco, 1999, ISBN 0-06-251586-1; aktuelle Auflage: HarperBusiness, New York 2006, ISBN 0-06-251587-X. dt. Ausgabe: Tim Berners-Lee mit Mark Fischetti: Der Web-Report: der Schöpfer des World Wide Webs über das grenzenlose Potential des Internets. Econ, München 1999, ISBN 3-430-11468-3
- Tim Berners-Lee, James Hendler, Ora Lassila: The Semantic Web: a new form of Web content that is meaningful to computers will unleash a revolution of new possibilities. In: Scientific American, 284 (5), May 2001, S. 34–43 (dt.: Mein Computer versteht mich. In: Spektrum der Wissenschaft, August 2001, S. 42–49)
- Lee Feigenbaum, Ivan Herman, Tonya Hongsermeier, Eric Neumann, Susie Stephens: Mein Computer versteht mich – allmählich. In: Spektrum der Wissenschaft, November 2008, S. 92–99.
- Toby Segaran, Colin Evans, Jamie Taylor: Programming the semantic web. O’Reilly & Associates, Sebastopol CA 2009 ISBN 978-0-596-15381-6.
- Grigoris Antoniou, Frank van Harmelen: A Semantic Web Primer. 2nd Edition. The MIT Press, 2008, ISBN 0-262-01242-1
- Dieter Fensel, Wolfgang Wahlster, Henry Lieberman, James Hendler: Spinning the Semantic Web: Bringing the World Wide Web to Its Full Potential. The MIT Press, 2003, ISBN 0-262-06232-1
- Bo Leuf: The Semantic Web. Crafting Infrastructure for Agents. Wiley, 2006, ISBN 0-470-01522-5
- Vladimir Geroimenko, Chaomei Chen: Visualizing the Semantic Web. Springer Verlag, 2003, ISBN 1-85233-576-9
- Jeffrey T. Pollock: Semantic Web For Dummies. For Dummies. 2009, ISBN 978-0-470-39679-7
- Pascal Hitzler, Markus Krötzsch, Sebastian Rudolph, York Sure: Semantic Web. Grundlagen. Springer Verlag, 2008, ISBN 978-3-540-33993-9. Englische Ausgabe: Pascal Hitzler, Markus Krötzsch, Sebastian Rudolph: Foundations of Semantic Web Technologies. CRC Press, 2009, ISBN 978-1-4200-9050-5
Weblinks
- Andy Carvin: Tim Berners-Lee: Weaving a Semantic Web (Memento vom 8. Februar 2009 im Internet Archive). Published by the Digital Divide Network, October 2004 (Archivversion vom 8. Februar 2009; englisch)
- W3C Semantic-Web-Initiative (englisch)
- Linked Data – Connect Distributed Data across the Web (Verteilte Daten über das Netz hinweg verbinden) (englisch)
- Tim Berners-Lee: Semantic Web Future. (englisch)
Webcast Video
- Tim Berners-Lee: The next Web of open, linked data (2009) (englisch)
- Tim Berners-Lee: The Future of the Web (2006) (englisch)
Einzelnachweise und Anmerkungen
- John Markoff: Entrepreneurs See a Web Guided by Common Sense. In: New York Times, 12. September 2006
- Robert Tolksdorf: Web 3.0 – die Dimension der Zukunft. In: Der Tagesspiegel, 31. August 2007
- Giant Global Graph | Decentralized Information Group (DIG) Breadcrumbs. 21. November 2007, abgerufen am 10. März 2019.
- Tim Berners-Lee, James Hendler, Ora Lassila: The Semantic Web: a new form of Web content that is meaningful to computers will unleash a revolution of new possibilities. In: Scientific American, 284 (5), S. 34–43, May 2001 (dt.: Mein Computer versteht mich. In: Spektrum der Wissenschaft, August 2001, S. 42–49)
- Eine überarbeitete Fassung der Vorträge von 2005 findet sich auch auf der Webseite des Autors