Ostasiatische Schriften in Unicode
Als ostasiatische Schriftzeichen werden in Unicode eine Reihe von Schriften zusammengefasst, die im ostasiatischen Kulturraum entstanden sind und dort verwendet werden. Neben der umfangreichsten und ältesten Gruppe, den chinesischen Schriftzeichen, sind dies Schriften, die in den Nachbarländern Chinas verwendet werden und die teilweise von den chinesischen Zeichen beeinflusst sind: Die beiden japanischen Silbenschriften Hiragana und Katakana, das koreanische Alphabet Hangeul und die Silbenschrift Yi. Außerdem ist auch die chinesische phonetische Silbenschrift Bopomofo in Unicode kodiert.
Kodierte Zeichen
Chinesische Schriftzeichen
Chinesische Schriftzeichen werden nicht nur für die chinesische Sprache verwendet. Ursprünglich wurde auch das Japanische ausschließlich mit den Kanji genannten chinesischen Schriftzeichen geschrieben, heute sind sie zusammen mit Hiragana und Katakana in Gebrauch. Auch das Koreanische verwendete ursprünglich chinesische Schriftzeichen, Hanja genannt. Im Laufe der Zeit traten dabei in den einzelnen Sprachen Form- und Bedeutungsvarianten der einzelnen Schriftzeichen auf. Bei der Aufnahme in Unicode musste daher die Frage geklärt werden, ob die Zeichen für jede Sprache einzeln kodiert werden sollen, oder nur ein einziges Mal für alle Sprachen zusammen. Man entschied sich dafür, die Varianten in den unterschiedlichen Sprachen zu einem einzigen Unicode-Zeichen zu vereinigen und extrahierte im Verlauf der Han-Vereinheitlichung aus verschiedenen nationalen Standards die in Unicode unter der Bezeichnung CJK kodierten chinesischen Schriftzeichen.
Bei der Reihenfolge, in der die Zeichen kodiert sind, folgte man im Wesentlichen dem Kangxi-Wörterbuch.
Die folgende Tabelle zählt die Blöcke auf, die chinesische Schriftzeichen enthalten. Die Spalte „Zeitraum“ gibt an, wann die Zeichen der zuständigen Arbeitsgruppe zur Kodierung vorgeschlagen wurden. Auch in Zukunft werden weitere chinesische Schriftzeichen in Unicode aufgenommen werden, wobei man davon ausgeht, dass inzwischen mehr als die Hälfte aller möglichen Zeichen kodiert ist.[1]
| Block | Bereich | Ebene | Anzahl belegter Codepunkte | Zeitraum | Verwendung |
|---|---|---|---|---|---|
| Vereinheitlichte CJK-Ideogramme | 4E00–9FFF | 0 | 20.941 | bis 1992 mit späteren Ergänzungen | häufig |
| Vereinheitlichte CJK-Ideogramme, Erweiterung A | 3400–4DBF | 0 | 6.582 | 1992–1998 | selten |
| Vereinheitlichte CJK-Ideogramme, Erweiterung B | 20000–2A6DF | 2 | 42.711 | 1998–2002 | historisch |
| Vereinheitlichte CJK-Ideogramme, Erweiterung C | 2A700–2B73F | 2 | 4.149 | 2002–2006 | historisch |
| Vereinheitlichte CJK-Ideogramme, Erweiterung D | 2B740–2B81F | 2 | 222 | 2006–2009 | eher selten |
Neben diesen Blöcken gibt es mit CJK-Ideogramme, Kompatibilität und CJK-Ideogramme, Kompatibilität, Ergänzung zwei Blöcke, die (bis auf zwölf Ausnahmen) Kompatibilitätszeichen enthalten, die eigentlich mit anderen Zeichen hätten vereinigt werden können, zur Kompatibilität mit anderen Standards aber ihren eigenen Codepunkt zugewiesen bekamen.
Radikale sind in den Blöcken Kangxi-Radikale und CJK-Radikale, Ergänzung extra kodiert.
Einzelne Striche, aus denen die Schriftzeichen aufgebaut werden, sind im Block Unicodeblock CJK-Striche kodiert. Sie können etwa in einem Index für chinesische Wörterbücher verwendet werden.
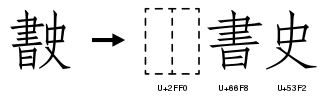
Der Block Unicodeblock Ideographische Beschreibungszeichen enthält eine Reihe von Zeichen, die es ermöglichen, noch nicht kodierte Zeichen anhand ihres Aufbaus zu beschreiben. Dazu wird das neue Zeichen in zwei oder drei bekannte Zeichen zerlegt. Diesen wird ein ideographisches Beschreibungszeichen vorangestellt, das angibt, wie diese Schriftzeichen zu kombinieren sind. Die nebenstehende Grafik zeigt, wie ein noch nicht in den Unicode-Standard aufgenommenes Zeichen durch eine solche ideographische Beschreibungssequenz ersetzt werden kann: In „⿰書史“ gibt das erste Zeichen an, dass es sich um ein Zeichen handelt, das man vertikal in zwei Hälften zerlegen kann, die beiden folgenden Zeichen geben an, wie diese Hälften aussehen. Auch für andere Kombinationen von Schriftzeichen gibt es Beschreibungszeichen. Sind die fehlenden Zeichen sehr komplex, so ist es auch möglich, Beschreibungssequenzen zu verschachteln, also eines der verwendeten Grundzeichen selbst wieder durch eine solche Sequenz zu beschreiben.
Der Unicodeblock Kanbun enthält einige Zeichen, die im Japanischen für Anmerkungen in chinesischen Texten verwendet werden.
Bopomofo
Die phonetische Transkriptionsschrift Bopomofo oder Zhuyin wird in den beiden Blöcken Bopomofo und Bopomofo, erweitert kodiert. Es fehlen lediglich die Tonzeichen, diese liegen im Block Unicodeblock Spacing Modifier Letters.
Hiragana und Katakana
Die beiden Hauptblöcke für die japanischen Silbenschriften Hiragana und Katakana, der Unicodeblock Hiragana und der Unicodeblock Katakana sind parallel aufgebaut und folgen im Wesentlichen dem Standard JIS X 0208.
Weitere japanische Schriftzeichen finden sich in den Blöcken Katakana, Phonetische Erweiterungen und Kana, Ergänzung.
Hangeul
Für die koreanische Schrift stellt Unicode zum einen einzelne Jamo in den Blöcken Hangeul-Jamo, Hangeul-Jamo, erweitert-A und Hangeul-Jamo, erweitert-B bereit. Diese werden dann bei der Anzeige in Silbenblöcken zusammengesetzt. Für die wichtigsten dieser Silbenblöcke gibt es im Unicodeblock Hangeul-Silbenzeichen bereits zusammengesetzte Silbenzeichen. Die Reihenfolge der Kodierung ist dabei so gewählt, dass die Zerlegung der Silben in einzelne Jamo und die Umkehrung etwa bei der Normalisierung algorithmisch einfach durchzuführen sind. Zur Kompatibilität mit dem koreanischen Standard KS X 1001 definiert der Unicodeblock Hangeul-Jamo, Kompatibilität ebenfalls einzelne Jamo, die sich aber nicht zu Silben verbinden.
Yi
Die moderne Silbenschrift Yi ist in Unicode in zwei Blöcken kodiert. Der Unicodeblock Yi-Silbenzeichen enthält die eigentlichen Silbenzeichen, der Unicodeblock Yi-Radikale die Radikale, aus denen die Schrift sich zusammensetzt. Wie bei den chinesischen Radikalzeichen sind diese hauptsächlich zur Verwendung in Indizes gedacht.
Weitere Zeichen
Neben den Schriftzeichen gibt es weitere Zeichen, die aus diesen abgeleitet sind, oder mit ihnen zusammen verwendet werden.
Satzzeichen und einige Symbole speziell für die ostasiatische Schriften finden sich im Block Unicodeblock CJK-Symbole und -Interpunktion. Weitere Symbole, die sich aus diesen Schriftzeichen ableiten oder mit ihnen zusammen verwendet werden, befinden sich in den Blöcken Umschlossene CJK-Zeichen und -Monate, Zusätzliche umschlossene CJK-Zeichen und CJK-Kompatibilität. Zur Kompatibilität mit anderen Standards werden in den Blöcken Vertikale Formen (für GB 18030) und CJK-Kompatibilitätsformen (für CNS 11643) einige Satzzeichen explizit in der Form kodiert, die sie im vertikalen Layout annehmen. Ebenfalls zur Kompatibilität mit CNS 11643 kodiert der Unicodeblock Kleine Formvarianten einige Satzzeichen in einer kleinen Variante.
Ebenfalls zur Kompatibilität mit älteren Standards gibt es den Unicodeblock Halbbreite und vollbreite Formen: Die meisten Zeichenkodierungen für ostasiatische Schriften verwenden einen Ein-Byte-Zeichensatz, der auf ASCII aufbaut parallel zu einem Mehr-Byte-Zeichensatz für die CJK-Zeichen. Die Anzahl der Bytes korrespondiert dabei mit der Breite der Zeichen: Die Ein-Byte-Zeichen werden nur mit halber Breite dargestellt. Viele dieser Zeichensätze kodieren aber alle Zeichen des ASCII-Bereiches ein weiteres Mal mit mehreren Bytes als vollbreite Formen, umgekehrt wurden einige Zeichen, unter anderem Katakana, auch in halber Breite in Zeichensätze aufgenommen. Unicode stellt daher ebenfalls die doppelt kodierten Zeichen ein weiteres Mal als vollbreites bzw. halbbreites Zeichen zur Verfügung.
Darstellung
Die traditionelle Schreibrichtung der ostasiatischen Schriften ist in Spalten von oben nach unten. Die Spalten selbst werden meist von rechts nach links angeordnet. Die Zeichen haben dabei alle die gleiche Breite und Höhe. Allerdings sind inzwischen auch proportionale Schriftarten mit einer Schreibrichtung in Zeilen von links nach rechts gebräuchlich.
Einige Zeichen haben ein unterschiedliches Aussehen, je nachdem, ob sie in vertikalem oder horizontalem Text vorkommen, dies betrifft insbesondere Satzzeichen, aber auch lateinische Buchstaben, diese werden im senkrechten Text meist um 90° gedreht dargestellt.
Bei der Entscheidung, welche Zeichen im vertikalen Layout gedreht werden müssen, und welche Zeichen in horizontaler Anordnung in einer proportionalen Schriftart gesetzt werden sollen, kann die Unicode-Eigenschaft East_Asian_Width verwendet werden, aus der abgelesen werden kann, ob ein Zeichen breit ist, sich also wie etwa ein chinesisches Schriftzeichen verhält, oder ob es schmal ist und wie ein lateinischer Buchstabe behandelt wird. Für das vertikale Layout gibt es Alternativ einen im Unicode Technical Report #50 beschriebenen Algorithmus, der auf eine spezielle Eigenschaft beruht, die extra für diesen Algorithmus definiert wurde.
Diese Eigenschaft kann für jedes Zeichen einen von vier verschiedenen Werten annehmen: U bedeutet, dass das Zeichen auch im vertikalen Layout aufrecht dargestellt werden soll, R kennzeichnet Zeichen, die um 90° im Uhrzeigersinn gedreht werden. Daneben gibt es zwei weitere Werte, Tu und Tr. Für Zeichen mit diesen Werten gibt es eine spezielle typographische Variante, nur wenn es aus irgendeinem Grund nicht möglich ist diese zu verwenden, wird der Wert wie U bzw. R behandelt. Zunächst wird der Text durch den Unicode-Segmentierungsalgorithmus für Grapheme zerlegt, das erste Zeichen eines Graphems bestimmt die Orientierung, außer bei Graphemen mit einem umschließenden kombinierendem Zeichen, welche immer aufrecht dargestellt werden.
Unicode sieht keinen speziellen Mechanismus vor, um bei CJK-Zeichen die für die Sprache korrekte Glyphenvariante zu wählen. In den meisten Fällen wird der Leser die korrekte Schriftart als Standardschrift eingestellt haben, und selbst wenn die Zeichen (etwa bei chinesischen Zitaten in einem japanischen Text) nicht in der erwarteten Form angezeigt werden, bleiben sie dennoch lesbar. Ist die genaue Darstellung dagegen wichtig, müssen dem Text geeignete Metainformationen beigefügt werden. Eine Möglichkeit hierfür sind die mittlerweile missbilligten Sprach-Tags. Für einzelne Zeichen kann auch mit Hilfe eines Variantenselektors eine spezielle Glyphenvariante ausgewählt werden. Daneben besteht die Möglichkeit, über höhere Protokolle wie HTML Informationen zur Sprache oder zur gewünschten Schriftart übertragen.
Bopomofo wird häufig als Anmerkung zum in chinesischen Zeichen geschriebenen Text verwendet, je nach Schreibrichtung sollten diese Anmerkungen senkrecht neben oder waagerecht über dem annotierten Text angezeigt werden. hier bieten sich Techniken wie Ruby oder die Verwendung von Anmerkungszeichen an.
Quellen
- Julie D. Allen et al.: The Unicode Standard. Version 6.2 – Core Specification. The Unicode Consortium, Mountain View, CA, 2012. ISBN 978-1-936213-07-8. (online) Chapter 12: East Asian Scripts. (PDF)
- Ken Lunde: Unicode Standard Annex #11: East Asian Width. (online)
- Koji Ishii: Unicode Technical Report #50: Unicode Vertical Text Layout. (online)
Einzelnachweise
- FAQ: Chinese and Japanese Abgerufen am 18. Februar 2013.
Weblinks
- The secret life of Unicode: East Asian issues (englisch)
Lateinisch | Griechisch und Koptisch | Kyrillisch und Glagolitisch | Hebräisch | Arabisch und Syrisch | Indische Schriften | Ostasiatische Schriften | Historische Schriften
Interpunktionszeichen | Zahlzeichen | Symbole | Mathematische Zeichen | Leerraum | Steuerzeichen