Kombinierendes Zeichen
Kombinierende Zeichen (englisch combining characters/marks) sind in der digitalen Typografie besondere Zeichen, die normalerweise nicht einzeln dargestellt werden, sondern mit dem vorhergehenden Zeichen zu einem einzigen Zeichen verbunden werden. Dies wird vor allem benutzt, um beliebige diakritische Zeichen zu bilden. So ergibt beispielsweise der Kleinbuchstabe y gefolgt vom Zeichen Kombinierende Breve ein y̆, ein Zeichen, was sich ohne kombinierende Zeichen nicht in Unicode darstellen ließe. Vom Konzept her lassen sich also die kombinierenden Zeichen mit den Tottasten auf der Tastatur vergleichen.
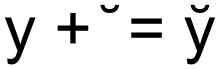
Formale Grundlagen
Umfang und Verwendung kombinierender Zeichen unterscheiden sich zwischen verschiedenen Zeichenkodierungen. So kennt ISO 6937 eine Reihe kombinierender Zeichen für diakritische Zeichen, erlaubt aber nur bestimmte Kombinationen. Für eine vollständige Darstellung reicht es daher aus, wenn der verwendete Font eigene Glyphen für diese Kombinationen bereitstellt. Alternativ kann die Kodierung auch aufgefasst werden als eine Kodierung, bei der einfache Buchstaben durch einen Codepunkt, Buchstaben mit diakritischen Zeichen dagegen durch eine Folge von zwei Codepunkten repräsentiert werden. In dieser Norm werden die kombinierenden Zeichen abweichend vom sonst üblichen Verhalten dem Buchstaben vorangestellt, mit dem sie kombiniert werden.
Kombinierende Zeichen werden nicht nur für diakritische Zeichen eingesetzt, so verwenden die Kodierungen aus ISCII-1988 für verschiedene indische Schriften kombinierende Zeichen auch für Vokalzeichen.
Die umfangreichste Sammlung an kombinierenden Zeichen bietet Unicode zusammen mit einer Reihe von Regeln für deren Darstellung. Unicode erlaubt dabei beliebige Kombinationen aus Grundzeichen und kombinierenden Zeichen, es dürfen auch mehrere kombinierende Zeichen auf ein Grundzeichen folgen. Für die Darstellung reicht es daher nicht aus, wenn der Font einige Zusatzglyphen enthält, vielmehr sind Angaben über die Abmessungen der einzelnen Zeichen notwendig, um das Grundzeichen mit dem kombinierenden Zeichen zusammenzusetzen. Dies wird etwa vom OpenType-Konzept realisiert.
Im Unicodestandard sind kombinierende Zeichen durch ihre Zeichenklasse (General Category) M gekennzeichnet. Diese wiederum teilt sich in drei Unterklassen auf: Nonspacing Mark (Mn) für kombinierende Zeichen, die in der Regel keinen eigenen Platz benötigen (etwa diakritische Zeichen), Enclosing Mark (Me) für kombinierende Zeichen, die das Grundzeichen ganz umschließen, und Spacing Combining Mark (Mc) für kombinierende Zeichen, die eigenen Platz brauchen (etwa indische Vokalzeichen).
Ferner wird jedem Zeichen eine Eigenschaft Combining Class zugewiesen. Dies ist eine ganze Zahl zwischen 0 und 255, die im Wesentlichen die Position angibt, an der das kombinierende Zeichen an das Grundzeichen angefügt wird. So haben etwa alle kombinierenden Zeichen, die über das Grundzeichen gesetzt werden, den Wert 230, Zeichen, die unter dem Grundzeichen stehen, den Wert 220. Bei normalen, nichtkombinierenden Zeichen ist der Wert immer 0, es gibt aber auch einige kombinierende Zeichen mit diesem Wert.
Darstellung
Der Unicodestandard macht nur wenige verbindliche Aussagen darüber, wie Programme Zeichenfolgen mit kombinierenden Zeichen darstellen sollen.[1] Es werden jedoch die folgenden Empfehlungen angeführt:
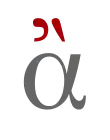
- Folgen auf ein Grundzeichen mehrere kombinierende Zeichen, so sollen diese der Reihe nach von innen nach außen angefügt werden. So ergibt etwa die Folge <Lateinischer Kleinbuchstabe a U+0061, Kombinierender Zirkumflex U+0302, Kombinierende Tilde U+0303> ein a bei dem sich über dem Zirkumflex noch eine Tilde befindet (ẫ), während bei <Lateinischer Kleinbuchstabe a U+0061, Kombinierende Tilde U+0303, Kombinierender Zirkumflex U+0302> umgekehrt der Zirkumflex über der Tilde steht (ã̂). Eine wichtige Ausnahme von diesem Prinzip sind etwa Akzente im Griechischen. In der Folge <Griechischer Kleinbuchstabe alpha U+03B1, Kombinierendes Komma als Überzeichen U+0313, Kombinierender Gravis U+0300> sollte der Gravis nicht über dem Komma stehen, sondern dahinter (ἂ). Auch mit dem speziellen kombinierendem Zeichen Combining Grapheme Joiner kann eine Abweichung von der üblichen Stapelung erzwungen werden.
- Falls mehrere kombinierende Zeichen aufeinander folgen, die an verschiedenen Stellen an das Grundzeichen angefügt werden (etwa oben und unten, genauer gesagt richtet sich dies nach der
Combining Class-Eigenschaft), so darf die Reihenfolge keine Rolle spielen, das Resultat muss in beiden Fällen gleich aussehen. So ergeben <Lateinischer Kleinbuchstabe a U+0061, Kombinierender Punkt als Überzeichen U+0307, Kombinierender Punkt als Unterzeichen U+0323> und <Lateinischer Kleinbuchstabe a U+0061, Kombinierender Punkt als Unterzeichen U+0323, Kombinierender Punkt als Überzeichen U+0307> beide ein a mit einem Punkt oben und einem unten (ạ̇). - Falls die typographische Tradition das diakritische Zeichen an eine andere Stelle setzt, so ist dies möglich. So wird üblicherweise ein Komma unter einem g als ein invertiertes Komma über dem g dargestellt.
- Die Punkte von i, j und einigen weiteren Zeichen mit der
Soft_Dotted-Eigenschaft[2] werden entfernt. - Im Idealfall orientiert sich ein Programm bei der Positionierung kombinierender Zeichen am genauen Aussehen der Grundbuchstaben, so wird ein Akzent über einem Großbuchstaben im Normalfall höher sitzen als bei einem Kleinbuchstaben. Der Standard stellt aber klar, dass auch eine einfache Positionierung immer an derselben Stelle akzeptabel ist.[3]
Für die Darstellung kombinierender Zeichen in den indischen Schriften in Unicode gibt es spezielle, umfangreiche Regeln.
In einigen Fällen möchte man diakritische Zeichen, die sich über zwei oder mehr Grundzeichen erstrecken. Hierfür gibt es zwei Techniken:
Zum einen gibt es sogenannte doppelte kombinierende Zeichen, die sich nicht nur wie normale kombinierende Zeichen über das vorhergehende Grundzeichen erstrecken, sondern auch über das auf das doppelte kombinierende Zeichen folgende Zeichen. So gibt etwa <Lateinischer Kleinbuchstabe n U+006E, Kombinierende doppelt so breite Tilde U+0360, Lateinischer Kleinbuchstabe g U+0067> ein von einer Tilde überspanntes ng: n͠g.
Zum anderen gibt es spezielle kombinierende halbe Zeichen. Hier folgt die erste Hälfte auf das erste Grundzeichen, die zweite auf das zweite. Somit kann man ng mit Tilde auch darstellen durch <Lateinischer Kleinbuchstabe n U+006E, Kombinierende doppelbreite Tilde (linke Hälfte) U+FE22, Lateinischer Kleinbuchstabe g U+0067, Kombinierende doppelbreite Tilde (rechte Hälfte) U+FE23>, auch dies ergibt n︢g︣.
Um ein kombinierendes Zeichen für sich alleine darzustellen, sollte man ihm ein geschütztes Leerzeichen voranstellen. Die frühere Empfehlung, ein normales Leerzeichen zu nehmen, wurde wegen Problemen bei der Verarbeitung solcher Leerzeichen in XML und in anderen Kontexten wieder verworfen.[4] Für viele diakritische Zeichen gibt es auch im Unicodeblock Spacing Modifier Letters nichtkombinierende Varianten. In technischen Dokumentationen werden kombinierende Zeichen oft mit einem gepunkteten Kreis (◌) dargestellt, an dem veranschaulicht wird, an welcher Position das kombinierende Zeichen an das Grundzeichen angeführt wird.
Mehrdeutige Darstellungen
Das Konzept der kombinierenden Zeichen führt dazu, dass es Zeichen gibt, die sich auf mehrere verschiedene Arten durch Zeichen darstellen lassen. Dies hat zwei Ursachen:

Zum einen gibt es für viele gebräuchliche Kombinationen aus Grundzeichen und diakritischem Zeichen ein eigenes Zeichen. So lässt sich ein ñ darstellen als <Lateinischer Kleinbuchstabe n U+006E, Kombinierende Tilde U+0303>, aber es existiert auch ein gesondertes Zeichen Lateinischer Kleinbuchstabe n mit Tilde am Codepunkt U+00F1.
Zum anderen ergeben Folgen von kombinierenden Zeichen, die nicht miteinander interagieren, das gleiche Zeichen.
Insgesamt kann die Anzahl der verschiedenen Darstellungen dadurch sehr groß werden, für ậ, das kleine a mit einem Zirkumflex und einem Punkt unten gibt es etwa die folgenden Darstellungsmöglichkeiten:
- <Lateinischer Kleinbuchstabe a mit Zirkumflex und Punkt unten U+1EAD>
- <Lateinischer Kleinbuchstabe a mit Zirkumflex U+00E2, Kombinierender Punkt als Unterzeichen U+0323>
- <Lateinischer Kleinbuchstabe a mit Punkt unten U+1EA1, Kombinierender Zirkumflex U+0302>
- <Lateinischer Kleinbuchstabe a U+0061, Kombinierender Zirkumflex U+0302, Kombinierender Punkt als Unterzeichen U+0323>
- <Lateinischer Kleinbuchstabe a U+0061, Kombinierender Punkt als Unterzeichen U+0323, Kombinierender Zirkumflex U+0302>
Um zu einer eindeutigen Darstellung zu gelangen (etwa wenn man wissen möchte, ob zwei Wörter gleich sind), gibt es verschiedene Normalisierungen. Zu diesem Zweck ist im Standard zu jedem Zeichen angegeben, ob es sich in ein Grundzeichen und kombinierende Zeichen zerlegen lässt, und falls ja, wie. Zunächst werden alle Zeichen auf die angegebene Art zerlegt, anschließend Folgen kombinierender Zeichen, die nicht miteinander interagieren gemäß ihrer Combining_Class-Eigenschaft sortiert. Dies liefert die kanonische Zerlegung (NFD).
Kodierte Zeichen in Unicode
Derzeit (Stand: Unicode 7.0, Juni 2014) definiert der Unicodestandard 1830 kombinierende Zeichen[5], die sich auf mehrere Blöcke verteilen.
Die drei Blöcke Kombinierende diakritische Zeichen, Kombinierende diakritische Zeichen, Ergänzung und Kombinierende diakritische Zeichen, erweitert enthalten diakritische Zeichen, die für Buchstaben aller Alphabete vorgesehen sind.
Der Unicodeblock Kombinierende diakritische Zeichen für Symbole enthält ebenfalls kombinierende Zeichen, diese sind jedoch für den Gebrauch mit Symbolen vorgesehen. So kann man etwa Warnzeichen zusammensetzen: <Gefährliche elektrische Spannung U+26A1, Kombinierendes umschließendes Dreieck nach oben U+20E4> ergibt ⚡⃤.
Die kombinierenden halben Zeichen befinden sich im Unicodeblock Kombinierende halbe diakritische Zeichen.
Viele weitere Blöcke enthalten ebenfalls kombinierende Zeichen, die speziell für die Verwendung mit den anderen Zeichen dieses Blocks gedacht sind. So befinden sich die kombinierenden Zeichen für Titlo und weitere kyrillische diakritische Zeichen im Block Kyrillisch.
Literatur
- Julie D. Allen et al.: The Unicode Standard, version 6.0. Unicode Consortium, Mountain View 2001, ISBN 978-1-936213-01-6 (online).
Weblinks
Einzelnachweise
- Julie D. Allen: The Unicode Standard, version 6.0. 3.6 Combination, p. 83 ff.
- PropList.txt
- Julie D. Allen: The Unicode Standard, version 6.0. 5.13 Rendering Nonspacing Marks, p. 157.
- Julie D. Allen: The Unicode Standard, version 6.0. 2.11 Combining Characters, p. 46.
- DerivedGeneralCategory.txt