Arabisch und Syrisch in Unicode
Die Zeichen für das Arabische und Syrische befinden sich in Unicode in acht verschiedenen Unicode-Blöcken. Neben den einzelnen Zeichen definiert der Unicode-Standard auch eine Reihe von Algorithmen zur korrekten Darstellung arabischer und syrischer Texte.
Kodierte Zeichen
Die wichtigsten Zeichen für das Arabische liegen im Unicodeblock Arabisch. Neben den Buchstaben des arabischen Alphabets, die in Umfang und Anordnung ISO 8859-6 entsprechen, befinden sich hier auch Ziffern, einige Satzzeichen, die sich stark von denen unterscheiden, die mit lateinischer Schrift verwendet werden, und Sonderzeichen. Auch wenn ein Buchstabe je nach Position im Wort verschiedene Darstellungsformen besitzt, enthält dieser Block nur jeweils ein Zeichen für alle Varianten.
Das arabische Alphabet wird auch in anderen Sprachen verwendet, die es um einige weitere Zeichen ergänzen. So gibt es etwa im persischen Alphabet vier zusätzliche Buchstaben. Solche Buchstaben befinden sich zusammen mit Zeichen, die nicht mehr in Gebrauch sind, in den Blöcken Arabisch, Ergänzung und Arabisch, erweitert-A.
Die beiden Blöcke Arabische Präsentationsformen-A und Arabische Präsentationsformen-B enthalten – vor allem für Kompatibilität mit anderen Standards – Darstellungsvarianten und Ligaturen.
Der Unicodeblock Arabische mathematische alphanumerische Symbole schließlich enthält arabische Buchstaben für den Gebrauch in mathematischen Formeln.
Die Buchstaben des syrischen Alphabets liegen im Unicodeblock Syrisch. Anders als für das Arabische gibt es hier keine Zeichen, die in verschiedenen Darstellungsformen mehrfach kodiert sind.
Neben diesen Zeichen spielen die bidirektionalen Steuerzeichen und der breitenlose Verbinder bzw. Nichtverbinder in der digitalen arabischen und syrischen Typografie eine Rolle.
Schreibrichtung
Arabisch und Syrisch wird von rechts nach links geschrieben, nur Zahlen – unabhängig von den verwendeten Ziffern – schreibt man von links nach rechts. Einige Satzzeichen, etwa Klammern, werden gespiegelt zur gewöhnlichen Variante dargestellt. Für die korrekte Darstellung sieht der Unicode-Standard wie für andere linksläufige Schriften den Unicode-Bidi-Algorithmus vor.
Kontextabhängige Buchstabenformen
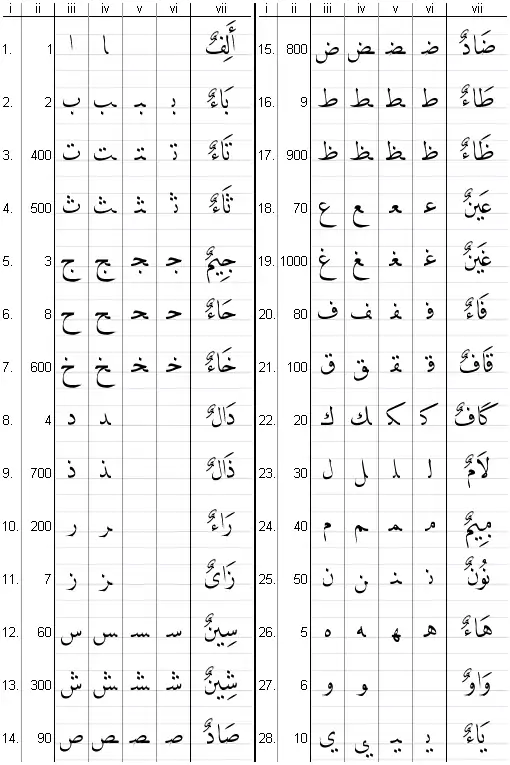
iii) isolierte Form
iv) nach rechts verbundene Form
v) beidseitig verbundene Form
vi) nach links verbundene Form
Je nach Stellung im Wort kann ein arabischer Buchstabe in bis zu vier verschiedenen Darstellungsformen auftreten: Als isolierter Buchstabe (etwa in Zeichentabellen), als Buchstabe am Wortanfang, wo er sich mit dem folgenden Buchstaben links verbindet, am Ende eines Wortes, wo er sich mit dem vorhergehenden Buchstaben rechts verbindet, und in der Wortmitte, wo er mit beiden Nachbarn verbunden ist. Eine Schriftart muss also für ein einziges Zeichen bis zu vier verschiedene Glyphen bereithalten. Um die je nach Kontext korrekte Glyphe auszuwählen, wird der folgende Algorithmus verwendet:
Dazu weist Unicode jedem Zeichen eine Joining_Type-Eigenschaft zu. Diese Eigenschaft gibt an, ob und in welche Richtung sich das Zeichen mit den Nachbarzeichen verbindet. Es gibt sechs verschiedene Werte:
Rfür Zeichen wie etwa Alif oder Dāl, die nur nach rechts verbunden werdenLfür Zeichen, die nur nach links verbunden werden. Im Arabischen gibt es kein Zeichen mit diesem Wert, er wird allerdings in der Phagpa-Schrift und für Manichäisch verwendet.Dfür Zeichen wie etwa Ba oder Ta, die zu beiden Seiten hin verbunden werdenCfür Zeichen wie etwa das Kaschidazeichen oder den breitenlosen Verbinder, die ebenfalls zu beiden Seiten eine Verbindung initiieren, selbst aber unverändert bleibenUfür Zeichen, die sich nicht mit ihren Nachbarn verbinden, also etwa alle lateinischen Buchstaben, oder auch der breitenlose Nichtverbinder.Tfür Zeichen wie kombinierende Zeichen, die bei der Anwendung des Algorithmus ignoriert werden sollten.
Mit dieser Eigenschaft wird nach einem Regelwerk bestimmt, in welcher Form ein Zeichen dargestellt werden soll:
Zeichen vom Typ R, denen ein Zeichen vom Typ L, D oder C vorausgeht (wobei Zeichen vom Typ T übergangen werden), werden in der nach rechts verbundenen Form dargestellt, analog werden Zeichen vom Typ L, denen ein Zeichen vom Typ R, D oder C folgt (wobei Zeichen vom Typ T übergangen werden), werden in der nach links verbundenen Form dargestellt.
Für Zeichen vom Typ D werden beide diese Regeln angewendet, stehen auf beiden Seiten geeignete Zeichen, so wird die zu beiden Seiten hin verbundene Form gewählt, steht nur auf einer Seite ein solches Zeichen, auf der anderen nicht, wird die entsprechend verbundene Form ausgesucht.
Trifft keine der Regeln zu, so wird das Zeichen in der unverbundenen Form dargestellt.
Dieser Algorithmus wird auch für die syrische Schrift verwendet, wobei für den syrischen Buchstaben Olaf spezielle zusätzliche Regeln gelten.
Weitere Schriftsysteme, in denen dieser Algorithmus Anwendung findet, sind N’Ko, Mongolisch, Phagpa, Manichäisch und Psalter-Pahlavi.
Ligaturen
Eine weitere Besonderheit im Arabischen und Syrischen sind bestimmte Ligaturen, die sich im Aussehen deutlich von den zusammengesetzten Einzelbuchstaben unterscheiden, aus denen sie bestehen.
Für die korrekte Darstellung der Ligaturen enthält der Unicode-Standard eine weitere Eigenschaft Joining_Group. Diese kann verschiedene Werte annehmen, die nach den Buchstaben dieser Gruppe benannt werden. So haben Lam und daraus abgeleitete Buchstaben alle den Wert Lam. Folgt auf ein solches Zeichen ein Buchstabe aus der Gruppe Alef (der Alif und abgeleitete Zeichen angehören), so werden diese beiden Zeichen durch die Lām-Alif-Ligatur dargestellt.
Weitere Besonderheiten
Einige Zeichen erfordern eine besondere Darstellung, beispielsweise U+06DD, Ende einer Āya. Dieses Zeichen umschließt alle direkt folgenden Ziffern. Um ein Zeichen als Ziffer zu erkennen, können Computersysteme auf die allgemeine Kategorie des Zeichens zurückgreifen. Ähnliches gilt für die Zeichen an den Codepunkten U+0600 bis U+0603, die allgemeine Zahlen, Jahre, Fußnoten und Seitenzahlen unterstreichen. Im Syrischen gibt es das syrische Abkürzungszeichen (U+070F), das den Beginn einer Abkürzung anzeigt, die dann mit einer übergesetzten Linie mit einzelnen Punkten markiert werden soll. Das nebenstehende Beispiel zeigt die ersten vier Buchstaben des syrischen Alphabets, von denen die letzten drei vom syrischen Abkürzungszeichen überspannt werden.
Quellen
- Julie D. Allen et al.: The Unicode Standard. Version 6.2 – Core Specification. The Unicode Consortium, Mountain View, CA, 2012. ISBN 978-1-936213-07-8. Chapter 8.2: Arabic, Chapter 8.3: Syriac. (online, PDF)
Lateinisch | Griechisch und Koptisch | Kyrillisch und Glagolitisch | Hebräisch | Arabisch und Syrisch | Indische Schriften | Ostasiatische Schriften | Historische Schriften
Interpunktionszeichen | Zahlzeichen | Symbole | Mathematische Zeichen | Leerraum | Steuerzeichen