OCRopus
OCRopus (auch ocropy) ist eine freie Software zur Dokumentanalyse und Texterkennung mit einem sehr modularen Entwurf. OCRopus wurde mit Unterstützung von Google Inc. unter Leitung von Thomas Breuel vom Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) in Kaiserslautern entwickelt und als freie Software unter den Bedingungen von Version 2.0 der Apache-Lizenz veröffentlicht.
| OCRopus | |
|---|---|
 | |
| Basisdaten | |
| Entwickler | Thomas Breuel, DFKI |
| Erscheinungsjahr | 2007 |
| Aktuelle Version | 1.3.3[1][2][3] (16. Dezember 2017) |
| Betriebssystem | FreeBSD, Linux, macOS, Windows 10 |
| Programmiersprache | C++, Python |
| Kategorie | Texterkennung |
| Lizenz | Apache-Lizenz |
| github.com/ocropus/ocropy | |
Beschreibung
OCRopus wurde insbesondere für die Anwendung in großflächigen Retrodigitalisierungsprojekten von Büchern etwa bei Google Books, Internet Archive oder Bibliotheken konzipiert. Dabei sollen eine Vielzahl von Sprachen und Schriften unterstützt werden.[4] Es kann aber auch für Anwendungen im Bürobereich oder für Sehgeschädigte eingesetzt werden.
Die Hauptkomponenten bei OCRopus bilden:
- Analyse des Dokumentenaufbaus
- optische Zeichenerkennung
- Nutzung von statistischen Sprachmodellen
Für diese Komponenten stehen einzelne oder auch mehrere Skripte zur Verfügung. Der modulare Ansatz erlaubt es individuelle Workflows zu nutzen und einzelne Schritte auszutauschen.
Standardmäßig kommt OCRopus mit einem Modell für englische Texte und einem Modell für Texte in Fraktur. Diese Modelle beziehen sich auf die Schriftart und sind weitestgehend unabhängig von der eigentlichen Sprache.[5] Neue Schriftzeichen oder Sprachvarianten können entweder neu oder zusätzlich trainiert werden.
Die tatsächliche Erkennung basiert auf rekurrenten neuronalen Netzen (LSTM) und kommt gänzlich ohne Sprachmodell aus. Damit können sprachunabhängige Modelle trainiert werden, für welche gute Erkennungsergebnisse für Englisch, Deutsch, Französisch zugleich gezeigt wurden.[6] Neben dem lateinischem Schriftsystem gibt es Resultate für weitere Schriften wie etwa Sanskrit, Urdu, Devanagari, Griechisch.
Durch ein entsprechendes Training können sehr gute Erkennungsraten erreicht werden.[7] Dieser Mehraufwand lohnt sich gerade bei schwierigen Dokumenten oder heute nicht mehr üblichen Schriftarten, welche bei anderen OCR-Softwares nicht im Fokus stehen.[8][9]
Geschichte
Am 9. April 2007 wurde OCRopus als ein von Google gesponsertes Projekt zur Entwicklung fortschrittlicher OCR-Technologien bekannt gegeben.[10] Die Förderung war auf drei Jahre ausgelegt und umschloss insbesondere Doktoranden- bzw. PostDoc-Stellen am DFKI bzw. der Universität Kaiserslautern. Im Gegenzug wurde bei der Google Buchsuche auch OCRopus für die automatische Texterkennung verwendet.[11] Die Lizenzierung unter einer Open-Source-Lizenz wurde gleich zu Beginn gemacht um Kollaborationen zwischen industrieller und akademischer Forschung leichter zu ermöglichen.[12] Weitere Förderung hat OCRopus von der Andrew W. Mellon Foundation sowie dem BMBF bekommen.[13] Im Zuge des TextGrid-Projektes wurde dabei etwa die Schrifterkennung für Fraktur angegangen.[14]
Die erste Alpha-Version 0.1 wurde am 22. Oktober 2007 veröffentlicht und diverse Vorabversionen erschienen zwischen Dezember 2007 und Mai 2009. Mit Version 0.4.4 wurde 2010 ein stabiler Stand erreicht.[15] Ursprünglich wurde das Programm in C++, Python und Lua mit Jam als Build-System entwickelt. Ein komplettes Refactoring des Quellcodes in Python-Module beinhaltet die Version 0.5, welche 2012 veröffentlicht wurde.[16]
Anfänglich wurde Tesseract als einziges Erkennungsmodul verwendet. Ab Version 0.4 (2009) wird Tesseract nur noch als Plugin unterstützt. Stattdessen kam eine Eigenentwicklung zur Texterkennung (ebenfalls Segment-basiert) zum Einsatz[17]. Ab 2013 wurde zusätzlich eine Erkennung auf rekurrenten neuronalen Netzen (LSTM) angeboten, welche mit der Version 1.0 im November 2014 als einziger Erkenner weitergeführt wird.[18][7]
Der Quellcode wird über GitHub verwaltet und wird von der Entwickler-Community gepflegt und weiterentwickelt.[19] Die aktuelle Version von OCRopus ist 1.3.3 (Dezember 2017).[20]
Weiterentwicklungen des ursprünglichen OCRopus sind ocropy (auch OCRopus2) und OCRopus3. OCRopus4 ist die neueste Version, an der Thomas Breuel aktuell (Stand 2021) arbeitet.[21]
Abspaltungen
Von OCRopus abgeleitet ist die OCR-Software Kraken.[22] Calamari ist ein weiterer Abkömmling, der auf OCRopy und Kraken basiert.[23]
Benutzung
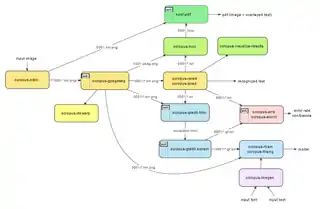
OCRopus ist ein reines Kommandozeilenprogramm. Es wird primär für Linux-Plattformen entwickelt, sollte jedoch auf vielen Plattformen lauffähig sein, solange seine Abhängigkeiten erfüllt sind. Eingesetzt wird es, indem über die Kommandozeile das Eingabebild angegeben wird. Zur genaueren Steuerung können zusätzlich noch Optionen übergeben werden, um bestimmte Aktionen wie die Erkennung einer einzelnen Zeile auszuführen.[24] Die Ergebnisse werden über die Standardausgabe (stdout) in HTML und CSS mit speziellen Formatierungen (hOCR) ausgegeben.
Beispiel für die Aufrufe der OCRopus Skripte um den Text in einem Bild zu erkennen:
# Binarisierung: ocropus-nlbin tests/ersch.png -o book
# Layoutanalyse für Seite: ocropus-gpageseg book/0001.bin.png
# Texterkennung der Linien (mit dem Fraktur Model): ocropus-rpred -m models/fraktur.pyrnn.gz book/0001/*.bin.png
# HTML Ausgabe erzeugen: ocropus-hocr book/0001.bin.png -o book/0001.html
Weblinks
- OCRopus auf GitHub und zugehöriges Wiki (englisch)
Quellen und Einzelnachweise
- Release 1.3.3. 16. Dezember 2017 (abgerufen am 15. März 2018).
- Release 1.3.3. 16. Dezember 2017 (abgerufen am 19. Februar 2020).
- Release 1.3.3. 16. Dezember 2017 (abgerufen am 1. August 2020).
- Thomas Breuel: Recent Progress on the OCRopus OCR System. In: Proceedings of the International Workshop on Multilingual OCR (= MOCR ’09). ACM, New York 2009, ISBN 978-1-60558-698-4, S. 2:1–2:10, doi:10.1145/1577802.1577805.
- Models. In: ocropy wiki. GitHub, abgerufen am 29. Dezember 2017.
- Adnan Ul-Hasan, Thomas M. Breuel: Can We Build Language-independent OCR Using LSTM Networks? In: Proceedings of the 4th International Workshop on Multilingual OCR (= MOCR ’13). ACM, New York, NY, USA 2013, ISBN 978-1-4503-2114-3, S. 9:1–9:5, doi:10.1145/2505377.2505394.
- T. M. Breuel, A. Ul-Hasan, M. A. Al-Azawi, F. Shafait: High-Performance OCR for Printed English and Fraktur Using LSTM Networks. In: 2013 12th International Conference on Document Analysis and Recognition. August 2013, S. 683–687, doi:10.1109/ICDAR.2013.140.
- Robert Nasarek: OCRopus – Hoffnungsträger der Frakturschrifterkennung. In: Digital Humanities selbst gestrickt. 23. Mai 2017, abgerufen am 29. Dezember 2017.
- Uwe Springmann: OCR für alte Drucke. In: Informatik-Spektrum. Band 39, Nr. 6, 1. Dezember 2016, ISSN 0170-6012, S. 459–462, doi:10.1007/s00287-016-1004-3.
- Thomas Breuel: Announcing the OCRopus Open Source OCR System. In: Google Developers Blog. 9. April 2007, abgerufen am 29. Dezember 2017.
- Forschungsprojekt OCRopus. DFKI, abgerufen am 29. Dezember 2017.
- Thomas M. Breuel: The OCRopus open source OCR system. Band 6815. International Society for Optics and Photonics, 28. Januar 2008, S. 68150F, doi:10.1117/12.783598.
- ocropus Projektwebseite. (Nicht mehr online verfügbar.) In: Google Project Hosting. 24. Dezember 2012, archiviert vom Original am 24. Dezember 2012; abgerufen am 30. Dezember 2017.
- Abschlussbericht (Öffentliche Fassung): TextGrid – Vernetzte Forschungsumgebung in den eHumanities. (PDF) 27. November 2012, abgerufen am 30. Dezember 2017.
- ocropy: older versions. In: GitHub Wiki. Abgerufen am 29. Dezember 2017.
- OCRopus 0.5. In: Google Groups. 2. Juni 2012, abgerufen am 5. Januar 2018.
- OCRopus doesn't even link with Tesseract by default.
- ocropy – release v1.0. GitHub, 2. November 2014, abgerufen am 29. Dezember 2017.
- ocropy: Python-based tools for document analysis and OCR. GitHub, abgerufen am 29. Dezember 2017.
- Releases ocropy. In: GitHub. Abgerufen am 5. Januar 2018.
- Thomas Breuel: OCR and Scene Text. Abgerufen am 9. Januar 2022 (englisch).
- kraken: OCR engine for all the languages. Abgerufen am 10. März 2019 (englisch).
- calamari: OCR Engine based on OCRopy and Kraken. Abgerufen am 10. März 2019 (englisch).
- ocropy wiki. GitHub, abgerufen am 29. Dezember 2017.