Deep Web
Das Deep Web (auch Hidden Web oder Invisible Web) bzw. Verstecktes Web bezeichnet den Teil des World Wide Webs, der bei einer Recherche über normale Suchmaschinen nicht auffindbar ist. Im Gegensatz zum Deep Web werden die über Suchmaschinen zugänglichen Webseiten Clear Web, Visible Web (Sichtbares Web), oder Surface Web (Oberflächenweb) genannt. Das Deep Web besteht zu großen Teilen aus themenspezifischen Datenbanken (Fachdatenbanken) und Webseiten. Zusammengefasst handelt es sich um Inhalte, die nicht frei zugänglich sind, und/oder Inhalte, die nicht von Suchmaschinen indiziert werden oder die nicht indiziert werden sollen.
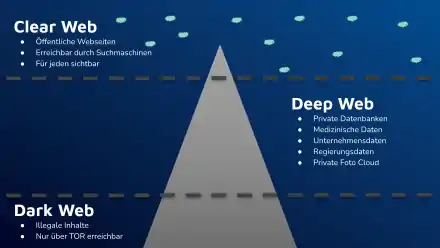
Arten des Deep Web
Nach Sherman & Price (2001)[1] werden fünf Typen des Invisible Web unterschieden: „Opaque Web“ (undurchsichtiges Web), „Private Web“ (privates Web), „Proprietary Web“ (Eigentümer-Web), „Invisible Web“ (unsichtbares Web) und „Truly invisible Web“ (tatsächlich unsichtbares Web).
Opaque Web
Das Opaque Web (engl. opaque zu dt.: undurchsichtig) sind Webseiten, die indiziert werden könnten, zurzeit aber aus Gründen der technischen Leistungsfähigkeit oder Aufwand-Nutzen-Relation nicht indexiert werden (Suchtiefe, Besuchsfrequenz).
Suchmaschinen berücksichtigen nicht alle Verzeichnisebenen und Unterseiten einer Website. Beim Erfassen von Webseiten steuern Webcrawler über Links zu den folgenden Webseiten. Webcrawler selbst können nicht navigieren, sich sogar in tiefen Verzeichnisstrukturen verlaufen, Seiten nicht erfassen und nicht zurück zur Startseite finden. Aus diesem Grund berücksichtigen Suchmaschinen oft höchstens fünf oder sechs Verzeichnisebenen. Umfangreiche und somit relevante Dokumente können in tieferen Hierarchieebenen liegen und wegen der beschränkten Erschließungstiefe von Suchmaschinen nicht gefunden werden.
Dazu kommen Dateiformate, die nur teilweise erfasst werden können (zum Beispiel PDF-Dateien, Google indexiert nur einen Teil einer PDF-Datei und stellt den Inhalt als HTML zur Verfügung).
Es besteht eine Abhängigkeit von der Häufigkeit der Indizierung einer Webseite (täglich, monatlich). Außerdem sind ständig aktualisierte Datenbestände, wie Online-Messdaten, betroffen. Webseiten ohne Hyperlinks oder Navigationssystem, unverlinkte Webseiten, Einsiedler-URLs oder Orphan-Seiten (orphan engl. für Waise) fallen ebenfalls darunter.
Private Web
Das Private Web beschreibt Webseiten, die indiziert werden könnten, aber auf Grund von Zugangsbeschränkungen des Webmasters nicht indexiert werden.
Dies können Webseiten im Intranet (interne Webseiten) sein, aber auch passwortgeschützte Daten (Registrierung und evtl. Passwort und Login), Zugang nur für bestimmte IP-Adressen, Schutz vor einer Indizierung durch den Robots Exclusion Standard oder Schutz vor einer Indizierung durch die Meta-Tag-Werte noindex, nofollow und noimageindex im Quelltext der Webseite.
Proprietary Web
Mit Proprietary Web sind Webseiten gemeint, die indexiert werden könnten, allerdings nur nach Anerkennung einer Nutzungsbedingung oder durch die Eingabe eines Passwortes zugänglich sind (kostenlos oder kostenpflichtig).
Derartige Webseiten sind üblicherweise erst nach einer Identifizierung (webbasierte Fachdatenbanken) abrufbar.
Invisible Web
Unter das Invisible Web fallen Webseiten, die rein technisch gesehen indexiert werden könnten, jedoch aus kaufmännischen oder strategischen Gründen nicht indexiert werden – wie zum Beispiel Datenbanken mit einem Webformular.
Truly Invisible Web
Mit Truly Invisible Web werden Webseiten bezeichnet, die aus technischen Gründen (noch) nicht indexiert werden können. Das können Datenbankformate sein, die vor dem WWW entstanden sind (einige Hosts), Dokumente, die nicht direkt im Browser angezeigt werden können, Nicht-Standardformate (zum Beispiel Flash), genauso wie Dateiformate, die aufgrund ihrer Komplexität nicht erfasst werden können (Grafikformate). Dazu kommen komprimierte Daten oder Webseiten, die nur über eine Benutzernavigation, die Grafiken (Image Maps) oder Skripte (Frames) benutzt, zu bedienen sind.
Datenbanken
Dynamisch erstellte Datenbank-Webseiten
Webcrawler bearbeiten fast ausschließlich statische Datenbank-Webseiten und können viele dynamische Datenbank-Webseiten nicht erreichen, da sie tiefer liegende Seiten nur durch Hyperlinks erreichen können. Jene dynamischen Seiten erreicht man aber oft erst durch Ausfüllen eines HTML-Formulars, was ein Crawler momentan noch nicht bewerkstelligen kann.
Kooperative Datenbankanbieter erlauben Suchmaschinen über Mechanismen wie JDBC einen Zugriff auf den Inhalt ihrer Datenbank, gegenüber den (normalen) nicht-kooperativen Datenbanken, die den Datenbankzugriff nur über ein Such-Formular bieten.
Hosts und Fachdatenbanken
Hosts sind kommerzielle Informationsanbieter, die Fachdatenbanken unterschiedlicher Informationsproduzenten innerhalb einer Oberfläche bündeln. Manche Datenbankanbieter (Hosts) oder Datenbankproduzenten selbst betreiben relationale Datenbanken, deren Daten nicht ohne eine spezielle Zugriffsmöglichkeit (Retrieval-Sprache, Retrieval-Tool) abgerufen werden können. Webcrawler verstehen weder die Struktur noch die Sprache, die benötigt wird, Informationen aus diesen Datenbanken auszulesen. Viele Hosts sind seit den 1970er-Jahren als Online-Dienst tätig und betreiben in ihren Datenbanken teilweise Datenbanksysteme, die lange vor dem WWW entstanden sind.
Beispiele für Datenbanken: Bibliothekskataloge (OPAC), Börsenkurse, Fahrpläne, Gesetzestexte, Jobbörsen, Nachrichten, Patente, Telefonbücher, Webshops, Wörterbücher.
Schätzung der Datenmenge
Nach einer Studie[2] der Firma BrightPlanet, die im Jahr 2001 veröffentlicht wurde, ergeben sich für das Deep Web folgende Eigenschaften:
Die Datenmenge des Deep Web sei etwa 400- bis 550-mal größer als die des Surface Web. Allein 60 der größten Websites im Deep Web enthalten etwa 7.500 Terabyte an Informationen, was die Menge des Surface Web um den Faktor 40 übersteigt. Es existieren angeblich mehr als 200.000 Deep-Websites. So haben laut der Studie Webseiten aus dem Deep Web durchschnittlich 50 % mehr Zugriffe pro Monat und seien öfter verlinkt als Webseiten aus dem Surface Web. Das Deep Web sei auch die am schnellsten wachsende Kategorie von neuen Informationen im Web. Trotzdem sei der im Internet suchenden Öffentlichkeit das Deep Web kaum bekannt. Mehr als die Hälfte des Deep Web sei in themenspezifischen Datenbanken angesiedelt.
Da BrightPlanet mit DQM2 eine kommerzielle Suchhilfe anbietet, ist die (möglicherweise stark überschätzte) Größenangabe mit großer Vorsicht zu betrachten. Die von BrightPlanet geschätzte Datenmenge des Deep Web[3] muss um einige Daten bereinigt werden:
- Dubletten aus Bibliothekskatalogen, die sich überschneiden
- Datensammlung des National Climatic Data Center (361 Terabyte)
- Daten der NASA (296 Terabyte)
- weitere Datensammlungen (National Oceanographic Data Center & National Geophysical Data Center, Right to know Network, Alexa, …)
Anhand der Anzahl der Datensätze zeigt sich, dass die Studie die Größe des Deep Web um das Zehnfache überschätzt. Allerdings hat allein der Informationsanbieter LexisNexis mit 4,6 Milliarden Datensätzen mehr als die Hälfte der Anzahl der Datensätze des Suchmaschinenprimus Google. Das Deep Web ist daher sicher weitaus größer als das Oberflächenweb.
In einer Untersuchung der University of California, Berkeley aus dem Jahr 2003 wurden folgende Werte als Umfang des Internets ermittelt: Surface Web – 167 Terabyte, Deep Web – 91.850 Terabyte.[4] Die gedruckten Bestände der Library of Congress in Washington, einer der größten Bibliotheken der Welt, umfassen 10 Terabyte.
Siehe auch
- Darknet – nicht mit dem Deep Web zu verwechselndes Peer-to-Peer-Overlay-Netz
- Information Retrieval
- Semantic Web
- Umweltinformationssystem
Literatur
- W. L. Warnick et al.: Searching the Deep Web. In: D-Lib Magazine, Januar 2001, Volume 7 Number 1, ISSN 1082-9873
- Chris Sherman, Gary Price:; The Invisible Web: Finding Hidden Internet Resources Search Engines Can't See, Cyberage Books 2001, ISBN 0-910965-51-X, Website zum Buch, Stand 2001
- Dirk Lewandowski, Philipp Mayr: Exploring the Academic Invisible Web. (PDF; 140 kB) In: Library Hi Tech, 24, 2006, 4, S. 529–539
- Dirk Lewandowski: Suchmaschinen verstehen. Springer, Heidelberg 2015, ISBN 978-3-662-44013-1.
- Alex Wright: Exploring a ‘Deep Web’ That Google Can’t Grasp. In: New York Times, 22. Februar 2009
- Denis Shestakov: Search Interfaces on the Web: Querying and Characterizing. TUCS Doctoral Dissertations 104, University of Turku, Juni 2008.
Weblinks
- Was die Suchmaschine nicht findet. Deutschlandradio, 30. August 2006
- Chris Sherman, Gary Price: The invisible web: uncovering sources search engines can’t see. (Memento vom 27. Juni 2004 im Internet Archive) University of Illinois at Urbana-Champaign, 2003
- The Deep Web. (Memento vom 23. Dezember 2005 im Internet Archive) Universitätsbibliothek Albany, New York
- Was Google nicht findet.. Universitätsbibliothek Bielefeld
- The Ultimate Guide to the Invisible Web. The Online Education Database
- Die dunkle Seite des Internets. In: Handelsblatt, 20. September 2010
Einzelnachweise
- Gary Price: The Invisible Web : uncovering information sources search engines can't see. CyberAge Books, Medford, N.J. 2001, ISBN 0-910965-51-X (englisch).
- Michael K. Bergman: The Deep Web: Surfacing Hidden Value. In: The Journal of Electronic Publishing, Jahrgang 7, 2001, Nr. 1
- Internet Archive Wayback Machine (Memento vom 14. März 2006 im Internet Archive)
- Internet (Memento des Originals vom 15. Oktober 2004 im Internet Archive) Info: Der Archivlink wurde automatisch eingesetzt und noch nicht geprüft. Bitte prüfe Original- und Archivlink gemäß Anleitung und entferne dann diesen Hinweis. sims.berkeley.edu