Information Retrieval
Information Retrieval [ˌɪnfɚˈmeɪʃən ɹɪˈtɹiːvəl] (IR) betrifft das Wiederauffinden von Information, meist durch Abruf aus Datenbanken. Das Fachgebiet beschäftigt sich mit computergestütztem Suchen nach komplexen Inhalten (also nicht z. B. nach Einzelwörtern) und fällt in die Bereiche Informationswissenschaft, Informatik und Computerlinguistik[1].
Komplexe Texte oder Bilddaten, die in großen Datenbanken gespeichert werden, sind für Außenstehende zunächst nicht zugänglich oder abrufbar. Das Wort retrieval bedeutet auf Deutsch Abruf bzw. Wiederauffinden. Beim IR geht es also darum, bestehende Informationen wieder aufzufinden. Etwas anderes wäre das Entdecken neuer Strukturen: Das gehört zur Knowledge Discovery in Databases mit Data-Mining und Text Mining.
Eng verwandt ist Document Retrieval, das hauptsächlich auf (Text-)Dokumente als zu ermittelnde Information abzielt.
Anwendungsbereich
IR-Methoden werden beispielsweise in Internet-Suchmaschinen (wie Google) verwendet. Man nutzt sie auch in digitalen Bibliotheken (z. B. zur Literatursuche) sowie bei Bildsuchmaschinen. Auch Antwortsysteme oder Spamfilter verwenden IR-Techniken.
Es ist schwierig, sich komplexe Information zu erschließen:
- Unsicherheit: In einer Datenbank mag es sein, dass keine Angaben über den Inhalt der enthaltenen Dokumente gespeichert (Texte, Bilder, Filme, Musik etc.) worden sind. Befragt man das System, erhält man mangelhafte, fehlerhafte oder gar keine Antworten. Bei Texten mangelt es z. B. an Beschreibungen von Homographen (Wörter, die gleich geschrieben werden; z. B. Bank - Geldinstitut, Sitzgelegenheit) und Synonymen (Bank und Geldinstitut).
- Vagheit: Der Benutzer kann die Art der Informationen, die er sucht, nicht in präzise und zielführende Suchbegriffe fassen (wie z. B. in SQL in relationalen Datenbanken). Seine Suchanfrage enthält daher zu vage Bedingungen.
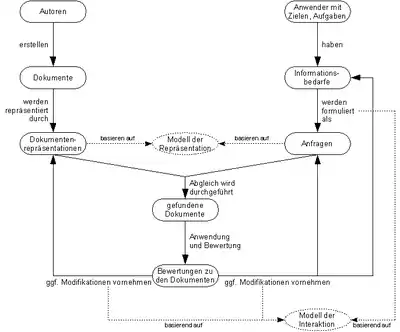
Generell sind am IR zwei (sich unter Umständen überschneidende) Personenkreise beteiligt (vgl. Abbildung rechts).
Der erste Personenkreis sind die Autoren der in einem IR-System gespeicherten Informationen, die sie entweder selbst einspeichern, oder aus anderen Informationssystemen auslesen lassen (wie es z. B. die Internet-Suchmaschinen praktizieren). Die in das System eingestellten Dokumente werden vom IR-System gemäß dem System-internen Modell der Repräsentation von Dokumenten in eine für die Verarbeitung günstige Form (Dokumentenrepräsentation) umgewandelt.
Die zweite Benutzergruppe, die Anwender, haben bestimmte, zum Zeitpunkt der Arbeit am IR-System akute Ziele oder Aufgaben, für deren Lösung ihnen Informationen fehlen. Diese Informationsbedürfnisse möchten Anwender mit Hilfe des Systems decken. Dafür müssen sie ihre Informationsbedürfnisse in einer adäquaten Form als Anfragen formulieren.
Die Form, in der die Informationsbedürfnisse formuliert werden müssen, hängt dabei von dem verwendeten Modell der Repräsentation von Dokumenten ab. Wie der Vorgang der Modellierung der Informationsbedürfnisse als Interaktion mit dem System abläuft (z. B. als einfache Eingabe von Suchbegriffen), wird vom Modell der Interaktion festgelegt.
Sind die Anfragen formuliert, dann ist es die Aufgabe des IR-Systems, die Anfragen mit den im System eingestellten Dokumenten unter Verwendung der Dokumentenrepräsentationen zu vergleichen und eine Liste der zu den Anfragen passenden Dokumente an die Benutzer zurückzugeben. Der Benutzer steht nun vor der Aufgabe, die gefundenen Dokumente gemäß seiner Aufgabe auf die Lösungsrelevanz hin zu bewerten. Das Resultat sind die Bewertungen zu den Dokumenten.
Anschließend haben die Benutzer drei Möglichkeiten:
- Sie können (meist nur in einem engen Rahmen) Modifikationen an den Repräsentationen der Dokumente vornehmen (z. B. indem sie neue Schlüsselwörter für die Indexierung eines Dokuments definieren).
- Sie verfeinern ihre formulierten Anfragen (zumeist um das Suchergebnis weiter einzuschränken)
- Sie ändern ihre Informationsbedürfnisse, weil sie nach dem Durchführen der Recherche feststellen, dass sie zur Lösung ihrer Aufgaben weitere, zuvor nicht als relevant eingestufte Informationen benötigen.
Der genaue Ablauf der drei Modifikationsformen wird vom Modell der Interaktion bestimmt. Zum Beispiel gibt es Systeme, die den Benutzer bei der Reformulierung der Anfrage unterstützen, indem sie die Anfrage unter Verwendung expliziter (d. h. dem System vom Benutzer in irgendeiner Form mitgeteilter) Dokumentenbewertungen automatisiert reformulieren.
Geschichte
Der Begriff „Information Retrieval“ wurde erstmals 1950 von Calvin N. Mooers verwendet. Vannevar Bush beschrieb 1945 in dem Essay As We May Think im Atlantic Monthly, wie man die Nutzung des vorhandenen Wissens durch den Einsatz von Wissensspeichern revolutionieren könne. Seine Vision hieß Memex. Dieses System sollte alle Arten von Wissensträgern speichern und mittels Links die gezielte Suche und das Stöbern nach Dokumenten ermöglichen. Bush dachte bereits an den Einsatz von Suchmaschinen und Retrievalwerkzeugen.
Einen entscheidenden Schub erhielt die Informationswissenschaft durch die Sputnikschocks. Der russische Satellit hielt den Amerikanern zum einen ihre eigene Rückständigkeit in der Weltraumforschung vor Augen, welche durch das Apollo-Programm erfolgreich beseitigt wurde. Zum anderen – und das war der entscheidende Punkt für die Informationswissenschaft – dauerte es ein halbes Jahr, den Signalcode des Sputnik zu knacken. Und das, obwohl der Entschlüsselungscode in einer russischen Zeitschrift längst zu lesen war, welche bereits in den amerikanischen Bibliotheken stand.
Mehr Information führt also nicht zu mehr Informiertheit. Im Gegenteil. Der sogenannte Weinberg-Report ist ein vom Präsidenten in Auftrag gegebenes Gutachten zu diesem Problem. Der Weinberg-Report berichtet von einer „Informationsexplosion“ und erklärt, dass Experten benötigt werden, die diese Informationsexplosion bewältigen. Also Informations-Wissenschaftler. Hans Peter Luhn arbeitete in den 1950er Jahren an textstatistischen Verfahren, die eine Basis für das automatische Zusammenfassen und Indexieren darstellen. Sein Ziel war es, individuelle Informationsprofile anzulegen und Suchterme hervorzuheben. Die Idee des Pushdienstes war geboren.
Eugene Garfield arbeitete in den 1950ern an Zitierindices, um so die verschiedenen Wege von Informationsübermittlung in Zeitschriften widerzuspiegeln. Dazu kopierte er Inhaltsverzeichnisse. 1960 gründete er das Institute for Scientific Information (ISI), eines der ersten kommerziellen Retrieval-Systeme.
SALTON, Gerard; MCGILL, Michael J. Introduction to modern information retrieval. mcgraw-hill, 1983.
Deutschland
In Deutschland entwickelte Siemens zwei Systeme, GOLEM (Großspeicherorientierte, listenorganisierte Ermittlungsmethode) und PASSAT (Programm zur automatischen Selektion von Stichwörtern aus Texten). PASSAT arbeitet unter Ausschluss von Stoppwörtern, bildet Wortstämme mithilfe eines Wörterbuches und gewichtet die Suchterme.
Seit den 1960er Jahren gilt die Informationswissenschaft als etabliert.
Frühe kommerzielle Informationsdienste
DIALOG ist ein von Roger K. Summit entwickeltes interaktives System zwischen Mensch und Maschine. Es ist wirtschaftlich orientiert und geht 1972 über die Regierungsdatenbanken ERIC und NTIS online. Das Projekt ORIBIT (heute Questel-Orbit) wurde durch Forschung und Entwicklung vorangetrieben unter der Leitung von Carlos A. Cuadra. 1962 geht das Retrievalsystem CIRC online und verschiedene Testläufe finden unter dem Codenamen COLEX statt. COLEX ist der direkte Vorläufer von Orbit, welches 1967 mit dem Schwerpunkt auf Forschungen der US Air Force online geht. Später verlagert sich der Schwerpunkt auf Medizininformationen. Das Suchsystem MEDLINE geht 1974 für die bibliographische Medizindatenbank MEDLARS online. OBAR ist ein von der Rechtsanwaltskammer in Ohio 1965 initiiertes Projekt. Es endet im System LexisNexis und erfasst schwerpunktmäßig Rechtsinformationen. Das System basiert auf der Volltextsuche, welche optimal für die Ohio-Urteile funktioniert.
Suchwerkzeuge im World Wide Web
Mit dem Internet wird Information Retrieval zum Massenphänomen. Ein Vorläufer war das ab 1991 verbreitete System WAIS, das verteiltes Retrieval im Internet ermöglichte. Die frühen Web-Browser NCSA Mosaic und Netscape Navigator unterstützen das WAIS-Protokoll, bevor die Internet-Suchmaschinen aufkamen und später dazu übergingen, auch Nicht-HTML-Dokumente zu indexieren. Zu den bekanntesten und populärsten Suchmaschinen gehören derzeit Google und Bing. Verbreitete Suchmaschinen für Intranets sind Autonomy, Convera, FAST, Verity sowie die Open-Source-Software Apache Lucene.
Grundbegriffe
Informationsbedarf
Der Informationsbedarf ist der Bedarf an handlungsrelevantem Wissen und kann dabei konkret und problemorientiert sein. Beim konkreten Informationsbedarf wird eine Fakteninformation benötigt. Also beispielsweise "Was ist die Hauptstadt von Frankreich?". Die Antwort "Paris" deckt den Informationsbedarf vollständig. Anders ist es beim problemorientierten Informationsbedarf. Hier werden mehrere Dokumente benötigt, um den Bedarf zu stillen. Zudem wird der problemorientierte Informationsbedarf nie ganz gedeckt werden können. Gegebenenfalls ergibt sich aus der erhaltenen Information sogar ein neuer Bedarf oder die Modifikation des ursprünglichen Bedarfs. Beim Informationsbedarf wird vom Nutzer abstrahiert. Das heißt, es wird der objektive Sachverhalt betrachtet.
Informationsbedürfnis
Das Informationsbedürfnis spiegelt den konkreten Bedarf beim anfragenden Nutzer wider. Es geht um das subjektive Bedürfnis des Nutzers.
Information Indexing und Information Retrieval
Um eine Suchanfrage so präzise wie möglich formulieren zu können, müsste man eigentlich wissen, was man nicht weiß. Es muss also ein Basiswissen vorhanden sein, um eine adäquate Suchanfrage zu verfassen. Zudem muss die natürlichsprachige Suchanfrage in eine Variante umgewandelt werden, die vom Retrievalsystem gelesen werden kann. Hier einige Beispiele für Suchanfrageformulierungen in verschiedenen Datenbanken. Gesucht werden Informationen über den Schauspieler "Johnny Depp" im Kinofilm "Chocolat".
LexisNexis: HEADLINE:(„Johnny Depp“ w/5 „Chocolat“)
DIALOG: (Johnny ADJ Depp AND Chocolat) ti
Google: “Chocolat” “Johnny Depp”
Der Nutzer gibt dabei vor, wie der Retrievalprozess abläuft, und zwar dies durch die Art und Weise seiner Suchanfrageformulierung im jeweils verwendeten System. Zu unterscheiden sind wort- und begrifforientierte Systeme. Begrifforientierte Systeme können die Mehrdeutigkeiten von Wörtern erkennen (z. B. Java = die Insel, Java = der Kaffee oder Java = die Programmiersprache). Über die Suchanfrage wird die Dokumentationseinheit (DE) angesprochen. Die DE stellt den informationellen Mehrwert der Dokumente dar. Das bedeutet, in der DE wird Information zu Autor, Jahrgang etc. verdichtet wiedergegeben. Je nach Datenbank werden entweder das komplette Dokument oder nur Teile davon erfasst.
Dokumentarische Bezugseinheit und Dokumentationseinheit
Weder die Dokumentarische Bezugseinheit (DBE) noch die Dokumentationseinheit (DE) sind das Originaldokument. Beide sind nur Stellvertreter desselben in der Datenbank. Zuerst wird die Dokumentationswürdigkeit eines Dokumentes geprüft. Das findet über formale und inhaltliche Kriterienkataloge statt. Ist ein Objekt für dokumentenwürdig befunden, wird eine DBE erstellt. Hier entscheidet sich, in welcher Form das Dokument abgespeichert wird. Werden einzelne Kapitel oder Seiten als DBE genommen oder das Dokument im Ganzen? Es schließt sich der informationspraktische Prozess an. Die DBE werden formal beschrieben und der Inhalt verdichtet. Dieser informationelle Mehrwert findet sich dann in der DE wieder, die als Stellvertreter für die DBE dient. Die DE repräsentiert die DBE und steht somit am Ende des Dokumentationsprozesses. Die DE dient dem Nutzer dazu, eine Entscheidung darüber zu treffen, ob er die DBE gebrauchen kann und anfordert oder eben nicht. Information Retrieval und Information Indexing sind aufeinander abgestimmt.
Kognitive Modelle
Diese sind Teil der empirischen Informationswissenschaft, da sie sich auf die Vorkenntnisse, den sozio-ökonomischen Hintergrund, die Sprachkenntnisse usw. der Nutzer beziehen und darüber Informationsbedarfs-, Nutzungs- und Nutzeranalysen anstellen.
Pull- und Pushdienste
Das Suchen nach Informationen beschreibt Marcia J. Bates als Berrypicking (dt. Beeren pflücken). Es reicht nicht aus, nur an einem Strauch respektive einer Datenbank nach Beeren bzw. Informationen zu suchen, damit der Korb voll wird. Es müssen mehrere Datenbanken angefragt und die Suchanfrage aufgrund neuer Informationen ständig modifiziert werden. Pulldienste werden überall da zur Verfügung gestellt, wo der Nutzer aktiv nach Informationen suchen kann. Pushdienste versorgen den Nutzer aufgrund eines abgespeicherten Informationsprofils mit Informationen. Diese Profildienste, sogenannte Alerts, speichern erfolgreich formulierte Suchanfragen ab und informieren den Nutzer über das Eintreffen neuer relevanter Dokumente.
Informationsbarrieren
Den Informationsfluss behindern verschiedene Faktoren. Solche Faktoren sind beispielsweise Zeit, Ort, Sprache, Gesetze und die Finanzierung.
Recall und Precision
Der Recall bezeichnet die Vollständigkeit der angezeigten Treffermenge. Die Precision dagegen berechnet die Genauigkeit der Dokumente aus der Treffermenge zu einer Suchanfrage. Precision bezeichnet den Anteil aller relevanten Dokumente an den selektierten Dokumenten einer Suchanfrage und ist damit das Maß der in der Trefferliste enthaltenen bezüglich der Aufgabenstellung bedeutungsvollen Dokumente. Recall hingegen beschreibt den Anteil aller relevanten Dokumente an der Gesamtzahl relevanter Dokumente der Dokumentensammlung. Dabei handelt es sich um das Maß für die Vollständigkeit einer Trefferliste. Beide Maße bilden entscheidende Kennzahlen für ein Information Retrieval-System. Ein ideales System würde in einer Suchanfrage alle relevanten Dokumente einer Dokumentensammlung unter Ausschluss nicht zutreffender Dokumente selektieren.
Recall:

Precision:

a = gefundene, relevante Treffer
b = gefundene, nichtrelevante DE / Ballast
c = relevante DE, die nicht gefunden wurden / Verlust
„c“ ist nicht direkt messbar, da man ja nicht wissen kann, wie viele DE nicht gefunden wurden, sofern man den Inhalt der Datenbank bzw. die DE nicht kennt, die aufgrund der Suchanfrage eigentlich hätten angezeigt werden müssen. Der Recall kann auf Kosten der Precision vergrößert werden und umgekehrt. Das gilt allerdings nicht bei einer Faktenfrage. Hier sind Recall und Precision gleich eins.
Relevanz und Pertinenz
Wissen kann relevant, muss aber nicht pertinent sein. Relevanz bedeutet, dass ein Dokument unter der Suchanfrage, die formuliert wurde, passend ausgegeben wurde. Wenn der Nutzer den Text aber bereits kennt oder er ihn nicht lesen will, weil er den Autor nicht mag oder keine Lust hat, einen Artikel in einer anderen Sprache zu lesen, ist das Dokument nicht pertinent. Pertinenz bezieht die subjektive Sicht des Nutzers mit ein.
| Objektiver Informationsbedarf | Subjektives Informationsbedürfnis (=Informationsnachfrage) |
| → Relevanz | → Pertinenz |
| Ein Dokument ist zur Befriedigung eines Informationsbedarfs relevant, wenn es objektiv: | Ein Dokument ist zur Befriedigung eines Informationsbedürfnisses pertinent, wenn es subjektiv: |
| Zur Vorbereitung einer Entscheidung dient | Zur Vorbereitung einer Entscheidung dient |
| Eine Wissenslücke schließt | Eine Wissenslücke schließt |
| Eine Frühwarnfunktion erfüllt | Eine Frühwarnfunktion erfüllt |
Voraussetzungen für erfolgreiches Information Retrieval sind das richtige Wissen, zum richtigen Zeitpunkt, am richtigen Ort, im richtigen Umfang, in der richtigen Form, mit der richtigen Qualität. Wobei "richtig" heißt, dass dieses Wissen entweder Pertinenz oder Relevanz besitzt.
Nützlichkeit
Wissen ist dann nützlich, wenn der Nutzer daraus neues handlungsrelevantes Wissen erzeugt und dieses in die Praxis umsetzt.
Aspekte der Relevanz
Relevanz ist die Relation zwischen der Suchanfrage (query) in Bezug auf das Thema und die systemseitigen Aspekte.
Binärer Ansatz
Der binäre Ansatz sagt aus, dass ein Dokument entweder relevant oder nicht-relevant ist. In der Realität ist das nicht unbedingt zutreffend. Hier spricht man eher von „Relevanzregionen“.
Relevanzverteilungen
Dafür können beispielsweise Themenketten gebildet werden. Ein Thema kann in mehreren Ketten vorkommen. Je häufiger ein Thema vorkommt, desto größer ist sein Gewichtungswert. Kommt das Thema in allen Ketten vor, liegt sein Wert bei 100; kommt es in keiner Kette vor, bei 0. Bei Untersuchungen haben sich drei verschiedene Verteilungen herauskristallisiert. Dabei ist anzumerken, dass diese Verteilungen nur bei größeren Dokumentenmengen zustande kommen. Bei kleineren Dokumentenmengen gibt es eventuell gar keine Regelmäßigkeiten.
Binäre Verteilung
Bei der binären Verteilung ist kein Relevanceranking möglich.





Informetrische Verteilung

- : Rangplatz
- : Konstante
- : konkreter Wert zwischen 1 und 2

Die informetrische Verteilung sagt aus: Wenn das erstplatzierte Dokument eine Relevanz von eins hat (bei ), dann hat das zweitplatzierte Dokument eine Relevanz von 0,5 (bei ) oder von 0,25 (bei ).



Dokumente
Es sei noch einmal darauf hingewiesen, dass in der Informationswissenschaft unterschieden wird zwischen dem Ausgangsdokument, der DBE und der DE. Aber wann ist „etwas“ eigentlich ein Dokument? Das entscheiden vier Kriterien: die Materialität (einschließlich des digitalen Vorhandenseins), die Intentionalität (Das Dokument trägt einen gewissen Sinn, eine Bedeutung), die Erarbeitung und die Wahrnehmung.
- "They have to be made into documents" Michael K. Buckland
Textuelle und nicht-textuelle Objekte
Objekte können in Textform auftreten, müssen es aber nicht. Bilder und Filme sind Beispiele für nicht-textuelle Dokumente. Textuelle und nicht-textuelle Objekte können in digitaler und in nicht-digitaler Form auftreten. Sind sie digital und treffen mehr als zwei Medienformen aufeinander (Ein Dokument besteht beispielsweise aus einer Videosequenz, einer Audiosequenz und Bildern), nennt man sie Multimedia. Die nicht-digital vorliegenden Objekte brauchen in der Datenbank einen digitalen Stellvertreter, etwa ein Foto.
Formal publizierte Textdokumente
Als formal publizierte Textdokumente werden alle Dokumente bezeichnet, die einen formalen Veröffentlichungsprozess durchlaufen haben. Das bedeutet, die Dokumente wurden vor der Veröffentlichung geprüft (z. B. durch einen Lektor). Ein Problem stellt die sogenannte „Graue Literatur“ dar. Diese ist zwar geprüft, aber nicht veröffentlicht worden.
Es existieren mehrere Ebenen von formal publizierten Dokumenten. Am Anfang steht die Arbeit, die Schöpfung des Autors. Gefolgt vom Ausdruck dieser Arbeit, der konkreten Realisierung (z. B. verschiedene Übersetzungen). Diese Realisierung wird manifestiert (z. B. in einem Buch). An unterster Stelle dieser Kette steht das Item, das einzelne Exemplar. In der Regel richtet sich die DBE auf die Manifestation. Ausnahmen sind aber möglich.
Informell publizierte Texte
Zu den informell publizierten Texten gehören vor allem Dokumente, die im Internet veröffentlicht wurden. Diese Dokumente sind zwar publiziert, aber nicht geprüft.
Eine Zwischenstufe von formell und informell publizierten Texten sind beispielsweise Wikis. Diese sind publiziert und kooperativ geprüft.
Nicht publizierte Texte
Hierzu zählen Briefe, Rechnung, interne Berichte, Dokumente im Intranet oder Extranet. Eben alle Dokumente, die nie öffentlich gemacht wurden.
Nicht-textuelle Dokumente
Bei den nicht-textuellen Dokumenten unterscheidet man zwei Gruppen. Zum einen die digital vorliegenden oder digitalisierbaren Dokumente, wie Filme, Bilder und Musik und zum anderen die nicht digitalen und nicht digitalisierbaren Dokumente. Zu letzteren gehören Fakten, wie chemische Stoffe und deren Eigenschaften und Reaktionen, Patienten und deren Symptome und Museumsobjekte. Die meisten nicht digitalisierbaren Dokumente entstammen den Disziplinen Chemie, Medizin und Wirtschaft. Sie werden in der Datenbank von der DE vertreten und oftmals zusätzlich durch Bilder, Videos und Audiodateien dargestellt.
Typologie von Retrievalsystemen
Struktur von Texten
Man differenziert zwischen strukturierten, schwach strukturierten und nicht-strukturierten Texten. Zu den schwach strukturierten Texten zählen alle Arten von Textdokumenten, die eine gewisse Struktur haben. Dazu zählen Kapitelnummern, Titel, Zwischenüberschriften, Abbildungen, Seitenzahlen etc. Über informationelle Mehrwerte können den Texten strukturierte Daten hinzugefügt werden. Nicht-strukturierte Texte kommen in der Realität kaum vor. In der Informationswissenschaft beschäftigt man sich hauptsächlich mit schwach strukturierten Texten. Dabei ist zu beachten, dass es nur um formale, nicht um syntaktische Strukturen geht. Es ergibt sich ein Problem mit dem Sinnzusammenhang der Inhalte.
„The man saw the pyramid on the hill with the telescope.“ Dieser Satz kann vierfach interpretiert werden. Daher bevorzugen einige Anbieter menschliche Indexer, da diese den Sinnzusammenhang erkennen und korrekt weiterverarbeiten können.
Information Retrievalsysteme können entweder mit oder ohne terminologische Kontrolle arbeiten. Arbeiten sie mit terminologischer Kontrolle, ergeben sich die Möglichkeiten sowohl intellektuell, als auch automatisch zu indexieren. Retrieval Systeme die ohne terminologische Kontrolle arbeiten, bearbeiten entweder den reinen Text oder der Prozess läuft über eine automatische Bearbeitung.
Retrievalsysteme und terminologische Kontrolle
Terminologische Kontrolle bedeutet nichts anderes als die Verwendung von kontrolliertem Vokabular. Das erfolgt über Dokumentationssprachen (Klassifikationen, Schlagwortmethode, Thesauri, Ontologien). Die Vorteile liegen darin, dass der Rechercheur und der Indexer über dieselben Ausdrücke und Formulierungsmöglichkeiten verfügen. Daher ergeben sich keine Probleme mit Synonymen und Homonymen. Nachteile von kontrolliertem Vokabular sind etwa die mangelnde Berücksichtigung von Sprachentwicklungen, sowie das Problem, dass diese Kunstsprachen nicht von jedem Nutzer korrekt angewandt werden. Eine weitere Rolle spielt natürlich der Preis. Intellektuelles Indexieren ist sehr viel teurer als automatisches.
Insgesamt lassen sich vier Fälle unterscheiden:
| Rechercheur | Indexer |
|---|---|
| Kontrolliertes Vokabular → Fachleute | Kontrolliertes Vokabular |
| Natürlichsprachig → Kontrolliertes Vokabular wirkt im Hintergrund durch Suchanfrageerweiterung mittels Ober- und Unterbegriffen mit | Natürlichsprachig → Kontrolliertes Vokabular wirkt im Hintergrund durch Suchanfrageerweiterung mittels Ober- und Unterbegriffen mit |
| Natürlichsprachig → System leistet Übersetzungsarbeit | Kontrolliertes Vokabular |
| Kontrolliertes Vokabular | Natürlichsprachiges Vokabular |
Bei der Variante ohne terminologische Kontrolle wird am besten mit den Volltexten gearbeitet. Das funktioniert allerdings nur bei sehr kleinen Datenbanken. Die Terminologie der Dokumente muss von den Nutzern genau gekannt werden. Der Prozess mit terminologischer Kontrolle setzt eine informationslinguistische Bearbeitung (Natural Language Processing = NLP) der Dokumente voraus.
Informationslinguistische Textbearbeitung
Die informationslinguistische Textbearbeitung geht wie folgt vor. Zuerst wird das Schriftsystem erkannt. Ist es beispielsweise ein lateinisches oder arabisches Schriftsystem. Danach folgt die Spracherkennung. Nun werden Text, Layout und Navigation voneinander getrennt. An dieser Stelle gibt es zwei Möglichkeiten. Zum einen die Zerlegung der Wörter in n-Gramme oder die Worterkennung. Egal für welche Methode man sich entscheidet, schließen sich Stoppwortmarkierung, Eingabefehlererkennung und -korrektur sowie Eigennamenerkennung und die Bildung von Grund- bzw. Stammformen an. Es werden Komposita zerlegt, Homonyme und Synonyme erkannt und abgeglichen und das semantische Umfeld oder das Umfeld nach Ähnlichkeit untersucht. Die letzten beiden Schritte sind die Übersetzung des Dokumentes und die Anaphoraauflösung. Es kann nötig sein, dass während des Ablaufes das System mit dem Nutzer in Verbindung tritt.
Retrievalmodelle
Es existieren mehrere konkurrierende Retrievalmodelle, die sich aber keineswegs ausschließen müssen. Zu diesen Modellen zählen das Boolesche und das erweiterte Boolesche Modell. Das Vektorraummodell und das probabilistische Modell sind Modelle, die auf der Textstatistik beruhen. Zu den Linktopologischen Modellen gehören der Kleinberg-Algorithmus und der PageRank. Schließlich gibt es noch das Netzwerkmodell und die Nutzer-/Nutzungsmodelle, welche die Textnutzung und den Nutzer an seinem spezifischen Standort untersuchen.
Boolesches Modell
George Boole veröffentlichte 1854 seine „Boolesche Logik“ und ihre binäre Sicht der Dinge. Sein System hat drei Funktionen oder auch Operatoren: UND, ODER und NICHT. Bei diesem System ist keine Sortierung nach Relevanz möglich. Um ein Relevanzranking zu ermöglichen, wurde das Boolesche Modell um Gewichtungswerte erweitert und die Operatoren mussten uminterpretiert werden.
Textstatistik
In der Textstatistik werden die im Dokument auftretenden Terme analysiert. Die Gewichtungsfaktoren heißen hier WDF und IDF.
Within-document Frequency (WDF): Anzahl des vorkommenden Terms/ Anzahl aller Wörter
Der WDF beschreibt die Häufigkeit eines Wortes in einem Dokument. Je Häufiger ein Wort in einem Dokument vorkommt, desto größer sein WDF
Inverse Dokumenthäufigkeit englisch Inverse document frequency weight (IDF) Gesamte Anzahl an Dokumenten in der Datenbank/ Anzahl der Dokumente mit dem Term
Der IDF beschreibt die Häufigkeit, mit der ein Dokument mit einem bestimmten Term in einer Datenbank vorkommt. Je häufiger ein Dokument mit einem bestimmten Term in der Datenbank vorkommt, desto kleiner sein IDF.
Die zwei klassischen Modelle der Textstatistik sind das Vektorraummodell und das probabilistische Modell. Im Vektorraummodell spannen n-Wörter einen n-dimensionalen Raum auf. Die Ähnlichkeit der Wörter zueinander wird über die Winkel ihrer Vektoren zueinander berechnet. Beim probabilistischen Modell wird die Wahrscheinlichkeit berechnet, mit der ein Dokument auf eine Suchanfrage zutrifft. Ohne Zusatzinformationen ist das probabilistische Modell dem IDF ähnlich.
Linktopologische Modelle
Dokumente sind im WWW untereinander und miteinander verlinkt. Sie bilden somit einen Raum von Links. Der Kleinberg-Algorithmus nennt diese Links „Hub“ (ausgehende Links) und „Authority“ (eingehende Links). Die Gewichtungswerte entstehen darüber, inwiefern Hubs auf „gute“ Authorities treffen und Authorities von „guten“ Hubs gelinkt werden. Ein weiteres linktopologisches Modell ist der PageRank von Sergey Brin und Lawrence Page. Er beschreibt die Wahrscheinlichkeit, mit der ein nach dem Zufallsprinzip Surfender eine Seite findet.
Clustermodell
Clusterverfahren versuchen, Dokumente zu klassifizieren, so dass ähnliche oder miteinander in Beziehung stehende Dokumente in einem gemeinsamen Dokumentenpool zusammengefasst werden. Dadurch tritt eine Beschleunigung des Suchverfahrens ein, da sämtliche relevanten Dokumente im günstigsten Fall mit einem einzigen Zugriff selektiert werden können. Neben Dokumentenähnlichkeiten spielen aber auch Synonyme als semantisch ähnliche Wörter eine bedeutende Rolle. So sollte eine Suche nach dem Begriff „Wort“ auch eine Trefferliste für Kommentar, Bemerkung, Behauptung oder Term präsentieren.
Probleme entstehen aus der Art der Zusammenfassung von Dokumenten:
- Die Cluster müssen stabil und vollständig sein.
- Die Zahl der Dokumente in einem Cluster und damit die resultierende Trefferliste kann bei speziellen Dokumentationen mit homogenen Dokumenten sehr hoch sein. Im umgekehrten Fall kann die Zahl der Cluster wachsen bis zum Extremfall, in dem Cluster nur aus jeweils einem Dokument bestehen.
- Die Überschneidungsrate der Dokumente, die in mehr als einem Cluster liegen, ist kaum kontrollierbar.
Nutzer-Nutzungsmodell
Bei dem Nutzer-Nutzungsmodell ist die Häufigkeit der Nutzung einer Website ein Rangkriterium. Zusätzlich fließen Hintergrundinformationen beispielsweise über den Standort des Nutzers bei geographischen Anfragen mit ein.
Beim systematischen Suchen ergeben sich Rückkopplungsschleifen. Diese laufen entweder automatisch oder der Nutzer wird wiederholt aufgefordert, Ergebnisse als relevant oder nicht-relevant zu markieren, ehe die Suchanfrage modifiziert und wiederholt wird.
Oberflächenweb und Deep Web
Das Oberflächenweb liegt im Web und ist kostenlos für alle Nutzer erreichbar. Im Deep Web liegen etwa Datenbanken, deren Suchoberflächen über das Oberflächenweb zu erreichen sind. Ihre Informationen sind aber in der Regel kostenpflichtig. Es lassen sich drei Arten von Suchmaschinen unterscheiden. Suchmaschinen wie Google arbeiten algorithmisch, das Open Directory Project ist ein intellektuell erstellter Webkatalog und Metasuchmaschinen beziehen ihren Content aus mehreren anderen Suchmaschinen, die sich ansprechen. In der Regel verwenden intellektuell erstellte Webkataloge nur die Einstiegsseite einer Website als Bezugsquelle für die DBE. Bei algorithmisch arbeitenden Suchmaschinen wird jede Webseite verwendet.
Architektur eines Retrievalsystems
Es gibt digitale und nicht-digitale Speichermedien, wie etwa Steilkarten, Bibliothekskataloge und Sichtloskarten. Digitale Speichermedien werden von der Informatik erarbeitet und sind Beschäftigungsbereich der Informationswissenschaft. Man unterscheidet zwischen der Dateistruktur und ihrer Funktion. Darüber hinaus gibt es Schnittstellen des Retrievalsystems mit den Dokumenten und mit ihren Nutzern. Bei der Schnittstelle zwischen System und Dokument unterscheidet man wieder drei Bereiche. Das Finden von Dokumenten, das sogenannte Crawling, die Kontrolle dieser gefundenen Dokumente auf Updates und die Einordnung in ein Feldschema. Die Dokumente werden entweder intellektuell oder automatisch erfasst und weiter verarbeitet. Dabei werden die DE zweifach abgespeichert. Einmal als Dokumentendatei und zusätzlich noch als invertierte Datei, welche als Register oder Index den Zugriff auf die Dokumentendatei erleichtern soll. Nutzer und System treten in folgender Weise in Kontakt. Der Nutzer verfasst
- eine Anfrageformulierung, erhält
- eine Trefferliste, lässt sich
- die Dokumentationseinheiten anzeigen und verarbeitet sie
- lokal weiter.
Zeichensätze
1963 entstand der ASCII-Code (American Standard Code for Information Interchange). Sein 7 bit-Code konnte 128 Zeichen erfassen und abbilden. Er wurde später auf 8 bit (= 256 Zeichen) erweitert. Der bislang größte Zeichensatz Unicode umfasst 4 Byte, also 32 bit und soll alle Zeichen abbilden, die überhaupt auf der Welt genutzt werden. Die ISO 8859 (International Organisation for Standardization) regelt darüber hinaus sprachspezifische Varianten, wie etwa das „ß“ in der deutschen Sprache.
Aufnahme neuer Dokumente in die Datenbasis
Neue Dokumente können sowohl intellektuell, als auch automatisch der Datenbasis hinzugefügt werden. Bei der intellektuellen Aufnahme neuer Dokumente ist ein Indexer verantwortlich und entscheidet, welche Dokumente wie aufgenommen werden. Der automatische Prozess erfolgt durch einen „Robot“ oder einen „Crawler“. Grundlage ist eine bekannte Menge an Webdokumenten, eine sogenannte „seed list“. Die Links aller Webseiten, die diese Liste enthält, ist nun Aufgabe der Crawler. Die URL der jeweiligen Seiten wird geprüft, ob sie bereits in der Datenbasis vorhanden ist oder nicht. Darüber hinaus werden Spiegel und Dubletten erkannt und gelöscht.
Best-First Crawler
Einer der Best-First-Crawler ist der Page Rank-Crawler. Er sortiert die Links nach Anzahl und Popularität der eingehenden Seiten. Zwei weitere sind der Fish-Search- und der Shark-Search-Crawler. Ersterer beschränkt seine Arbeit auf Bereiche im Web, in denen sich relevante Seiten konzentrieren. Der Shark-Search-Crawler verfeinert diese Methode, indem er zusätzliche Informationen zum Beispiel aus den Ankertexten zieht, um ein Relevanzurteil zu treffen. Jeder Seitenbetreiber hat die Möglichkeit, seine Seite gegen Crawler zu verschließen.
Crawling im Deep Web
Damit ein Crawler auch im Deep Web erfolgreich arbeiten kann, muss er verschiedene Anforderungen erfüllen. Zum einen muss er die Suchmaske der Datenbank „verstehen“, um eine adäquate Suchanfrage formulieren zu können. Darüber hinaus muss er Trefferlisten verstehen und Dokumente anzeigen können. Das funktioniert allerdings nur bei kostenlosen Datenbanken. Wichtig für Deep Web Crawler ist es, dass sie Suchargumente derart formulieren können, dass alle Dokumente der Datenbank angezeigt werden. Ist in der Suchmaske ein Jahrgangsfeld vorhanden, müsste der Crawler der Reihe nach alle Jahrgänge anfragen, um an alle Dokumente zu gelangen. Bei Stichwortfeldern ist eine adaptive Strategie am sinnvollsten. Sind die Daten einmal erfasst, muss der Crawler nur noch die Updates der gefundenen Seiten erfassen. Um die DE möglichst aktuell zu halten, gibt es mehrere Möglichkeiten. Entweder die Seiten werden im selben Abstand regelmäßig besucht, was allerdings die Ressourcen weit übersteigen würde und daher unmöglich ist, oder der Besuch nach Zufall, was allerdings eher suboptimal funktioniert. Eine dritte Möglichkeit wäre der Besuch nach Prioritäten. Beispielsweise nach dem Takt ihrer Änderungen (seitenzentriert) oder der Häufigkeit ihrer Aufrufe oder Downloads (nutzerzentriert). Weitere Aufgaben der Crawler sind es, Spam, Dubletten sowie Spiegel zu erkennen. Die Erkennung von Dubletten erfolgt in der Regel über den Vergleich der Pfade. Die Vermeidung von Spam gestaltet sich etwas schwieriger, da Spam oft versteckt auftritt.
FIFO (first in first out)-Crawler
Zu den FIFO-Crawlern gehören der Breadth-First-Crawler, welcher allen Links einer Seite folgt, diese abarbeitet und den Links der gefundenen Seiten weiter folgt und der Depth-First-Crawler. Dieser arbeitet im ersten Schritt wie der Breadth-First-Crawler, trifft im zweiten Schritt allerdings eine Auswahl, welchen Links er weiter folgt und welchen nicht.
Thematische Crawler
Thematische Crawler sind auf eine Disziplin spezialisiert und daher geeignet für Fachexperten. Thematisch nicht relevante Seiten werden identifiziert und „getunnelt“. Dennoch werden die Links dieser getunnelten Seiten weiter verfolgt, um weitere relevante Seiten zu finden. Distiller finden derweil einen günstigen Ausgangspunkt für die Crawler, indem sie Taxonomien und Musterdokumente nutzen. Classifier eruieren diese Seiten auf Relevanz. Der ganze Vorgang läuft semiautomatisch, da Taxonomien und Musterdokumente regelmäßig aktualisiert werden müssen. Darüber hinaus wird eine Begriffsordnung benötigt.
Speichern und Indexieren
Die gefundenen Dokumente werden in die Datenbasis kopiert. Dafür werden zwei Dateien angelegt, zum einen die Dokumentendatei, zum anderen eine invertierte Datei. In der invertierten Datei werden alle Wörter oder Phrasen geordnet und nach Alphabet oder einem anderen Sortierkriterium aufgelistet. Ob man einen Wortindex oder einen Phrasenindex verwendet, hängt vom Feld ab. Bei einem Autorenfeld eignet sich beispielsweise der Phrasenindex wesentlich besser als der Wortindex. In der invertierten Datei finden sich Angaben über die Position der Wörter oder Phrasen im Dokument und Strukturinformationen. Strukturinformationen können für das Relevanceranking nützlich sein. Wenn etwa angegeben ist, dass ein Wort größer geschrieben wurde, kann man dieses auch höher gewichten. Die Wörter und Phrasen werden sowohl in der richtigen Reihenfolge geschrieben, als auch rückwärts abgelegt. Das ermöglicht eine offene Linkstrukturierung. Die Speicherung der invertierten Datei erfolgt in einem Datenbankindex.
Klassifikation von Retrievalmodellen
Eine zweidimensionale Klassifikation von IR-Modellen zeigt die nachstehende Abbildung. Folgende Eigenschaften lassen sich bei den verschiedenen Modellen in Abhängigkeit von ihrer Einordnung in der Matrix beobachten:
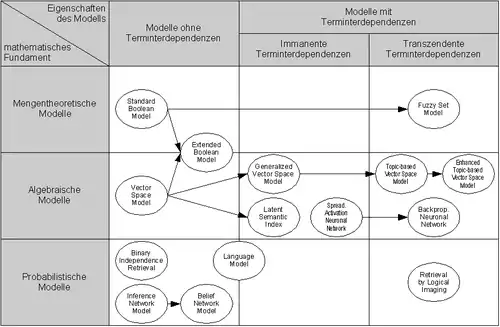
- Dimension: mathematisches Fundament
- Algebraische Modelle stellen Dokumente und Anfragen als Vektoren, Matrizen oder Tupel dar, die zur Berechnung von paarweisen Ähnlichkeiten über eine endliche Anzahl algebraischer Rechenoperationen in ein eindimensionales Ähnlichkeitsmaß überführt werden.
- Mengentheoretische Modelle zeichnen sich dadurch aus, dass sie natürlichsprachliche Dokumente auf Mengen abbilden und die Ähnlichkeitsbestimmung von Dokumenten (in erster Linie) auf die Anwendung von Mengenoperationen zurückführen.
- Probabilistische Modelle sehen den Prozess der Dokumentensuche bzw. der Bestimmung von Dokumentenähnlichkeiten als ein mehrstufiges Zufallsexperiment an. Zur Abbildung von Dokumentenähnlichkeiten wird daher auf Wahrscheinlichkeiten und probabilistische Theoreme (insbesondere auf den Satz von Bayes) zurückgegriffen.
- Dimension: Eigenschaften des Modells
- Modelle mit immanenten Terminterdependenzen zeichnen sich dadurch aus, dass sie vorhandene Interdependenzen zwischen Termen berücksichtigen und ihnen somit – im Unterschied zu den Modellen ohne Terminterdependenzen – nicht die implizite Annahme zu Grunde liegt, dass Terme orthogonal bzw. unabhängig voneinander sind. Die Modelle mit den immanenten Terminterdependenzen grenzen sich von den Modellen mit den transzendenten Terminterdependenzen dadurch ab, dass das Ausmaß einer Interdependenz zwischen zwei Termen aus dem Dokumentenbestand, in einer vom Modell bestimmten Weise, abgeleitet wird – also dem Modell innewohnend (immanent) ist. Die Interdependenz zwischen zwei Termen wird bei dieser Klasse von Modellen direkt oder indirekt aus der Kookkurrenz der beiden Terme abgeleitet. Unter Kookkurrenz versteht man dabei das gemeinsame Auftreten zweier Terme in einem Dokument. Dieser Modellklasse liegt somit die Annahme zu Grunde, dass zwei Terme zueinander interdependent sind, wenn sie häufig gemeinsam in Dokumenten vorkommen.
- Modelle ohne Terminterdependenzen zeichnen sich dadurch aus, dass jeweils zwei verschiedene Terme als vollkommen unterschiedlich und keinesfalls miteinander verbunden angesehen werden. Dieser Sachverhalt wird in der Literatur häufig auch als Orthogonalität von Termen bzw. als Unabhängigkeit von Termen bezeichnet.
- Wie bei den Modellen mit immanenten Terminterdependenzen, liegt auch den Modellen mit transzendenten Terminterdependenzen keine Annahme über die Orthogonalität oder Unabhängigkeit von Termen zu Grunde. Im Unterschied zu den Modellen mit immanenten Terminterdependenzen können die Interdependenzen zwischen den Termen bei den Modellen mit transzendenten Terminterdependenzen nicht ausschließlich aus dem Dokumentenbestand und dem Modell abgeleitet werden. Das heißt, dass die den Terminterdependenzen zu Grunde liegende Logik als über das Modell hinausgehend (transzendent) modelliert wird. Das bedeutet, dass in den Modellen mit transzendenten Terminterdependenzen das Vorhandensein von Terminterdependenzen explizit modelliert wird, aber dass die konkrete Ausprägung einer Terminterdependenz zwischen zwei Termen direkt oder indirekt von außerhalb (z. B. von einem Menschen) vorgegeben werden muss.
Information-Retrieval hat Querbezüge zu verschiedenen anderen Gebieten, z. B. Wahrscheinlichkeitstheorie der Computerlinguistik.
Literatur
- Gerard Salton; Michael J. McGill, Introduction to modern information retrieval. mcgraw-hill, 1983.
- James D. Anderson, J. Perez-Carballo: Information retrieval design: principles and options for information description, organization, display, and access in information retrieval databases, digital libraries, and indexes (Memento vom 31. Dezember 2008 im Internet Archive) University Publishing Solutions, 2005.
- Michael C. Anderson: Retrieval. In: A. D. Baddeley, M. W. Eysenck, M. C. Anderson. Memory. Psychology Press, Hove, New York 2009, ISBN 978-1-84872-001-5, S. 163–189.
- R. Baeza-Yates, B. Ribeiro-Neto: Modern Information Retrieval. ACM Press, Addison-Wesley, New York 1999.
- Reginald Ferber: Information Retrieval. dpunkt.verlag, 2003, ISBN 3-89864-213-5.
- Dominik Kuropka: Modelle zur Repräsentation natürlichsprachlicher Dokumente. Ontologie-basiertes Information-Filtering und -Retrieval mit relationalen Datenbanken. ISBN 3-8325-0514-8.
- Christopher D. Manning, Prabhakar Raghavan, und Hinrich Schütze: Introduction to Information Retrieval. Cambridge: Cambridge university press, 2008, ISBN 978-0-521-86571-5.
- Dirk Lewandowski: Suchmaschinen verstehen. Springer, Heidelberg 2015, ISBN 978-3-662-44013-1.
- Dirk Lewandowski: Web Information Retrieval. In: Information: Wissenschaft und Praxis (nfd). 56 (2005) 1, S. 5–12, ISSN 1434-4653
- Dirk Lewandowski: Web Information Retrieval, Technologien zur Informationssuche im Internet. (= Informationswissenschaft. 7). DGI Schrift. Frankfurt am Main 2005, ISBN 3-925474-55-2.
- Eleonore Poetzsch: Information Retrieval - Einführung in Grundlagen und Methoden. E. Poetzsch Verlag, Berlin 2006, ISBN 3-938945-01-X.
- Gerard Salton, Michael J. McGill: Introduction to modern information retrieval. McGraw-Hill, New York 1983.
- Wolfgang G. Stock: Information Retrieval. Informationen suchen und finden. Oldenbourg, München/ Wien 2007, ISBN 978-3-486-58172-0.
- Alexander Martens: Visualisierung im Information Retrieval - Theorie und Praxis angewandt in Wikis als Alternative zu Semantic Web. BoD, Norderstedt, ISBN 978-3-8391-2064-4.
- Matthias Nagelschmidt, Klaus Lepsky, Winfried Gödert: Informationserschließung und Automatisches Indexieren: Ein Lehr- und Arbeitsbuch. Springer, Berlin, Heidelberg 2012, ISBN 978-3-642-23512-2.
Weblinks
- Fachgruppe Information Retrieval der Gesellschaft für Informatik
- Norbert Fuhr: Vorlesung „Information Retrieval“ an der Universität Duisburg-Essen, 2006, Materialien
- Karin Haenelt: Seminar „Information Retrieval“ Universität Heidelberg, 2015
- Heinz-Dirk Luckhardt: Information Retrieval, Universität Saarland, im Virtuellen Handbuch Informationswirtschaft (Memento vom 30. November 2001 im Internet Archive)
- UPGRADE, The European Journal for the Informatics Professional, Information Retrieval and the Web Band III, Nr. 3, Juni 2002.
- C. J. van Rijsbergen: Information Retrieval, 1979
- Information Retrieval Facility (IRF)
Einzelnachweise
- Information Retrieval 1, Grundlagen, Modelle und Anwendungen, Andreas Henrich, Version: 1.2 (Rev: 5727, Stand: 7. Januar 2008), Otto-Friedrich-Universität Bamberg, Lehrstuhl für Medieninformatik, 2001 – 2008