Algorithmus von Prim
Der Algorithmus von Prim dient der Berechnung eines minimalen Spannbaumes in einem zusammenhängenden, ungerichteten, kantengewichteten Graphen.
Der Algorithmus wurde 1930 vom tschechischen Mathematiker Vojtěch Jarník entwickelt. 1957 wurde er zunächst von Robert C. Prim und dann 1959 von Edsger W. Dijkstra wiederentdeckt. Daher wird der Algorithmus in der Literatur auch gelegentlich unter anderen Namen geführt, so etwa Prim-Dijkstra-Algorithmus oder Algorithmus von Jarnik, Prim und Dijkstra, im englischen Sprachraum auch Jarnik’s algorithm oder DJP algorithm.
Beschreibung
Der Algorithmus beginnt mit einem trivialen Graphen , der aus einem beliebigen Knoten des gegebenen Graphen besteht. In jedem Schritt wird nun eine Kante mit minimalem Gewicht gesucht, die einen weiteren Knoten mit verbindet. Diese und der entsprechende Knoten werden zu hinzugefügt. Das Ganze wird solange wiederholt, bis alle Knoten in vorhanden sind; dann ist ein minimaler Spannbaum:

- Wähle einen beliebigen Knoten als Startgraph .
- Solange noch nicht alle Knoten enthält:
- Wähle eine Kante mit minimalem Gewicht aus, die einen noch nicht in enthaltenen Knoten mit verbindet.
- Füge und dem Graphen hinzu.


Der skizzierte Algorithmus wird durch folgenden Pseudocode beschrieben:
G: Graph VG: Knotenmenge von G w: Gewichtsfunktion für Kantenlänge r: Startknoten (r ∈ VG) Q: Prioritätswarteschlange π[u]: Elternknoten von Knoten u im Spannbaum Adj[u]: Adjazenzliste von u (alle Nachbarknoten) wert[u]: Abstand von u zum entstehenden Spannbaum
algorithmus_von_prim(G,w,r) 01 Q VG //Initialisierung 02 für alle u ∈ Q 03 wert[u] ∞ 04 π[u] 0 05 wert[r] 0 06 solange Q ≠ 07 u extract_min(Q) 08 für alle v ∈ Adj[u] 09 wenn v ∈ Q und w(u,v) < wert[v] 10 dann π[v] u 11 wert[v] w(u,v)


Nachdem der Algorithmus endet, ergibt sich der minimale Spannbaum wie folgt:

Zum Finden der leichtesten Schnittkante kann eine Prioritätswarteschlange verwendet werden. Dabei werden vom Algorithmus insgesamt extractMin-Operationen und decreaseKey-Operationen ausgeführt. Mit einem Fibonacci-Heap (extractMin in amortisiert und decreaseKey in amortisiert ) als Datenstruktur ergibt sich eine Gesamtlaufzeit von .





Die Schleife ist inhärent sequentiell, da sich die leichteste Kante im Schnitt von und mit dem Hinzufügen eines neuen Knotens zu ändern kann. Es ist jedoch für die Korrektheit wichtig, dass immer die aktuell leichteste Kante ausgewählt wird.


Auf einer Parallel Random Access Machine mit insgesamt Prozessoren lässt sich der Zugriff auf die Prioritätswarteschlange zu konstanter Zeit beschleunigen[1], sodass sich eine Gesamtlaufzeit in ergibt. Insgesamt bieten der Algorithmus von Kruskal und der Algorithmus von Borůvka bessere Parallelisierungsansätze.


Beispiel
In diesem Beispiel wird der Ablauf des Algorithmus von Prim an einem einfachen Graphen gezeigt. Der aktuelle Baum ist jeweils grün hervorgehoben. Alle Knoten, die im jeweiligen Schritt über eine einzelne Kante mit dem Graphen verbunden werden können, sind zusammen mit der jeweiligen Kante geringsten Gewichts blau hervorgehoben. Der Knoten und die Kante, die hinzugefügt werden, sind hellblau markiert.
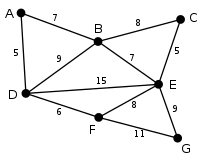 |
Dies ist der Graph, zu dem der Algorithmus von Prim einen minimalen Spannbaum berechnet. Die Zahlen bei den einzelnen Kanten geben das jeweilige Kantengewicht an. |
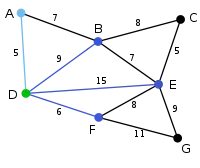 |
Als Startknoten für den Graphen wird der Knoten gewählt. (Es könnte auch jeder andere Knoten ausgewählt werden.) Mit dem Startknoten können die Knoten , , und jeweils unmittelbar durch die Kanten , , und verbunden werden. Unter diesen Kanten ist diejenige mit dem geringsten Gewicht und wird deshalb zusammen mit dem Knoten zum Graphen hinzugefügt. |
 |
Mit dem bestehenden Graphen kann der Knoten durch die Kanten oder , der Knoten durch die Kante und der Knoten durch die Kante verbunden werden. Unter diesen vier Kanten ist diejenige mit dem geringsten Gewicht und wird deshalb zusammen mit dem Knoten zum Graphen hinzugefügt. |
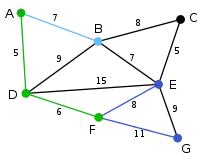 |
Mit dem bestehenden Graphen kann der Knoten durch die Kanten oder , der Knoten durch die Kanten oder und der Knoten durch die Kante verbunden werden. Unter diesen Kanten ist diejenige mit dem geringsten Gewicht und wird deshalb zusammen mit dem Knoten zum Graphen hinzugefügt. |
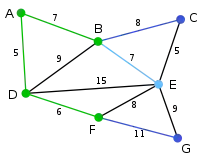 |
Mit dem bestehenden Graphen kann der Knoten durch die Kante , der Knoten durch die Kanten , oder und der Knoten durch die Kante verbunden werden. Unter diesen Kanten ist diejenige mit dem geringsten Gewicht und wird deshalb zusammen mit dem Knoten zum Graphen hinzugefügt. |
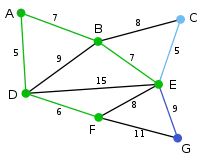 |
Mit dem bestehenden Graphen kann der Knoten durch die Kanten oder und der Knoten durch die Kanten oder verbunden werden. Unter diesen Kanten ist diejenige mit dem geringsten Gewicht und wird deshalb zusammen mit dem Knoten zum Graphen hinzugefügt. |
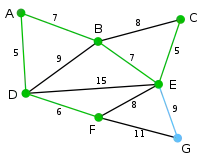 |
Der verbliebene Knoten kann durch die Kanten oder mit dem Graphen verbunden werden. Da unter diesen beiden das geringere Gewicht hat, wird sie zusammen mit dem Knoten zum Graphen hinzugefügt. |
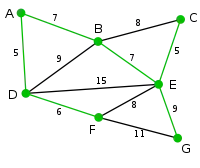 |
Der Graph enthält jetzt alle Knoten des Ausgangsgraphen und ist ein minimaler Spannbaum dieses Ausgangsgraphen. |


















Effizienz und Laufzeit
Für eine effiziente Implementierung des Algorithmus von Prim muss man möglichst einfach eine Kante finden, die man dem entstehenden Baum hinzufügen kann. Man benötigt also eine Prioritätswarteschlange, in der alle Knoten gespeichert sind, die noch nicht zu gehören. Alle Knoten haben einen Wert, der dem der leichtesten Kante entspricht, durch die der Knoten mit verbunden werden kann. Existiert keine solche Kante, wird dem Knoten der Wert zugewiesen. Die Warteschlange liefert nun immer einen Knoten mit dem kleinsten Wert zurück.

Die Effizienz des Algorithmus hängt infolgedessen von der Implementierung der Warteschlange ab. Bei Verwendung eines Fibonacci-Heaps ergibt sich eine optimale Laufzeit von .

Korrektheitsbeweis
Sei ein zusammenhängender, kantengewichteter Graph. Bei jeder Iteration des Algorithmus muss eine Kante gefunden werden, die einen Knoten in einem Teilgraphen mit einem Knoten außerhalb des Teilgraphen verbindet. Weil zusammenhängend ist, gibt es immer einen Pfad zu jedem Knoten. Der resultierende Graph des Algorithmus ist ein Baum, da die dem Baum hinzugefügte Kante und der Knoten verbunden sind.
Sei ein minimaler Spannbaum des Graphen . Wenn gleich ist, dann ist ein minimaler Spannbaum.

Andernfalls sei die erste Kante, die während der Konstruktion des Baums hinzugefügt wird, die sich nicht im Baum befindet, und sei die Menge der Knoten, die durch die vor der Kante hinzugefügten Kanten verbunden waren. Dann befindet sich ein Knoten der Kante in der Menge der schon verbundenen Knoten und der andere nicht. Weil der Baum ein Spannbaum des Graphen ist, gibt es im Baum einen Pfad, der die beiden Endknoten verbindet. Wenn man den Pfad entlang fährt, muss man auf eine Kante stoßen, die einen Knoten der Menge mit einem Knoten verbindet, der nicht in der Menge liegt. Bei der Iteration, in der die Kante zu Baum hinzugefügt wurde, könnte nun auch die Kante hinzugefügt worden sein und sie würde anstelle der Kante hinzugefügt, wenn ihr Gewicht kleiner als das Gewicht von wäre, und weil die Kante nicht hinzugefügt wurde, schließen wir daraus, dass ihr Gewicht mindestens so groß ist wie das Gewicht von .


Der Baum sei der Graph, der aus durch Entfernen der Kante und Hinzufügen der Kante entsteht. Es ist einfach zu zeigen, dass der Baum zusammenhängend ist, die gleiche Anzahl von Kanten wie der Baum hat und das Gesamtgewicht seiner Kanten nicht größer als das von Baum ist, daher ist auch ein minimaler Spannbaum des Graphen und er enthält die Kante und alle Kanten, die während der Konstruktion der Menge hinzugefügt wurden. Wiederholt man die bisherigen Schritte, dann erhält man schließlich einen minimalen Spannbaum des Graphen , der mit dem Baum identisch ist. Dies zeigt, dass ein minimaler Spannbaum ist.

Vergleich mit dem Algorithmus von Kruskal
Wie auch der Algorithmus von Kruskal, der ebenfalls einen minimal spannenden Baum konstruiert, ist Prims Algorithmus ein Greedy-Algorithmus. Beide Algorithmen beginnen mit einem Graphen ohne Kanten und fügen in jedem Schritt eine Kante mit minimalem Gewicht hinzu. Sie unterscheiden sich vor allem darin, wie die Bildung eines Kreises vermieden wird.
Während der Algorithmus von Kruskal global nach möglichen Kanten mit dem kleinsten Gewicht sucht und bei der Aufnahme dieser Kanten in den Lösungsgraph die Kreisbildung aktiv vermeidet, betrachtet der Algorithmus von Prim nur Kanten, die von den Knoten der bisher konstruierten Teilknotenmenge zu Knoten der Komplementärmenge verlaufen. Da aus dieser Kantenmenge eine Kante ausgewählt wird, vermeidet der Algorithmus per Konstruktion das Auftreten von Kreisen.
Ein Vergleich der Laufzeit der beiden Algorithmen ist schwierig, da im Algorithmus von Prim die Knoten die zentrale Komplexitätsschranke bestimmen, während der Algorithmus von Kruskal auf Basis einer sortierten Kantenliste arbeitet und daher dessen Laufzeit von der Anzahl der Kanten dominiert wird.[2]
Parallele Implementierung
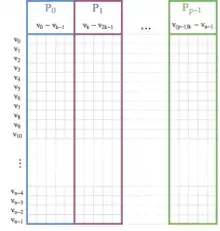
Der Algorithmus von Prim ist grundlegend sequentieller Natur, da sich die äußere Schleife aufgrund von Datenabhängigkeiten zwischen den Iterationen nicht parallelisieren lässt. Es ist allerdings möglich, die extract_min Operation zu parallelisieren. Hierfür kann zum Beispiel eine parallele Implementierung einer Prioritätswarteschlange verwendet werden. Auf einer Parallel Random Access Machine mit insgesamt Prozessoren lässt sich der Zugriff auf die Prioritätswarteschlange zu konstanter Zeit beschleunigen[3], sodass sich eine Gesamtlaufzeit in ergibt. Alternativ können die Knoten zwischen mehreren Prozessoren aufgeteilt werden, sodass jeder Prozessor die eingehenden Kanten zu seinem Teil der Knoten verwaltet.[4] Dies wird in folgendem Pseudocode dargestellt.
- Weise jedem Prozessor einen Teil der Knoten, sowie die dazugehörigen (eingehenden) Kanten zu. Bei Verwendung einer Adjazenzmatrix entspricht dies gerade einem Teil der Spalten.
- Erstelle auf jedem Prozessor einen Vektor , welcher die aktuellen Kosten für jeden Knoten in enthält. Initialisiere diesen Vektor mit
- Wiederhole folgende Schritte solange nicht alle Knoten im Spannbaum enthalten sind:
- Auf jedem Prozessor: bestimme den Knoten und dazugehörige Kante welcher den minimalen Wert in besitzt (lokale Lösung).
- Bestimme aus den lokalen Lösungen den Knoten dessen Verbindung zum aktuellen Spannbaum die geringsten Kosten hat. Dies ist mithilfe einer Minimum-Reduktion über alle Prozessoren möglich.
- Teile jedem Prozessor den gewählten Knoten mithilfe eines Broadcast mit.
- Füge den neuen Knoten sowie die dazugehörige Kante (es sei denn es handelt sich um den ersten Knoten) dem Spannbaum hinzu
- Auf jedem Prozessor: aktualisiere indem die Kanten des neu eingefügten Knotens zu dem eigenen Knotenset betrachtet werden.




Diese Variation von Prims Algorithmus lässt sich sowohl auf Verteilten Systemen,[4] auf Shared Memory Systemen[5], sowie auf Grafikprozessoren[6] implementieren. Die Laufzeit beträgt dabei , da in jeder der Iterationen des Algorithmus jeweils Einträge betrachtet werden müssen. Zusätzlich wird angenommen, dass sowohl die Minimum-Reduktion als auch der Broadcast in Zeit durchgeführt werden können.[4]



Als weitere Alternative für eine parallele Umsetzung von Prims Algorithmus wurde eine Variante präsentiert, in welcher der sequentielle Algorithmus parallel von verschiedenen Startknoten aus ausgeführt wird.[7] Im Allgemeinen eignen sich andere MST Algorithmen, wie beispielsweise der Algorithmus von Borůvka, jedoch besser für eine Parallelisierung.
Programmierung
Das folgende Beispiel in der Programmiersprache C# zeigt die Implementierung des Algorithmus von Prim. Bei der Ausführung des Programms wird die Methode Main verwendet, die die Kanten und die Abstände auf der Konsole ausgibt. Die Matrix für die Abstände wird in einem zweidimensionalen Array vom Datentyp Integer gespeichert.[8]
using System;
class Program
{
// Diese Methode gibt den Index des Knotens mit dem minimalen Abstand zum Teilgraphen zurück
static int GetMinimumIndex(int[] distances, bool[] includedNodes)
{
int minimumDistance = int.MaxValue;
int minimumIndex = -1;
for (int i = 0; i < distances.Length; i++)
{
if (!includedNodes[i] && distances[i] < minimumDistance)
{
minimumDistance = distances[i];
minimumIndex = i;
}
}
return minimumIndex;
}
// Diese Methode verwendet den Algorithmus von Prim und gibt den minimalen Spannbaum zurück
static void Prim(int[,] distanceMatrix, int numberOfNodes, out int[] parent, out int[] distances)
{
parent = new int[numberOfNodes];
distances = new int[numberOfNodes];
bool[] includedNodes = new bool[numberOfNodes];
for (int i = 0; i < numberOfNodes; i++)
{
distances[i] = int.MaxValue;
includedNodes[i] = false;
}
distances[0] = 0;
parent[0] = -1;
for (int i = 0; i < numberOfNodes - 1; i++)
{
int minimumIndex = GetMinimumIndex(distances, includedNodes);
includedNodes[minimumIndex] = true;
for (int j = 0; j < numberOfNodes; j++)
{
if (distanceMatrix[minimumIndex, j] != 0 && !includedNodes[j] && distanceMatrix[minimumIndex, j] < distances[j])
{
parent[j] = minimumIndex;
distances[j] = distanceMatrix[minimumIndex, j];
}
}
}
}
// Hauptmethode, die das Programm ausführt
public static void Main()
{
int[, ] distanceMatrix = new int[,] { {0, 2, 0, 6, 0},
{2, 0, 3, 8, 5},
{0, 3, 0, 0, 7},
{6, 8, 0, 0, 9},
{0, 5, 7, 9, 0} }; // Deklariert und initialisiert die Matrix mit den Abständen zwischen allen Punkten als zweidimensionales Array vom Typ int
int[] parent;
int[] distances;
int numberOfNodes = 5;
Prim(distanceMatrix, numberOfNodes, out parent, out distances);
Console.WriteLine("Kante\tAbstand"); // Ausgabe auf der Konsole
for (int i = 1; i < numberOfNodes; i++)
{
Console.WriteLine(parent[i] + " - " + i + "\t" + distanceMatrix[i, parent[i]]); // Ausgabe auf der Konsole
}
Console.ReadLine();
}
}
Literatur
- Robert C. Prim: Shortest connection networks and some generalisations. In: Bell System Technical Journal, 36, 1957, S. 1389–1401
- David Cheriton, Robert Tarjan: Finding minimum spanning trees. In: SIAM Journal on Computing, 5, Dezember 1976, S. 724–741
- Ellis Horowitz, Sartaj Sahni: Fundamentals of Computer Algorithms. In: Computer Science Press, 1978, S. 174–183
Weblinks
Einzelnachweise
- Brodal, Jesper Larsson Träff, Christos D. Zaroliagis: A Parallel Priority Queue with Constant Time Operations. In: Journal of Parallel and Distributed Computing. 49, Nr. 1, 1998, S. 4–21.
- vgl. dazu etwa Ellis Horowitz, Sartaj Sahni: Fundamentals of Computer Algorithms. (s. Literatur)
- Brodal, Jesper Larsson Träff, Christos D. Zaroliagis: A Parallel Priority Queue with Constant Time Operations. In: Journal of Parallel and Distributed Computing. 49, Nr. 1, 1998, S. 4–21.
- Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar: Introduction to Parallel Computing 2003, ISBN 978-0-201-64865-2, S. 444–446.
- Michael J. Quinn, Narsingh Deo: Parallel graph algorithms. In: ACM Computing Surveys (CSUR) 16.3. 1984, S. 319–348.
- Wei Wang, Yongzhong Huang, Shaozhong Guo: Design and Implementation of GPU-Based Prim’s Algorithm. In: International Journal of Modern Education and Computer Science 3.4. 2011.
- Rohit Setia: A new parallel algorithm for minimum spanning tree problem. In: Proc. International Conference on High Performance Computing (HiPC). 2009.
- GeeksforGeeks: Prim’s Minimum Spanning Tree (MST)