Varianz
Die Varianz, ist in der Statistik ein Maß für die Streubreite von numerischen Werten basierend auf der mittleren quadratischen Abweichung vom Mittelwert. Die Varianz ist eine positive reelle Zahl. Eine Varianz von Null bedeutet, dass alle betrachteten Werte identisch sind.
Die Wurzel aus der Varianz ist die Standardabweichung. Varianz und Standardabweichung gehören zu den Streuungsmaßen.
Die Varianz ist in weitergehenden Berechnungen oft praktischer als die Standardabweichung:
- Beispiel: Im Falle von mehreren unabhängigen Zufalls-Einflüssen kann man die entsprechenden Varianzbeiträge addieren
Aber die Standardabweichung ist oft anschaulicher als die Varianz, da sie dieselbe Größenordnung hat wie die ursprünglichen Einzelwerte
- Beispiel: Eine Standardabweichung von 10 cm ist für einen Leser sofort interpretierbar. Der entsprechende Varianzwert von 100 cm² ist nicht so anschaulich.
Der Begriff "Varianz" leitet sich ab von: lateinisch variantia = „Verschiedenheit“ bzw. variare = „(ver)ändern, verschieden sein“.
Der folgende Artikel wendet sich an den Anwender. Für den mathematischen Hintergrund siehe:
Berechnung der Varianz
| Formelzeichen | |
|---|---|
| Menge der gegebenen Werte für die Varianzberechnung | |
| Zufallsvariable | |
| Anzahl der gegebenen Werte | |
| Zähler | |
| k-ter Wert in | |
| Varianz | |
| Standardabweichung | |
| Mittelwert | |
| Die Tilde kennzeichnet einen Schätzwert | |
| Wahrscheinlichkeit | |
| Varianz der Varianz von Stichproben | |











Die konkrete Wahl des Berechnungsverfahrens hängt von folgenden Punkten ab:
- In welcher Form sind die numerischen Werte gegeben? z.B. als endliche Anzahl von Werten? Als statistische Verteilungsfunktion?
- Wie ist der Mittelwert definiert? z.B. als Mittelwert aller Datenwerte? Ist der Mittelwert vorab bekannt?
- Beinhaltet die Liste der Werte wirklich alle Werte? Oder ist das nur eine Stichprobe?
- Soll die Berechnung schrittweise für jeden neuen Datenwert erfolgen? Soll die Berechnung in einem Echtzeitsystem erfolgen?
Diese Unterscheidungen spielen eine wichtige Rolle in folgender Übersicht über die Berechnungsverfahren.
Varianzberechnung basierend auf einer Stichprobe
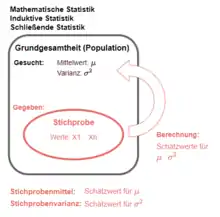
Stichproben sind ein Ausschnitt einer größeren Datenmenge. Die größere Datenmenge wird auch Grundgesamtheit, Gesamtheit oder Population genannt. Stichproben werden so gewählt, dass sie eine Aussage über die Gesamtheit aller Daten dieser größeren Datenmenge ermöglichen. Man sagt auch: die Stichprobendaten werden empirisch erhoben. Das führt zu den ebenfalls häufig verwendeten Begriffen "Empirische Varianz"[1] oder "Stichprobenvarianz". Leider ist die präzise Unterscheidung dieser Begriffe in der Literatur nicht einheitlich[2]. Daher verwenden wir zur Unterscheidung der typischen Berechnungsformeln nicht diese Begriffe, sondern den Bedeutungsunterschied der Formeln.
Die Grundgesamtheit wird charakterisiert durch den "Wahren Mittelwert" und die "Wahre Varianz", die oft auch "Theoretische Varianz"[3][4] genannt wird.
Varianzberechnung basierend auf einer Stichprobe bei unbekanntem Mittelwert der Gesamtheit
Zuerst muss ein Wert für den wahren Mittelwert der Gesamtheit aller Daten bestimmt werden. Er kann stets nur ungefähr aus dem Mittelwert einer Stichprobe abgeleitet (geschätzt) werden. Aus der Stichprobe (x1, ..., xn) wird der Mittelwert , den wir als empirisches Mittel dieser Stichprobe bezeichnen, mit

| (1a) |

berechnet.[5]
Dieser Wert konvergiert für große Anzahlen von Probenwerten (oder gemittelt über eine große Anzahl von Stichproben) gegen den Mittelwert der Gesamtheit. Damit kann er als "Erwartungstreue Schätzung" bezeichnet werden.
Im nächsten Schritt lässt sich aus der Stichprobe (x1, ..., xn) und dem empirischen Mittelwert die sogenannte Empirische Varianz[1] der Stichprobe berechnen:

| (1b) |

Die empirische Varianz ist eine erwartungstreue Schätzung der Varianz der Gesamtheit.[1][6] D.h. Dieser Wert konvergiert für große Anzahlen von Probenwerten (oder gemittelt über eine große Anzahl von Stichproben) gegen die Varianz der Gesamtheit.
Bei der Begründung für den Nenner in der Formel (1b) wird oft der Begriff "Anzahl der Freiheitsgrade" verwendet: Ein Freiheitsgrad wird bereits für die Berechnung des Mittelwertes "verbraucht". Daher verbleiben nur Freiheitsgrade für die Varianzberechnung.

Die Verwendung von statt im Nenner wird oft auch "Bessel Korrektur" genannt.
Varianzberechnung basierend auf einer Stichprobe bei bekanntem Mittelwert der Gesamtheit
In diesem Fall ist der "wahre Mittelwert" der Gesamtheit bereits vorab bekannt. Es entfällt die Aufgabe den Mittelwert zu schätzen. Es sind also und gegeben. Damit ist obige Korrektur nicht erforderlich und es vereinfacht sich die Berechnung der Varianz zu:[1]
| (2) |

Auch diese Formel liefert einen erwartungstreuen Schätzwert.
Wenn man mit dem Begriff "Anzahl der Freiheitsgrade" argumentiert: Da der Mittelwert in diesem Fall eine vorgegebene Größe ist, geht kein Freiheitsgrad durch eine vorausgegangene Mittelwertbildung verloren. Daher muss die Summe in Formel (2) durch geteilt werden.
Varianzberechnung basierend auf einer endlichen "Gesamtheit" von Werten
Das entspricht einem Grenzfall von Formel (1). Die gegebenen Datenwerte entsprechen jetzt der vollständigen Gesamtheit. Es wird also keine "Schätzung" des wahren Mittelwertes benötigt da man ja wirklich alle Daten kennt und den Mittelwert ausrechnen kann. Ebenso wird die Varianz der Gesamtheit aller Werte nicht "geschätzt" sondern einfach berechnet.
| (3a) |

| (3b) |

Tatsächlich ist die Gesamtheit aller Werte häufig nicht bekannt.
Beispiel: In einer Produktionsmaschine wird von jedem produzierten Teil die Dicke gemessen. Selbst in diesem Fall kann man sich fragen, ob die Verwendung von (3) angemessen wäre: Oft möchte man ja bereits nach relativ kurzer Zeit eine "zu erwartende" Qualität bestimmen, d.h. eine Qualität, die man erwartet, wenn die Maschine genau so weiter läuft. In der Gesamtheit aller Daten wären also auch die Daten enthalten, die erst in der Zukunft gemessen werden. Die Produktion der vergangenen Zeitspanne kann daher auch als Stichprobe aufgefasst werden: Die Stichprobe umfasst also die ersten n Werte der neuen Charge und beinhaltet nur relativ wenige Daten. Bei dieser Sichtweise wäre Formel (1) angemessener.
Formel (3) könnte aber unter Umständen Verwendung finden, um die Varianz innerhalb einer kompletten Charge nachträglich zu dokumentieren. Allerdings kann sich man sogar in diesem Fall fragen, ob die eigentliche Grundgesamtheit nicht größer ist und Formel (1) verwendet werden sollte: Geht es bei der Dokumentation nicht eigentlich um die erreichbare Qualität? Also um die Qualität die man erwarten würde, wenn man die Produktion in gleicher Weise wiederholt? Die Varianzberechnung mit (3) würde bei dieser Sichtweise einen zu geringen Varianzwert liefern. Als Beitrag zur Diskussion ob sich für (3) sinnvolle Beispiele finden lassen, sei auch der beigefügte Weblink "FernUni Hagen 2020"[2] empfohlen.
Varianzberechnung basierend auf einer kontinuierlichen Verteilungsfunktion
Gegeben ist in diesem Fall eine Zufallsvariable mit einer Verteilungsfunktion, beziehungsweise einer Wahrscheinlichkeitsdichtefunktion (kurz: Dichte) , die eine Aussage trifft, wie wahrscheinlich das Auftreten von welchem Wert ist.

Dann ergeben sich Mittelwert und Varianz der Grundgesamtheit aus folgenden Formeln:[7]
| (4a) |

| (4b) |

Varianzberechnung basierend auf einer diskreten Verteilungsfunktion
Im Unterschied zu Formel (4) kann in diesem Fall nur diskrete Werte annehmen. Die Verteilungsfunktion ist in diesem Fall gegeben als Wahrscheinlichkeiten , mit denen der zugehörige Wert auftritt.

Das führt zu folgenden Formeln für Mittelwert und Varianz der Grundgesamtheit:[7]
| (5a) |

| (5b) |

Varianzberechnung basierend auf Daten aus einer Zeitreihe
In diesem Fall sind Werte als Zeitreihe gegeben. Beispielsweise wird sekündlich ein Wert gemessen. Zu jedem Zeitpunkt der Zeitreihe soll die Varianz aus den letzten Werten von bestimmt werden. Die Schätzung der Varianz wird damit mit der Zeit immer genauer. Die Rechnung soll in Echtzeit erfolgen, also jeweils unmittelbar nach dem Eintreffen von jedem Wert . In Echtzeitsystemen wird stark auf die erforderliche Rechenzeit in jedem Zeitschritt geachtet, daher werden bevorzugt rekursive Formeln verwendet. Mit Formeln (1) bis (3) würde die erforderliche Rechenzeit mit der Zeit steigen, da ja auch die Summen immer mehr Werte umfassen. Das wird vermieden mit folgenden rekursiven Formeln, die auf den Schätz-Ergebnissen für und zum vergangenen Zeitpunkt aufbauen:[8]



| (6a) |

| (6b) |

Diese Formeln benötigen natürlich Startwerte, die geeignet gewählt werden sollten. Bei ungünstiger Wahl nähern sich die Schätzwerte nur langsam den wahren Werten an. Wenn ab dem Zeitpunkt neue Messwerte eintreffen, dann sind günstige Vorbelegungen für den Zeitpunkt :


- kann mit oder dem ersten erhaltenen Messwert oder einem vorab erwarteten Mittelwert vor belegt werden
- kann mit oder einem vorab erwarteten Varianzwert vor belegt werden



Genauigkeit der Schätzung der Varianz von Stichproben
Aus den Werten in einer Stichprobe lässt sich mit den Formeln (1) und (2) näherungsweise die Varianz der Grundgesamtheit berechnen. Was bedeutet "näherungsweise" in diesem Fall? Wie genau ist diese Schätzung? Das hängt von der Streuung der Datenwerte und von der Anzahl der Datenwerte ab. Die Varianz basierend auf einer Stichprobe ist eine Zufallsvariable: D.h. wenn man viele Stichproben nimmt, dann wird jede Stichprobe zu einer anderen Varianz-Schätzung führen. Gesucht ist also die Streuung dieser Zufallsvariable – die "Varianz der Varianz", die wir im Folgenden mit abkürzen.
Die Berechnung der "Varianz der Varianz" baut auf den Formeln (1) und (2) auf.
Alternativ kann die Genauigkeit der Schätzung der Varianz auch durch die Berechnung des Konfidenzintervalles mit Hilfe der Chi-Quadrat-Verteilung beurteilt werden.
Varianz der Varianz – bei unbekanntem wahren Mittelwert der Gesamtheit
In diesem Fall ist der Ausgangspunkt die Formel (1). Die "Varianz der Varianz" wird dann berechnet durch:[9]
| (7) |

Varianz der Varianz – bei bekanntem wahren Mittelwert der Gesamtheit
In diesem Fall ist der Ausgangspunkt die Formel (2). Die "Varianz der Varianz" wird dann berechnet durch:[9]
| (8) |

Wikipedia Links
siehe auch die thematisch eng verwandten Seiten in Wikipedia:
- Varianz (Stochastik)
- Gleichung von Bienaymé
- Schätzung der Varianz der Grundgesamtheit
- Schätzung der Varianz einer Schätzfunktion
- Standardfehler
- Variationskoeffizient
- Mittlere quadratische Abweichung
- Varianzanalyse
- Kovarianz
- Liste aller Wikipedia-Artikel, deren Titel Varianz enthält
sowie die Begriffserklärung in Wiktionary:
Weblinks
- FernUni Hagen 2020 – Empirische vs Stichprobenvarianz (YouTube)
- HU-Berlin 2018 – Verteilung der Stichprobenvarianz (MediaWiki)
Literatur
- Bronstein-Semendjajew 2020 – I. N. Bronstein, K. A. Semendjajew, G. Musiol, H. Mühlig: Taschenbuch der Mathematik. 11. Auflage. Verlag Europa-Lehrmittel Nourney, Vollmer GmbH & Co. KG, Haan-Gruiten 2020, ISBN 978-3-8085-5792-1.
- Hartung 2005 – Dr. Joachim Hartung, Dr. Bärbel Elpelt, Dr. Karl-Heinz Klösener: Statistik. Lehr- und Handbuch der angewandten Statistik. 14. Auflage. R. Oldenbourg Verlag, München / Wien 2005, ISBN 3-486-57890-1.
- Young 2011 – Peter C. Young: Recursive Estimation and Time-Series-Analysis. 2. Auflage. Springer-Verlag, Berlin / Heidelberg 2011, ISBN 978-3-642-21980-1.
Einzelnachweise
- Hartung 2020: Statistik, Kap. IV: Spezielle Verteilungen und statistische Schlüsse, S. 153f.
- FernUni Hagen 2020: Empirische vs Stichprobenvarianz. In: YouTube. FernUni Hagen: https://www.statstutor.de/, 19. April 2020, abgerufen am 1. Februar 2022.
- Pschyrembel Online: Varianz, abgerufen am 1. Februar 2022.
- Gabler-Banklexikon: Varianz, abgerufen am 1. Februar 2022.
- Bronstein-Semendjajew 2020: Taschenbuch der Mathematik, 16.3.2.2 Statistische Parameter - Mittelwert, S. 848.
- Bronstein-Semendjajew 2020: Taschenbuch der Mathematik, 16.3.2.2 Statistische Parameter - Streuung, S. 848.
- Bronstein-Semendjajew 2020: Taschenbuch der Mathematik, 16.2.2.3 Erwartungswert und Streuung, S. 827, Formel 16.52.
- Young 2011 - Chapter 2: Recursive Estimation, Seite 19
- HU-Berlin 2018: Verteilung der Stichprobenvarianz, Kapitel 1.2, abgerufen am 1. Februar 2022.