N-Gramm
Ein N-Gramm, manchmal auch Q-Gramm genannt,[1] ist das Ergebnis der Zerlegung eines Textes in Fragmente. Der Text wird dabei zerlegt, und jeweils aufeinanderfolgende Fragmente werden als N-Gramm zusammengefasst. Die Fragmente können Buchstaben, Phoneme, Wörter und Ähnliches sein. N-Gramme finden Anwendung in der Kryptologie und Korpuslinguistik, speziell auch in der Computerlinguistik, Quantitativen Linguistik und Computerforensik. Einzelne Wörter, ganze Sätze oder komplette Texte werden hierbei zur Analyse oder statistischen Auswertung in N-Gramme zerlegt[2] und in Datensätzen zusammengefasst. Drei Datensätze von N-Grammen aus Google Books mit den Stichtagen Juli 2009, Juli 2012 und Februar 2020 wurden mit einer Weboberfläche und grafischer Auswertung in Form von Diagrammen versehen und unter dem Namen Google Books Ngram Viewer ins Netz gestellt.

Arten von N-Grammen
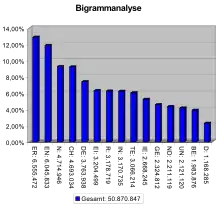
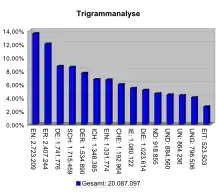
Wichtige N-Gramme sind das Monogramm, das Bigramm (manchmal auch als Digramm bezeichnet) und das Trigramm. Das Monogramm besteht aus einem Fragment, beispielsweise nur aus einem einzelnen Buchstaben, das Bigramm aus zwei und das Trigramm aus drei Fragmenten. Allgemein kann man auch von Multigrammen sprechen, wenn es sich um eine Gruppe von „vielen“ Fragmenten handelt.
Die Präfixe wissenschaftlicher Bezeichnungen werden häufig unter Zuhilfenahme griechischer Zahlwörter gebildet. Beispiele sind mono für „allein“ oder „einzig“, tri für „drei“, tetra für „vier“, penta für „fünf“, hexa für „sechs“, hepta für „sieben“, okto für „acht“ und so weiter. Bi und multi sind Vorsilben lateinischen Ursprungs und stehen für „zwei“ beziehungsweise „viele“.
Die folgende Tabelle gibt sortiert nach der Anzahl der Zeichen zusammen mit einem Beispiel, bei denen als Zeichen Buchstaben des Lateinischen Alphabets genommen wurden, eine Übersicht über die Bezeichnung der N-Gramme:
| N-Gramm-Name | N | Beispiel |
|---|---|---|
| Monogramm | 1 | A |
| Bigramm | 2 | AB |
| Trigramm | 3 | UNO |
| Tetragramm | 4 | HAUS |
| Pentagramm | 5 | HEUTE |
| Hexagramm | 6 | SCHIRM |
| Heptagramm | 7 | TELEFON |
| Oktogramm | 8 | COMPUTER |
| … | … | … |
| Multigramm | 17 | BEOBACHTUNGSLISTE |
Formale Definition
Sei ein endliches Alphabet und sei eine positive ganze Zahl. Dann ist ein -Gramm ein Wort der Länge über dem Alphabet , das heißt .




Analyse
Die N-Gramm-Analyse wird verwendet, um die Frage zu beantworten, wie wahrscheinlich auf eine bestimmte Buchstaben- oder Wortfolge ein bestimmter Buchstabe oder ein bestimmtes Wort folgen wird. Die bedingten Wahrscheinlichkeiten für den nächsten Buchstaben der Folge „for ex…“ betragen für eine bestimmte Stichprobe aus dem Englischen in absteigender Rangreihenfolge etwa: a = 0,4, b = 0,00001, c = 0,… mit einer Gesamtsumme von 1. Auf der Grundlage der N-Gramm-Häufigkeiten erscheint also eine Fortsetzung des Fragmentes mit „a“ → „for exa(mple)“ deutlich wahrscheinlicher als die Alternativen.
Die verwendete Sprache ist für die Analyse nicht von Bedeutung, wohl aber ihre Statistik: Die N-Gramm-Analyse funktioniert in jeder Sprache und jedem Alphabet. Daher hat sich die Analyse in den Feldern der Sprachtechnologie bewährt: Zahlreiche Ansätze der maschinellen Übersetzung bauen auf den Daten auf, die mit dieser Methode gewonnen wurden.
Besondere Bedeutung kommt der N-Gramm-Analyse dann zu, wenn große Datenmengen, beispielsweise E-Mails, auf ein bestimmtes Themengebiet hin untersucht werden sollen. Durch die Ähnlichkeit mit einem Referenzdokument, etwa einem technischen Bericht über Atombomben oder Polonium, lassen sich Cluster bilden: Je näher die Worthäufigkeiten in einer Mail an denen im Referenzdokument liegen, umso wahrscheinlicher ist, dass sich der Inhalt um dessen Thema dreht und unter bestimmten Umständen – in diesem Beispiel – eventuell Terrorismus-relevant sein könnte, selbst wenn Schlüsselwörter, die eindeutig auf Terrorismus hinweisen, selbst nicht auftauchen.
Kommerziell verfügbare Programme, die diese fehlertolerante und äußerst schnelle Methode ausnutzen, sind Rechtschreibprüfungen und Forensik-Werkzeuge. In der Programmiersprache Java verfügt die Bibliothek Apache OpenNLP über Werkzeuge zur N-Gramm-Analyse,[3] in Python steht NLTK zur Verfügung.[4]
Web-Indexierung
Google veröffentlichte im Jahr 2006 sechs DVDs[5] mit englischsprachigen N-Grammen von einem bis fünf Wörtern, die bei der Indexierung des Webs entstanden. Nachfolgend einige Beispiele aus dem Google-Korpus für 3-Gramme und 4-Gramme auf Wortebene (d. h. n entspricht der Anzahl der Wörter) und die Häufigkeiten, mit denen diese auftreten:[6]
3-Gramme:
- ceramics collectables collectibles (55)
- ceramics collectables fine (130)
- ceramics collected by (52)
- ceramics collectible pottery (50)
- ceramics collectibles cooking (45)
4-Gramme:
- serve as the incoming (92)
- serve as the incubator (99)
- serve as the independent (794)
- serve as the index (223)
- serve as the indication (72)
- serve as the indicator (120)
- Beispiel
- Eine zu durchsuchende Zeichenkette lautet
- = {„Welcome to come“}.
- (sog. Bigramm)
- Die Häufigkeit des Vorkommens der einzelnen Buchstaben-Bigramme wird bestimmt.
- Somit lautet der „Frequenzvektor“ für die Zeichenkette :
- _W:1
- We:1
- el:1
- lc:1
- co:2
- om:2
- me:2
- e_:1
- _t:1
- to:1
- o_:1
- _c:1



Das heißt . Der Unterstrich steht für die Wortgrenze. Die Länge des Vektors ist dabei durch nach oben beschränkt, wobei die Länge von und der Binomialkoeffizient ist.




Google Books Korpus
Ein Datensatz aus Google Books mit Stichtag Juli 2009 wurde mit einer Weboberfläche und grafischer Auswertung in Form von Diagrammen versehen und unter dem Namen Google Books Ngram Viewer ins Netz gestellt.[7] Standardmäßig zeigt sie die normalisierte Häufigkeit relativ zur Anzahl der bis zu diesem Jahr vorhandenen Bücher für bis zu 5-Gramme. Mit Operatoren lassen sich mehrere Begriffe zu einem Graphen zusammenfassen (+), ein Multiplikator für sehr unterschiedlich vorkommende Begriffe einbauen (*), das Verhältnis zwischen zwei Begriffen darstellen (-, /) oder verschiedene Korpora vergleichen (:). Die Grafiken können frei verwendet werden („freely used for any purpose“[8]), wobei die Angabe der Quelle und ein Link erwünscht sind. Die Grunddaten sind für eigene Auswertungen in einzelne Pakete gesplittet downloadbar und stehen unter Creative Commons Attribution Lizenz. Neben einer Auswertungsmöglichkeit für Englisch allgemein gibt es spezielle Abfragen für American English und British English (differenziert anhand der Veröffentlichungsorte), sowie für English Fiction (anhand der Einstufung der Bibliotheken) und English One Million. Bei letzterem wurden proportional zur Anzahl veröffentlichter und gescannter Bücher von 1500 bis 2008 bis zu 6000 Bücher pro Jahr zufällig ausgewählt. Zusätzlich gibt es auch Korpora für Deutsch, vereinfachtes Chinesisch, Französisch, Hebräisch, Russisch und Spanisch. Zur Tokenisierung wurden einfach die Leerzeichen herangezogen. Die N-Gramm-Bildung geschah über Satzgrenzen hinweg, aber nicht über Seitengrenzen. Es wurden nur Wörter aufgenommen, die mindestens 40-mal im Korpus vorkommen.
Ein neues Korpus mit Stichtag Juli 2012 wurde Ende des Jahres zugänglich gemacht. Als neue Sprache kam Italienisch hinzu, English One Million wurde nicht wieder gebildet. Grundlegend basiert das Korpus auf einer größeren Anzahl von Büchern, verbesserter OCR-Technik und verbesserten Metadaten. Die Tokenisierung geschah hier nach einem Set handgeschriebener Regeln, außer für Chinesisch, wo eine statistische Methode zur Segmentierung genutzt wurde. Die N-Gramm-Bildung endet nun bei Satzgrenzen, geht aber dabei nun über Seitengrenzen hinweg. Mit den nun beachteten Satzgrenzen sind neue Funktionen für das 2012er-Korpus eingeführt worden, die bei 1-, 2- und 3-Grammen auch mit hoher Wahrscheinlichkeit die Stellung im Satz auswerten lassen und so beispielsweise auch im Englischen homographe (gleich geschriebene) Substantive und Verben unterscheiden lassen, wobei dies in moderner Sprache besser funktioniert.[8][9]
Mit Stichtag Februar 2020 wurde nunmehr ein drittes Korpus mit dem Nennjahr 2019 ins Netz gestellt, dessen Features denen der Version 2012 entsprechen.
Dice-Koeffizient
Der Dice-Koeffizient ist eins von mehreren Ähnlichkeitsmaßen für Terme. Er ermittelt den Anteil der N-Gramme, die in zwei Termen und vorhanden sind. Die Formel ist



wobei die Menge der N-Gramme des Terms ist. d liegt dabei immer zwischen 0 und 1.


Beispiel
- Term a = "wirk"
- Term b = "work"
Bei Verwendung von Trigrammen sieht die Zerlegung folgendermaßen aus:
- T(a) = {§§w, §wi, wir, irk, rk§, k§§}
- T(b) = {§§w, §wo, wor, ork, rk§, k§§}
- T(a) T(b) = {§§w, k§§, rk§}

Das heißt d(wirk, work) = . Der Dice-Koeffizient beträgt also 0,5 (50 %).

Anwendungsgebiete
Aufgrund der weitgehenden Sprachneutralität kann dieser Algorithmus auf folgenden Gebieten angewandt werden:
- Rechtschreibkorrektur (für Korrekturvorschläge)
- Suche nach ähnlichen Schlüsselwörtern (Überwachung, Spracherkennung)
- Grundwortreduktion (Stemming) im Information Retrieval
Statistik
Als N-Gramm-Statistik bezeichnet man eine Statistik über die Häufigkeit von N-Grammen, manchmal auch von Wortkombinationen aus N Wörtern. Spezialfälle sind die Bigrammstatistik und die Trigrammstatistik. Anwendungen finden N-Gramm-Statistiken in der Kryptoanalyse und in der Linguistik, dort vor allem bei Spracherkennungssystemen. Dabei prüft das System während der Erkennung die verschiedenen Hypothesen zusammen mit dem Kontext und kann dadurch Homophone (gleich klingende Wörter) unterscheiden. In der Quantitativen Linguistik interessiert unter anderem die Rangordnung der N-Gramme nach Häufigkeit sowie die Frage, welchen Gesetzen sie folgt. Eine Statistik von Digrammen (und Trigrammen) im Deutschen, Englischen und Spanischen findet man bei Meier[10] und Beutelspacher.[11]
Für aussagefähige Statistiken sollten ausreichend große Textbasen von mehreren Millionen Buchstaben oder Wörtern benutzt werden. Als Beispiel ergibt die statistische Auswertung einer deutschen Textbasis von etwa acht Millionen Buchstaben „ICH“ als das häufigste Trigramm mit einer relativen Häufigkeit von 1,15 Prozent. Die folgende Tabelle gibt eine Übersicht über die zehn (in dieser Textbasis) als häufigste ermittelten Trigramme:
| Trigramm | Häufigkeit |
|---|---|
| ICH | 1,15 % |
| EIN | 1,08 % |
| UND | 1,05 % |
| DER | 0,97 % |
| NDE | 0,83 % |
| SCH | 0,65 % |
| DIE | 0,64 % |
| DEN | 0,62 % |
| END | 0,60 % |
| CHT | 0,60 % |
Literatur
- Wolfgang Schönpflug: N-Gramm-Häufigkeiten in der deutschen Sprache. I. Monogramme und Digramme. In: Zeitschrift für experimentelle und angewandte Psychologie XVI, 1969, S. 157–183.
- Pia Jaeger: Soziale Gerechtigkeit im Wandel. Ein idealistisches Konstrukt und/oder ein Mittel zur politischen Akzeptanzsicherung. Baden-Baden, Nomos 2017, ISBN 978-3-8452-8440-8, S. 25–56: Darstellung und Anwendung auf den Ausdruck "Soziale Gerechtigkeit" – ein Anwendungsbeispiel
Weblinks
- Tool zum Zählen von Mono-, Di- und Trigrammen mit Häufigkeitstabellen von N-Grammen aus 20 Sprachen
- Google Ngram Viewer am Beispiel »Wikipedia, Lexikon, Nachschlagewerk«
- Google Ngram Viewer im Wiki Literatur Rechnen – Neue Wege der Textanalyse (LitRe-Wiki) der Universität Göttingen
Einzelnachweise
- Stefan-Patrick Selbach: Hybride bitparallele Volltextsuche. (PDF, 3,5 MB) In: Dissertation. Universität Würzburg, Fakultät für Mathematik und Informatik, 2011, S. 20, abgerufen am 8. Oktober 2021.
- Dan Jurafsky Stanford University and James H. Martin University of Colorado Boulder: Speech and Language Processing - An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. In: 3. Language Modeling with N-Grams. Abgerufen am 3. April 2020 (englisch).
- How to use NGram features for Document Classification in OpenNLP. In: TutorialKart. Abgerufen am 3. April 2020 (amerikanisches Englisch).
- Generate the N-grams for the given sentence. In: Python Programming. 3. Mai 2019, abgerufen am 4. April 2020 (englisch).
- Web 1T 5-gram Version 1
- Alex Franz and Thorsten Brants: All Our N-gram are Belong to You. In: Google Research Blog. 2006. Abgerufen am 16. Dezember 2011.
- Google Books Ngram Viewer
- Google Books Ngram Viewer - Info
- Google Books Ngram Viewer - Datasets
- Helmut Meier: Deutsche Sprachstatistik. Zweite erweiterte und verbesserte Auflage. Olms, Hildesheim 1967, S. 336–339
- Albrecht Beutelspacher: Kryptologie. 7. Aufl., Vieweg, Wiesbaden 2005, ISBN 3-8348-0014-7, Seite 230–236; dabei auch: Trigramme.