Korpuslinguistik
Die Korpuslinguistik ist ein Bereich der Sprachwissenschaft. Darin werden neue Erkenntnisse über Sprache generell oder über bestimmte einzelne Sprachen erlangt oder bestehende Hypothesen überprüft, wobei als Grundlage quantitative oder qualitative Daten dienen, die aus der Analyse von speziellen Textkorpora oder (seltener) Korpora gesprochener Sprache gewonnen werden. Große Verbreitung fand die Korpuslinguistik im deutschsprachigen Raum ab der zweiten Hälfte der 1990er Jahre. Sie verhält sich, wissenschaftstheoretisch betrachtet, komplementär zum Generativismus. Es ist nach wie vor umstritten, ob es sich bei der Korpuslinguistik um eine Methode oder um einen eigenen neuen Zweig der Sprachwissenschaft handelt.
Datenmaterial und Forschungsgegenstand
Gegenstand der Korpuslinguistik ist die Sprache in ihren verschiedenen Erscheinungsformen. Die Korpuslinguistik ist dabei durch das Verwenden von authentischen Sprachdaten charakterisiert, die in großen Korpora dokumentiert sind. Bei solchen Textkorpora handelt es sich um Sammlungen von sprachlichen Äußerungen, die nach bestimmten Kriterien und mit einem bestimmten Forschungsziel zusammengestellt werden. Die Erkenntnisse der Korpuslinguistik basieren somit auf natürlichen Äußerungen einer Sprache, also auf Sprache, wie sie tatsächlich verwendet wird. Diese Äußerungen können entweder schriftlich entstanden sein oder es kann sich um spontane oder elizitierte gesprochene Sprache handeln. Die meisten Korpora liegen heute in digitaler Form vor und sind mittels bestimmter Software für die linguistische Recherche nutzbar.
Ziel der Korpuslinguistik ist es, anhand dieser Daten entweder bestehende linguistische Hypothesen zu überprüfen (bestätigen oder widerlegen) oder durch explorative Datenanalyse neue Hypothesen und Theorien über den Gegenstand zu gewinnen. Man spricht im ersten Fall von „korpusgestützter“ linguistischer Analyse und im zweiten Fall von „korpusbasierter“ linguistischer Analyse.
Korpuslinguistische Fragestellungen betreffen sowohl das sprachliche System selbst („Langue“ nach Ferdinand de Saussure bzw. „Kompetenz“ nach Noam Chomsky) als auch den Gebrauch von Sprache („Parole“ nach de Saussure bzw. „Performanz“ nach Chomsky). Die Korpuslinguistik ist also dahingehend im Begriff, die in der Linguistik dominierende dichotome Sprachbetrachtung aufzuheben.
Eine typische Fragestellung das Sprachsystem betreffend ist beispielsweise:
- Kann das Vorfeld eines deutschen Satzes mehrfach besetzt sein? Wenn ja, mit welchen Satzgliedern? Gibt es Regeln, die die Möglichkeiten der mehrfachen Vorfeldbesetzung beschreiben können?
Typische Fragestellungen den Sprachgebrauch betreffend sind etwa:
- Kommt es in Texten von E-Mails öfter zu Schreibfehlern als in traditionellen Briefen? Welche Typen von Fehlern sind charakteristisch für E-Mails?
- Welche Fehler machen Lernende des Deutschen (verschiedener Ausgangssprache) auf einem bestimmten Niveau besonders häufig, werden bestimmte Wörter oder grammatische Konstruktionen von diesen Lernenden vermieden?
Bei zahlreichen Forschungsfragen, die die Korpuslinguistik versucht zu beantworten, ist jedoch nicht eindeutig zu entscheiden, welchem der beiden Domänen Langue und Parole ein Phänomen zuzuordnen ist, wie beispielsweise bei den Fragen:
- Mit welchen Adjektiven tritt das Nomen „Haar“ typischerweise gemeinsam auf?
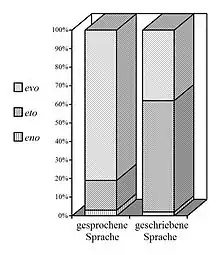
- Werden Partikel in der gesprochenen Sprache häufiger, weniger häufig oder anders verwendet als in geschriebener Sprache?
Denn einerseits kann die Verteilung der Adjektive mit „Haar“ und der Modalpartikeln als Phänomen einer bestimmten Sprache oder – nach Vergleich mit anderen Sprachen – als Merkmal von Sprache generell gelten, aber andererseits auch als Ergebnis eines spezifischen Sprachgebrauchs angesehen werden.
(Einen Einblick in die Facetten korpuslinguistischer Forschung bieten z. B. die Arbeiten von Lemnitzer/Zinsmeister (2010) für das Deutsche und McEnery/Xiao/Tono (2006) für das Englische.)
Methodische Probleme
Ein bedeutendes methodisches Problem der Korpuslinguistik ist das Verhältnis der Datenbasis, also des Korpus, zum untersuchten Gegenstand. Die Datenbasis könnte theoretisch den Gegenstand komplett abdecken, wenn es sich um eine heute noch verwendete Sprache handelt. Doch man kann einen Korpus nicht als eine im Sinne der schließenden Statistik valide Stichprobe betrachten, da der Gegenstand, auf den sich die Stichprobe bezieht, in der Praxis als Ganzes – also eine bestimmte Sprache oder ein bestimmter Sprachgebrauch – nicht erfassbar ist.[2] Man behilft sich heute damit, ein Korpus nicht mehr (wie ursprünglich gefordert) als „repräsentativ“ im statistischen Sinne für den untersuchten Gegenstand zu bezeichnen und Erkenntnisse, die auf Grund von Korpora gewonnen werden, lediglich als vorläufig plausibel zu betrachten. Die Zusammenstellung von großen Korpora soll daher „ausgewogen“ sein, also in einem bestimmten Verhältnis aus unterschiedlichen Textsorten bestehen.
Die Grundannahme der Korpuslinguistik, dass Erkenntnisse über Sprache anhand von realen sprachlichen Äußerungen gewonnen oder überprüft werden können, bringt zwei weitere methodische Probleme oder Einwände mit sich:
- Irreführende positive Evidenz: In spontanen gesprochenen und sogar in überlegt formulierten schriftsprachlichen Äußerungen können bis zu einem gewissen Grad Abweichungen von der sprachlichen Norm auftreten. Bei der Untersuchung eines Korpus kann es im Einzelfall schwierig sein zu entscheiden, ob eine (meist kleine) Menge von Belegen eines bestimmten sprachlichen Phänomens Ausdruck eines tatsächlich existierenden systematischen Sprachgebrauchs ist und somit eine linguistische These stützt oder ob man diese Belege als normabweichendend bzw. fehlerhaften Sprachgebrauch ansehen muss.
- Negative Evidenz: Viele Aussagen zu sprachlichen Phänomenen lassen sich dann selbst in sehr großen Korpora nicht belegen, wenn der Gebrauch bestimmter sprachlicher Konstruktionen sehr selten ist. Aus dem Nichtvorhandensein einer solchen gesuchten Konstruktion im Korpus kann aber nicht zwingend geschlossen werden, dass es nicht existiere oder ungrammatisch wäre.
Im ersten Fall kann man Ergebnisse, die durch Korpusanalyse gewonnen wurden, durch eine parallele Sprecherbefragung zu stützen versuchen. Im zweiten Fall hilft nur die Untersuchung weiterer Daten oder, als ultima ratio, ebenfalls eine Sprecherbefragung.
Korpuslinguistik vs. Generative Grammatik
Die Korpuslinguistik geht vom Gebrauch natürlicher Sprachen aus. Sie ist eine induktive/empirische Methode zum Gewinn von Wissen über die Sprache: Die Beobachtung von möglichst vielen konkreten Einzelbeispielen führt zur Formulierung einer allgemeinen Aussage über den Gegenstand. Dieses Vorgehen („vom Speziellen zum Allgemeinen“) ist dem Empirismus zuzuordnen, der davon ausgeht, dass alles Wissen auf Erfahrung beruht. Im Gegensatz dazu steht die deduktive Methode, die sich aus der philosophischen Tradition des Rationalismus herleitet: Ausgehend von der Überlegung, wie ein bestimmtes sprachliches Phänomen beschaffen ist, wird versucht, in den Sprachen Belege als Bestätigung dafür zu finden („vom Allgemeinen zum Speziellen“).
Das unterscheidet die Korpuslinguistik grundsätzlich von der von Noam Chomsky begründeten Generativen Transformationsgrammatik und ihren Nachfolgern, deren erklärtes Ziel auch die Untersuchung der Sprachfähigkeit des kompetenten Sprechers als eine kognitive Leistung ist. Chomsky selbst hat mehrfach klar den Wert von authentischen Sprachbelegen für den linguistischen Erkenntnisgewinn bestritten. Er stellte fest, dass für die Untersuchung der Performanz authentische Sprachdaten, wie sie in Textkorpora vorliegen, ungeeignet sind, da bei der Produktion von Sprache immer Fehler auftreten.[3] Daher könnten anhand so erhaltener Daten keine gültigen Aussagen über das sprachliche System getroffen werden. Chomsky konzentrierte sich daher methodisch auf Introspektion und auf Sprecherurteile, die unter Laborbedingungen von kompetenten Muttersprachlern elizitiert werden. Die Korpuslinguistik dagegen verzichtet auf die Betrachtung des Unterschieds zwischen Sprachkompetenz und -performanz, den Chomsky für wesentlich hält.
Es ist in jüngster Zeit aber eine Annäherung zwischen diesen beiden Positionen zu beobachten. In beiden Lagern betrachtet man mittlerweile die eigene Datenbasis kritischer und ist bereit, die von der jeweils anderen Seite bevorzugten Daten zumindest als Instrument zur Kontrolle der eigenen Erkenntnisse heranzuziehen.[4]
Geschichte und Anwendungsgebiete
Die weite Verbreitung und die hohe Bedeutung der englischen Sprache sowie eine insgesamt hohe Affinität zur empirischen Forschung in der Sprachwissenschaft sind zwei Gründe, weshalb sich die computergestützte Datenanalyse, wie sie die Korpuslinguistik eine ist, zuerst im anglo-amerikanischen Raum entwickelt hat.
Die dortige moderne Korpuslinguistik wurde 1967 von Henry Kucera (1925–2010) und Nelson Francis durch ihre Arbeit „Computational Analysis of Present-Day American English“ begründet. Deren Ergebnisse wurden anhand des „Brown-Corpus“ (genau: „Brown University Standard Corpus of Present-Day American English“) gewonnen. Dieses umfasste ursprünglich rund 1 Million Wörter. Weitere englischsprachige Korpora folgten, wie etwa in den 1980er Jahren das gleich große „Lund-Oslo-Bergen-Korpus“ (LOB). Eine neue Wegmarke wurde durch die Erstellung eines diese Zahl weit überschreitenden Textkorpus im Rahmen der lexikographischen Arbeiten beim englischen Collins Verlag erreicht. Dessen Ergebnis war die erste Auflage des „Collins Cobuild Dictionary of English“. Ihm folgte in einer neuen Größenordnung die nicht-kommerzielle Erstellung eines ausgewogenen, 100 Millionen laufende Wörter umfassenden „British National Corpus“, das heute immer noch als Referenzkorpus für linguistische Untersuchungen des britischen Englisch verwendet wird. Ihm tritt heute das „American National Corpus“ zur Seite. Andere regionale Varietäten des Englischen werden im „International Corpus of English“ (ICE) erfasst.
Vorreiter der deutschen Korpuslinguistik waren das Institut für Kommunikationswissenschaft und Phonetik (IKP) an der Universität Bonn und das Institut für Deutsche Sprache in Mannheim. Heute sind als deutschsprachige Korpora besonders folgende zu nennen:
- das „Deutsche Referenzkorpus“ (DeReKo) am Institut für Deutsche Sprache in Mannheim, das mehrere Milliarden Textwörter umfasst
- das Kernkorpus des „Digitalen Wörterbuchs der Deutschen Sprache“ (DWDS) an der Berlin-Brandenburgischen Akademie der Wissenschaften
- das Korpus des Projekts „Deutscher Wortschatz“ an der Universität Leipzig (vorwiegend Texte aus Online-Medien)
- das „Schweizer Textkorpus“ der Universität Basel (heute am Schweizerischen Idiotikon, mit gegen 25 Mio. Textwörtern)
Neben diesen der Öffentlichkeit kostenlos zugänglichen Korpora mit garantierter Langzeitpflege gibt es eine Vielzahl von Spezialkorpora für viele Sprachstufen und Varietäten des Deutschen. (Eine Übersicht hierüber geben Lemnitzer / Zinsmeister (2010).)
Korpora werden, wie das Beispiel des Collins Cobuild Projekts, aber auch das American Heritage Dictionary (1969) zeigen, von einer Lexikographie genutzt, die dem Benutzer nicht nur präskriptive (wie soll ein Wort benutzt werden), sondern auch deskriptive (wie wird ein Wort tatsächlich benutzt) Beschreibungen anbieten will. Quantitative Erhebungen zu Worthäufigkeitsstatistiken können die Lemmaauswahl für viele Arten von Wörterbüchern steuern und objektivieren. Heute ist die Verwendung von Korpora auch in deutschen Wörterbuchverlagen etabliert. Einige Arten von lexikalischen Informationen können erst auf Grund der Analyse großer Textkorpora gewonnen werden (z. B. zeitlich gestaffelte Frequenzprofile), andere können durch Korpora besser abgesichert werden als durch die Sprachkompetenz einzelner Lexikographen.
Korpora werden heute auch vermehrt in der Sprachdidaktik als Forschungsgrundlage genutzt. Anhand der Ergebnisse, wie eine Sprache tatsächlich gebraucht wird, werden auch die Unterrichtsmaterialien gestaltet, und so genannte Lernerkorpora zeigen auf, in welchen Lernstadien welche Fehler bei der Sprachproduktion vorherrschen.
Für spezielle linguistische Fragestellungen werden in zunehmendem Ausmaß auch andere spezielle Korpora erarbeitet, die im Umfang erklärlicherweise weitaus kleiner sind als Referenzkorpora, die eine Sprache insgesamt erfassen sollen. Solche gibt es beispielsweise im Bereich der Untersuchungen des Sprachgebrauchs in der Politik und in den Medien.
Korpuslinguistik – Methode oder Disziplin?
Die Frage, ob die Korpuslinguistik eine Methode der Allgemeinen oder der Angewandten Linguistik ist oder eine eigene sprachwissenschaftliche Disziplin darstellt, ist noch nicht abschließend beantwortet.
Für die Einschätzung als Methode spricht, dass viele Zweige der Linguistik, von der Theoretischen bis zur Forensischen Linguistik, sich einer empirischen, korpusbezogenen Analysetechnik in methodisch reflektierter Weise bedienen, wenn auch meistens nicht ausschließlich. Ein genuiner Gegenstand der Korpuslinguistik ist hingegen nicht erkennbar. Ein solcher wäre aber notwendig, wollte man ihr den Status einer eigenständigen wissenschaftlichen Disziplin zusprechen.
Für die Einschätzung, dass die Korpuslinguistik eine eigenständige Disziplin ist, spricht der Umstand, dass sie dezidiert den Sprachgebrauch als ihren Erkenntnisgegenstand bestimmt und sich damit von Schulen der Linguistik absetzt, die die Sprachfähigkeit des Menschen oder die generellen Strukturen von Sprache als semiotisches System zum Gegenstand haben.
Ungeachtet dieser grundsätzlichen Erwägung hat sich die Korpuslinguistik als Wissenschaftszweig im akademischen Leben etabliert. Darauf deuten die Existenz mehrerer thematischer Fachzeitschriften, eines zwei Bände umfassenden Handbuchs (Lüdeling / Kytö 2008, 2009) sowie zweier dedizierter Lehrstühle an der Universität Birmingham und an der Berliner Humboldt-Universität hin.
Literatur
- Druckwerk
- Andrea Abel, Renata Zanin: Korpora in Lehre und Forschung. Bozen-Bolzano University Press, Bozen 2011, ISBN 978-88-6046-040-0.
- Noah Bubenhofer: Sprachgebrauchsmuster. Korpuslinguistik als Methode der Diskurs- und Kulturanalyse. de Gruyter, Berlin/ New York 2009, ISBN 978-3-11-021584-7.
- Noam Chomsky: Knowledge of Language. Praeger, New York 1986.
- Reinhard Fiehler, Peter Wagener: Die Datenbank Gesprochenes Deutsch (DGD). In: Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion. Band 6, 2005, S. 136–147.
- Hagen Hirschmann: Korpuslinguistik. Eine Einführung. Metzler Verlag, Stuttgart 2019, ISBN 978-3-476-05493-7.
- Werner Kallmeyer, Gisela Zifonun (Hrsg.): Sprachkorpora – Datenmengen und Erkenntnisfortschritt. (= IDS Jahrbuch. 2006). de Gruyter, Berlin/ New York 2007.
- András Kertész, Csilla Rákosi: Daten und Evidenz in linguistischen Theorien: Ein Forschungsüberblick. In: A. Kertész, Cs. Rákosi (Hrsg.): New Approaches to Linguistic Evidence. Pilot Studies / Neue Ansätze zu linguistischer Evidenz. Pilotstudien. Lang, Frankfurt am Main u. a. 2008, S. 21–60.
- Reinhard Köhler: Korpuslinguistik. Zu wissenschaftstheoretischen Grundlagen und methodologischen Perspektiven. In: LDV-Forum 20/2. (PDF; 5,4 MB). 2005, S. 1–16.
- Snježana Kordić: Der Relativsatz im Serbokroatischen (= Lincom Studies in Slavic Linguistics. Band 10). Lincom Europa, München 1999, ISBN 3-89586-573-7, S. 330.
- Lothar Lemnitzer, Heike Zinsmeister: Korpuslinguistik. 2., überarbeitete Auflage. Gunter Narr Verlag, Tübingen 2010.
- Winfried Lenders: Computational lexicography and corpus linguistics until ca. 1970/1980. In: R. H. Gouws, U. Heid, W. Schweickard, H. E. Wiegand (Hrsg.): Dictionaries – An International Encyclopedia of Lexicography. Supplementary Volume: Recent Developments with Focus on Electronic and Computational Lexicography. de Gruyter Mouton, Berlin 2013, ISBN 978-3-11-214665-1, S. 982–1000.
- Anke Lüdeling, Merja Kytö: Corpus Linguistics. An International Handbook. Vol. 1, de Gruyter, Berlin/ New York 2008; Vol. 2, 2009.
- Tony McEnery, Andrew Wilson: Corpus linguistics: an introduction. 2. Auflage. Edinburgh University Press, 2001.
- Tony McEnery, Richard Xiao, Yukio Toni: Corpus-Based Language Studies: An advanced resource book. Routledge, New York 2006, ISBN 0-415-28622-0.
- Rainer Perkuhn, Holger Keibel, Marc Kupietz: Korpuslinguistik. Fink/ UTB, Paderborn 2012, ISBN 978-3-8252-3433-1.
- Carmen Scherer: Korpuslinguistik. (= Kurze Einführungen in die germanistische Linguistik. Band 2). Winter, Heidelberg 2006.
- P. Wagener, K.-H. Bausch (Hrsg.): Tonaufnahmen des gesprochenen Deutsch. Dokumentation der Bestände von sprachwissenschaftlichen Forschungsprojekten und Archiven. (= Phonai. Band 40). Niemeyer, Tübingen 1997.
- Onlineausgaben
- Tony McEnery, Andrew Wilson: Corpus Linguistics. 1996. Ergänzende Website zur ersten Auflage des gleichnamigen Buches der beiden Autoren
- Rainer Perkuhn, Holger Keibel, Marc Kupietz: Korpuslinguistik. 2012. Ergänzende Website zum gleichnamigen Lehrbuch der Autoren
- Marco Zierl: Entwicklung und Implementierung eines Datenbanksystems zur Speicherung und Verarbeitung von Textkorpora. Magisterarbeit. 1997. (mit einem großen Teil zu Grundlagen der Korpuslinguistik)
Weblinks
- Lehrgänge und Linklisten
- Noah Bubenhofer: Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. – Online-Kurs
- Bookmarks for Corpus-based Linguists. Linksammlung zu verschiedenen Korpora sowie korpuslinguistischen Arbeiten und Lehrmaterialien
- Kristin Berberich, Ingo Kleiber: Tools for Corpus Linguistics – eine Liste von Werkzeugen für die Korpusanalyse
- Korpora
- Wortschatzlexikon der Universität Leipzig
- Digitales Wörterbuch der Deutschen Sprache der Berlin-Brandenburgischen Akademie der Wissenschaften
- Deutsches Textarchiv (DTA) Grundlage für ein historisches Referenzkorpus der deutschen Sprache
- Deutsches Referenzkorpus (recherchierbar über die webbasierte Software COSMAS II) des Instituts für Deutsche Sprache
- Forschungs- und Lehrkorpus Gesprochenes Deutsch (FOLK) (recherchierbar über die Datenbank für Gesprochenes Deutsch (DGD)) des Instituts für Deutsche Sprache
- Schweizer Textkorpus der Universität Basel
- Austrian Academy Corpus – vollständige, recherchierbare Ausgaben der Zeitschriften „Die Fackel“ und „Der Brenner“ an der Österreichischen Akademie der Wissenschaften
- Mehrsprachige Korpora des Hamburger Zentrums für Sprachkorpora
- Google Books Ngram Viewer wertet N-Gramme der Google Books Corpora in Form von Diagrammen aus (engl.)
- Software
- CorpusExplorer – Open-Source-Software zur einfachen Aufbereitung (über 100 Dateiformate), automatischer Annotation (über 60 Sprachen) und Auswertung (über 40 verschiedene Analysen). Außerdem stehen für den CorpusExplorer bereits annotierte Referenzkorpora (Plenarprotokolle, Historische Sprachstufen, schriftliche/mündliche Korpora, uvm.) mit über 5,5 Mrd. Token zur Verfügung.
Einzelnachweise
- Snježana Kordić: Wörter im Grenzbereich von Lexikon und Grammatik im Serbokroatischen (= Lincom Studies in Slavic Linguistics. Band 18). Lincom Europa, München 2001, ISBN 3-89586-954-6, S. 280.
- Burghard Rieger: Repräsentativität: von der Unangemessenheit eines Begriffs zur Kennzeichnung eines Problems linguistischer Korpusbildung. In: H. Bergenholtz, B. Schaeder (Hrsg.): Empirische Textwissenschaft. Aufbau und Auswertung von Text-Corpora. (= Monographien Linguistik und Kommunikationswissenschaft. 39). Scriptor, Königstein/Taunus 1979, S. 52–70.
- Vgl. Chomsky 1986.
- Einen historischen Abriss geben Kertész / Rákosi 2008 sowie Lenders 2013.