Dokumentenretrieval
Dokumentenretrieval (engl. Document Retrieval) bezeichnet den computergestützten Prozess der Rückgewinnung von Dokumenten (engl. to retrieve, zurückgewinnen, wiederauffinden), die für einen Anwender entsprechend seinem Informationsbedürfnis relevant sein könnten. Sein Informationsbedürfnis drückt der Anwender in Form einer Suchanfrage aus. Häufig wird Document Retrieval auch als Information Retrieval bezeichnet, in den meisten Fällen werden die Begriffe synonym verwendet.
In Dokumenten liegt das unternehmerische Gedächtnis verborgen. Schlechter Zugang zum Inhalt dieser Dokumente bedeutet schlechten Zugang zu dem Wissen, das eine Organisation im Laufe der Zeit produziert hat oder besitzt. Somit kommt dem Document Retrieval eine enorme Bedeutung zu, da nicht mehr zugängliche Informationen erneut erarbeitet werden müssen.
Geschichte
Schon vor dem Mittelalter organisierte die Menschheit Informationen derart, dass sie zu einem späteren Zeitpunkt wiedergefunden und verwendet werden konnten. Das einfachste Beispiel ist das Inhaltsverzeichnis eines Buches: Es besteht aus Mengen von Worten oder Begriffen, mit denen die Seiten verbunden sind, auf denen Informationen zu diesen Begriffen gefunden werden können. Ein solcher Index ist teil eines jeden Informationssystems.[1]
1945 beschrieb Vannevar Bush in seinem Artikel As We May Think die Vision von einem System, das er Memex nannte, eine Art Erweiterung des Gehirns. Darin soll ein Individuum sämtliche Informationen und Aufzeichnungen speichern und diese schnell und flexibel wieder abrufen können.[2]
Seit den 1940er Jahren wurde dem Problem, Informationen zu speichern und effizient wieder aufzufinden, zunehmend Aufmerksamkeit gewidmet. Ursache hierfür war, dass ein schneller Zuwachs an Informationen stattfand, zu welchen schneller Zugriff gewünscht wurde. Der nötige Platz, um diese Informationen in Papierform und in Ordnern beziehungsweise Büros zu halten, reichte bald nicht mehr aus. Es begann die Digitalisierung von Daten, wodurch die Probleme der effizienten Speicherung und Wiederauffindung in den Mittelpunkt rückten. Durch die Erfindung der CD eröffnete sich eine neue Möglichkeit, Daten kompakt zu speichern und diese zusätzlich einfach verteilen zu können. An Methoden zur Rückgewinnung wurde geforscht, aber Tests in Dimensionen mit kommerzieller Anwendbarkeit fanden nur wenige statt. Mit der Veröffentlichung des Internets war schließlich für jeden Nutzer die Möglichkeit geschaffen, Informationen im Netz zu veröffentlichen. Moderne Suchmaschinen versuchen dieser neuerlichen Flut an Informationen Herr zu werden. Die Forschung sieht sich dabei schon seit der ersten Generation von Document Retrieval-Systemen mit der zentralen Fragestellung konfrontiert, welche die relevanten Informationen sind. Ein Verständnis für diese Problematik sowie die notwendigen Werkzeuge, um Document Retrieval-Systeme für derartige Mengen an Informationen entwerfen und betreiben zu können, sind aber selbst zu Beginn des 21. Jahrhunderts noch nicht in vollem Maße vorhanden. Wiederholte Vorfälle in Unternehmen, die aufgrund von mangelnder Dokumentkontrolle große Summen Geld verloren haben, bestätigen dies.[3][4][5]
Erste kommerzielle Document Retrieval-Systeme waren:
- DIALOG wurde von Lockheed entworfen und ermöglichte den Zugang zu veröffentlichten Forschungsartikeln.
- LexisNexis stellte Fachdatenbanken bereit.
- STAIRS wurde von IBM entwickelt und war für die Freitextrecherche gedacht.
- FAIRS wurde von Fujitsu (Japan) entwickelt und ähnelt STAIRS.
- GOLEM ist ein interaktives Datenbanksystem der Firma Siemens
- GRIPS wurde vom Deutschen Institut für Medizinische Dokumentation und Information (DIMDI) entwickelt.
Definition
Unter einem Document Retrieval-System (DRS) wird die Gesamtheit der methodologischen Grundlagen, technischen Verfahren und Einrichtungen verstanden, die das weitgehend computergestützte Bereitstellen von Informationen ermöglichen. Diese Informationen können aus Ton, Bild, Video und Text bestehen. Wesentlich ist dabei das Zusammenspiel der Komponenten der Informationserschließung (Indexierung) und der Informationswiedergewinnung (Retrieval).
Die Darstellung der inhaltlichen Charakteristika eines Dokuments in einer für Document Retrieval verwendbaren Form wird als inhaltliche Dokumentbeschreibung bezeichnet. Die Gewinnung solch inhaltlicher Charakteristika wird Indexierung genannt. Nach DIN 31623 werden unter Indexierung alle Methoden sowie deren Anwendungen verstanden, die zur Zuordnung von Deskriptoren und Termen zu Dokumenten zwecks ihrer inhaltlichen Erschließung und gezielten Wiederauffindung führen. Der Wiederauffindungsvorgang wird allgemein als Recherche bezeichnet. Das Ergebnis der Recherche, also die Menge der vom Document Retrieval-System ausgegebenen Dokumente, wird Systemvorschlag genannt.
Als Parameter für die Güte des Document Retrievals werden meist die Maße Recall und Precision verwendet. Unter Recall (Vollständigkeit der Suche) versteht man das Verhältnis der Anzahl der relevanten Dokumente im Systemvorschlag zu der Anzahl aller hinsichtlich der Suchanfrage relevanten Dokumente. Die Precision (Genauigkeit der Suche) wird durch den Anteil der relevanten Dokumente an allen Dokumenten im Systemvorschlag ausgedrückt. Da diese Werte alleine wenig aussagen, werden sie oft in sogenannten Recall-Precision-Graphen zusammengefasst.
Die Relevanz gilt als Schlüsselbegriff der Theorie der IR-Systeme.[6] Nach Saracevic[7] ist Relevanz ein Maß für die Übereinstimmung zwischen Dokument und Suchanfrage aus der Sicht eines neutralen Schiedsrichters. Die Relevanzvorstellungen des Benutzers (auch als Pertinenz bezeichnet) und die des Systems stimmen nur selten überein. Hier wird ein zentrales Problem des Document Retrieval deutlich: Es ist vor einer Suchanfrage (speziell zum Zeitpunkt der Indexierung) nicht möglich zu bestimmen, welche Informationen für zukünftige Benutzer relevant sein werden.[4]
Weitere Definitionen
- Ein DRS informiert den Benutzer nicht über das Thema seiner Suchanfrage. Es liefert lediglich Informationen über die Existenz oder Nichtexistenz und den Fundort von Dokumenten, die für seine Suchanfrage relevant sein könnten.[8]
- Ein DRS umfasst die Hard- und Software, die den Anwender dabei unterstützt, von ihm gesuchte Informationen zur Verfügung zu stellen. Hauptziel eines DRS ist, den Aufwand des Benutzers, die gesuchten Informationen zu finden, zu minimieren.[9]
- Document Retrieval bezeichnet den computergestützten Prozess der Rückgewinnung von Dokumenten. Ein Benutzer stellt eine Anfrage in Form eines Queries und erhält eine nach Relevanz sortierte Liste von Dokumenten. Diese Dokumente könnten die Informationen enthalten, die er sucht (oder auch nicht). Die Sortierung des Systemvorschlags muss nicht den Relevanzvorstellungen des Benutzers entsprechen.[3]
Abgrenzung zum Data Retrieval
Folgende Tabelle zeigt die Gegenüberstellung einiger Unterschiede von Document- und dem klassischen Data Retrieval.[8][10] Für eine ausführliche Diskussion der Unterschiede und Gemeinsamkeiten sei der interessierte Leser auf[10][11] verwiesen.
| Data Retrieval | Document Retrieval | |
|---|---|---|
| Suche | exakt | unvollständig, „so gut wie möglich“ |
| Query-Sprache | künstlich | natürlich |
| Query-Spezifikation | vollständig | unvollständig |
| Modell | deterministisch | probabilistisch |
| Erfolgskriterium | Korrektheit | Nutzen des Anwenders |
In Data Retrieval wird normalerweise nach einem exakt spezifizierten Objekt, zum Beispiel „Bob’s Adresse“, gesucht. Das Ergebnis der Suche ist entweder das gesuchte Objekt (Bob’s Adresse), oder dieses ist im durchsuchten Datenbestand nicht vorhanden. Ein entsprechendes Query für eine solche Suchanfrage in SQL könnte so aussehen: SELECT Adresse FROM Angestellte WHERE NAME = Bob. Diese Suchanfrage ist in einer künstlichen Sprache vollständig spezifiziert. Sie wird entweder mit Bob’s Adresse oder mit einer Meldung, dass Bob’s Adresse nicht im Datenbestand existiert, beantwortet werden. Das Ergebnis der Suche ist dabei nur genau dann korrekt, wenn Bob’s richtige Adresse zurückgegeben wurde. Der Ausgang der Suche ist deterministisch: entweder die korrekten Daten sind vorhanden oder nicht.
In Document Retrieval wird nicht nach Bob’s Adresse gesucht, sondern beispielsweise nach Informationen über die Umgebung, in der Bob wohnt. Zunächst ist nicht klar, wie ein Query aussehen sollte, das dem Nutzer diese Informationen liefert. Für ein mögliches Query Bob Adresse Umgebung liefert das DRS Vorschläge, die der Anwender dann nach für ihn nützlichen Informationen durchsuchen kann. Das Informationsbedürfnis des Anwenders ist hier in natürlicher Sprache ausgedrückt, aber nicht vollständig spezifiziert. Für eine vollständige Spezifikation müsste der Anwender wissen, wonach er gerade sucht. Außerdem ist nicht klar, welche Vorschläge vom DRS gemacht werden und ob es die gewünschten Informationen liefern kann und wird. Hier liegt also ein probabilistisches Modell[12][13] zugrunde. Aufgrund dieser Unsicherheiten kann ein Suchergebnis nicht als korrekt oder falsch bezeichnet werden. Die dem Anwender präsentierten Dokumente können für ihn nützlich oder nutzlos sein. Dementsprechend ist hier das Erfolgskriterium einer Suche der Nutzen des Anwenders.[14]
Aufbau eines Document Retrieval-Systems
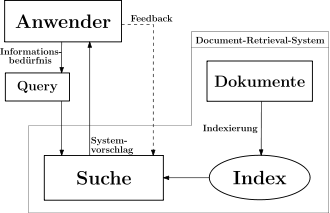
Indexierung
Gegenstand der Indexierung ist, Dokumenten eine Menge von Indextermen oder Schlüsselwörtern zuzuweisen. Dabei sollen die Indexterme[4]:
- den Inhalt des Dokuments möglichst vollständig reflektieren.
- das Dokument so beschreiben, dass es sich möglichst stark von inhaltlich ähnlichen Dokumenten unterscheidet.
Diese Schlüsselwörter können entweder automatisch, oder manuell von einem Indexierer erzeugt werden. Sie bieten eine logische Sicht auf ein Dokument. Die beste Möglichkeit, ein Dokument darzustellen, ist mit seinem vollständigen Inhalt. Dies führt aber zu hohem Speicherplatzbedarf des Indexes. Er wäre dann genauso groß wie die Dokumente, die er indexiert. Daher muss eine Dokument-Repräsentation gefunden werden, die die beiden oben aufgeführten Anforderungen möglichst vollständig erfüllt. Dieser Prozess besteht in der Regel aus folgenden Schritten.[8]
Zunächst werden Sonderzeichen nach vorgegebenen Regeln und häufig vorkommende Wörter wie z. B. Artikel und Verbindungswörter mithilfe einer stop list entfernt. Eine stop list enthält alle Wörter, die für eine inhaltliche Beschreibung des Dokuments irrelevant sind und aus dem Text entfernt werden. Diese werden dann bei Suchanfragen nicht mit einbezogen und vereinfachen somit den Suchprozess. Zusätzlich wird durch diesen Schritt die Größe des ursprünglichen Dokuments um 30–50 % reduziert.[8]
Anschließend werden alle Wörter auf ihren Wortstamm reduziert, indem ihre Suffixe entfernt werden (sog. Stemming). Somit werden alle Worte, die semantisch äquivalent sind, auf den gleichen Wortstamm abgebildet, z. B. werden die Begriffe Fahrer, fahren und Fahrschule abgebildet auf fahr. Die Annahme des Stemming ist, dass Wörter mit demselben Wortstamm zur gleichen Wortfamilie gehören und daher auch als gleich behandelt werden können. Diese Vereinfachung kann aber auch zu Fehlern führen, da durchaus Worte mit gleichem Wortstamm aber unterschiedlicher Bedeutung existieren, wie beispielsweise Neutron und neutralisieren. Außerdem können äquivalente Wörter in unterschiedlichen Zusammenhängen verschiedene Bedeutungen haben. Das Ergebnis dieses Verarbeitungsschrittes ist eine Klasse für jeden Wortstamm. Kommt ein Wort einer Klasse in einem Dokument vor, so wird dem Dokument diese Klasse als Schlüsselwort zugewiesen.[8][3]
Zum Schluss werden alle Indexterme entsprechend dem im DRS implementierten Modell gewichtet. Dann wird ein Index erstellt, der eine schnelle Suche in der Menge der Indexterme ermöglicht, indem diese mit den Dokumenten verknüpft werden, in denen sie enthalten sind. Bei Bedarf können weitere wichtige Informationen wie die Position des Terms im Dokument oder der Autor gespeichert werden. Eine häufig anzutreffende Indexstruktur ist die inverted file. Weitere Datenstrukturen und deren Beschreibungen wie sequential files, index-sequential files und multi-lists können in Kapitel 4 in[8] gefunden werden.[3]
Es kann zusätzlich Clustering eingesetzt werden, wobei ähnliche Dokumente[15][16][17][18][19] einem Cluster zugewiesen werden. Die Suche in einem solch vorklassifizierten Informationsbestand wird Clustersuche genannt und läuft in zwei Schritten ab. Zunächst werden nur Cluster mit hoher Relevanz gesucht. Anschließend werden die Dokumente in diesen Clustern inspiziert und die relevantesten herausgesucht. Durch Clustering soll die Effizienz von Document Retrieval-Systemen durch Reduktion der nötigen Dokumentvergleiche gesteigert werden. Es ist offensichtlich, dass sich dadurch aber die Effektivität senken kann.[4][8]
Retrieval
Der Prozess des Lokalisierens der Informationen, die ein Benutzer erhalten möchte, besteht aus mehreren Schritten. Zunächst muss er sein Informationsbedürfnis in eine für die Suchmaschine verständliche Form, ein sogenanntes Query, umwandeln. Dieses Query wird schließlich in eine Query-Repräsentation überführt. Die meisten Prozesse, die die Dokumente während der Indexierung durchlaufen, durchläuft auch ein Query. Alle nachfolgend beschriebenen Vorgänge laufen ab, während der Nutzer auf die Antwort seiner Suchanfrage wartet. Zunächst werden für die Suche irrelevante Begriffe und Zeichen wie z. B. „Ich suche nach Informationen über:“ entfernt. Dann werden mithilfe der stop list ebenfalls irrelevante Begriffe entfernt und Stemming durchgeführt. Schließlich wird die Query-Repräsentation erzeugt, wobei auch für den Suchalgorithmus notwendige logische Operatoren eingefügt werden können. Es ist auch möglich, die Terme des Queries zu expandieren und so verwandte Terme, die mit dem gesuchten Begriff in Verbindung stehen, in die Suche mit einzuschließen. Diese verwandten Terme können synonyme Begriffe sein, die in elektronischen Thesauri gefunden werden, oder aber mit dem Query-Term aufgrund semantischer Eigenschaften (z. B. bestimmte Wortreihenfolge) in besonderer Verbindung stehen. Dieser Bearbeitungsschritt befreit den Anwender von der Notwendigkeit, alle Varianten seines Queries auszuprobieren, um möglichst viele für ihn relevante im Suchergebnis zu erhalten. Somit wird möglicherweise der Recall erhöht, aber die Präzision wird sinken, wenn expandierte Terme zur Rückgewinnung irrelevanter Dokumente führen.[3]
Schließlich erfolgt die eigentliche Suche. Die verwendeten Suchalgorithmen sind durch das implementierte Modell des DRS vorgegeben. Der Index wird nach Dokumenten durchsucht, die Terme des Queries enthalten. Für jedes Dokument wird der sogenannte similarity score mit dem Query berechnet. Die Berechnung erfolgt mit einem Algorithmus, der ebenfalls vom implementierten Modell des DRS vorgegeben ist. Anschließend erfolgt die Sortierung oder das Ranking der Dokumente entsprechend ihrer similarity scores. Die sortierte Liste wird dem Nutzer (eventuell mit einer kurzen Beschreibung jedes Dokumentes) zur Verfügung gestellt. Er kann die Liste oder auch den Inhalt der Dokumente genauer betrachten. Manche Systeme bieten auch die Möglichkeit des anwenderbasierten Relevanz-Feedbacks, sodass der Nutzer für ihn relevante Dokumente markieren kann. Das System initiiert daraufhin einen neuen Suchvorgang basierend auf diesen Bewertungen und liefert eine überarbeitete Liste von Dokumenten, die (hoffentlich) mehr für den Nutzer relevante Dokumente enthält. Der Prozess des Relevanz-Feedbacks kann beliebig oft durchgeführt werden.[3]
Theoretische Document Retrieval-Modelle
Folgende theoretischen Modelle werden in Document Retrieval-Systemen implementiert. Die Wahl des Modells hat Auswirkungen auf die Suchalgorithmen und die Berechnungen der Rankings und Scores. In Kapitel 2[1] werden diese ausführlich beschrieben.
Klassische Modelle:
Moderne wahrscheinlichkeitstheoretische Modelle:
Alternative Paradigmen:
- erweitertes boolesches Modell
- verallgemeinertes Vektorraum-Modell
- Semantische Indexierung
- Neuronale Netze
- Fuzzy Retrieval
Einzelnachweise
- Ricardo Baeza-Yates, Berthier de Araújo Neto Ribeiro, Berthier Ribeiro-Neto: Modern information retrieval. ACM Press, 1999, ISBN 0-201-39829-X.
- V. Bush: As We May Think. In: Atlantic Monthly. Volume 176(1), Pages 101-108, 1945, doi:10.1.1.128.2127.
- Elizabeth D. Liddy: Automatic Document Retrieval. In: Encyclopedia of Language & Linguistics. 2. Edition, Elsevier Limited, 2005, CNLP (Memento vom 23. August 2012 im Internet Archive) (DOI nicht verfügbar).
- versch. Autoren: Handbuch der modernen Datenverarbeitung. Forkel-Verlag, Heft 133, Januar 1987, ISSN 0723-5208.
- D. C. Blair: The challenge of commercial document retrieval, Part I: Major issues, and a framework based on search exhaustivity, determinacy of representation and document collection size. In: Information Processing and Management: an International Journal archive. Volume 38, Issue 2, Pages 273-291, Pergamon Press, Inc. Tarrytown, New York, March 2002, doi:10.1016/S0306-4573(01)00024-3.
- J. Panyr: Relevanzproblematik in Information-Retrieval-Systemen. In: Nachr. f. Dokumente. S. 2–4, 1986.
- T. Saracevic: RELEVANCE: A Review if a Framework for the Thinking on the Notion in Information Science. In: Journal of the ASIS. Pages 321-343, 1975.
- C. J. van Rijsbergen: Information Retrieval. Butterworth-Heinemann, 1979, ISBN 0-408-70929-4.
- Gerald Kowalski: Information Retrieval – Architecture and Algorithms. Springer, 2011, ISBN 978-1-4419-7715-1.
- D. C. Blair: The data-document distinction in information retrieval. In: Communications of the ACM. Volume 27, Issue 4, Pages 369-374, New York, April 1984, doi:10.1145/358027.358049.
- D. C. Blair: The data-document distinction revisited. In: ACM SIGMIS Database. Volume 37, Issue 1, Pages 77-96, New York, Winter 2006, doi:10.1145/1120501.1120507.
- W. S. Cooper, M. E. Maron: Foundations of Probabilistic and Utility-Theoretic Indexing. In: Journal of the ACM. Volume 25, Pages 67-80, 1978, doi:10.1145/322047.322053.
- S. E. Robertson, M. E. Maron, W. S. Cooper: Probability of relevance: a Unification of Two Competing Models for Document Retrieval. In: Information Technology: Research and Development. Volume 1, Pages 1-21, 1982.
- W. S. Cooper: On Selecting a Measure of Retrieval Effectiveness, Part I: The "Subjective" Philosophy of Evaluation. In: Journal of the American Society for Information Science. Volume 24, Pages 87-100, 1973, doi:10.1002/asi.4630240204.
- G. Salton: Automatic Information Organization and Retrieval. McGraw-Hill, New York, 1968, ISBN 0070544859.
- L. Goodman, W. Kruskal: Measures of association for cross-classifications. In: Journal of the American Statistical Ass. Volume 49, Pages 732-764, 1954, doi:10.2307/2281536.
- L. Goodman, W. Kruskal: Measures of association for cross-classifications II: Further discussions and references. In: Journal of the American Statistical Ass. Volume 54, Pages 123-164, 1959, doi:10.1080/01621459.1959.10501503.
- J. L. Kuhns: The continuum of coefficients of association. In: Statistical Association Methods for Mechanised Documentation. Pages 33-39, Washington, 1965, (doi nicht verfügbar).
- R. M. Cormack: A review of classification. In: Journal of the Royal Statistical Society. Series A, volume 134, Pages 321-353, 1971, doi:10.2307/2344237.