Data Vault
Data Vault ist eine Modellierungstechnik für Data Warehouses, die insbesondere für agile Data Warehouses geeignet ist. Sie bietet eine hohe Flexibilität bei Erweiterungen, eine vollständige unitemporale Historisierung der Daten und erlaubt eine starke Parallelisierung der Datenladeprozesse.
Geschichte
Entwickelt wurde die Data-Vault-Modellierung in den 1990ern von Dan Linstedt, der zu dieser Zeit für die National Security Agency tätig war.[1] Nach ersten Veröffentlichungen im Jahr 2000 erlangte Data Vault ab 2002 durch eine Reihe von Artikeln in The Data Administration Newsletter größere Aufmerksamkeit.[2] 2007 gewann Linstedt die Unterstützung Bill Inmons, der Data Vault als die „optimale Wahl“ für seine DW-2.0-Architektur bezeichnete.[3]
2009, 2011 und 2015 veröffentlichte Linstedt, teilweise zusammen mit anderen Autoren, Bücher über Data Vault. Seit 2013 propagiert er unter der Bezeichnung Data Vault 2.0 ein Paket aus Modellierungs-, Architektur- und Methodologieansätzen.[4] Linstedts ehemaliger Geschäftspartner Hans Hultgren veröffentlichte 2012 ebenfalls ein Buch über Data-Vault-Modellierung, 2019 folgte ein Buch des Australiers John Giles über die Erstellung von Data-Vault-Modellen mit Hilfe von Patterns.[5]
Besondere Popularität erlangte Data Vault in den Niederlanden.[6]
Modellierung
Data Vault vereint Aspekte der relationalen Datenbankmodellierung mit der dritten Normalform (3NF) und des Sternschemas. Es gehört zu einer Familie von Modellierungstechniken, die von verschiedenen Autoren als hypernormalisierte[7] oder Ensemble-Modellierung[8] bezeichnet wird.
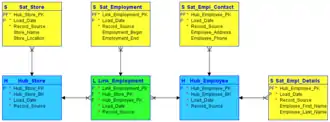
Bei der Data-Vault-Modellierung werden alle zu einem Geschäftskonzept (wie Kunde oder Produkt) gehörenden Informationen in drei Kategorien eingeteilt und entsprechend in drei verschiedenen Typen von Datenbanktabellen abgelegt. Hultgren nennt diese Vorgehensweise „unified decomposition“, weil die Informationen zwar in unterschiedlichen Tabellen abgelegt werden, aber weiterhin durch einen gemeinsamen Schlüssel verbunden sind.[9]
In die erste Kategorie „Hub“ gehören Informationen, die ein Geschäftskonzept eindeutig beschreiben, d. h. ihm seine Identität geben (z. B. Kundennummer beim Kunden). Ein Hub ist somit eine Liste von eindeutigen Geschäftsschlüsseln und dient als Integrationspunkt für Daten aus verschiedenen Quellen.[10]
In die zweite Kategorie „Link“ gehören alle Arten von Beziehungen zwischen Geschäftskonzepten (z. B. Zuordnung eines Kunden zu einer Branche). Dies können hierarchische Beziehungen sein (z. B. Mitarbeiter untersteht Manager), Geschäftsvorgänge (z. B. Arzt behandelt Patient in Krankenhaus) oder auch Identitätsbeziehungen (zwei Kundennummern bezeichnen denselben Kunden).[11]
Alle Attribute, die ein Geschäftskonzept oder eine Beziehung beschreiben (z. B. Name, Geburtsdatum oder Geschlecht eines Kunden), gehören in die dritte Kategorie „Satellit“. In den Satelliten findet auch die unitemporale Historisierung statt. Ein Hub oder Link kann mehrere Satelliten haben, die beispielsweise nach Datenquelle oder Änderungshäufigkeit aufgeteilt sind.[12]
Durch diese Art der Modellierung sind Änderungen flexibel möglich, so dass in der Regel keine bestehenden Tabellen angepasst werden müssen, sondern einfach neue Tabellen (z. B. neue Attribute in einem zusätzlichen Satelliten) hinzugefügt werden. Durch die starke Schematisierung der Datenladeprozesse können ETL-Prozess-Templates verwendet werden, so dass im besten Fall zur Änderung bzw. Erweiterung des Datenladeprozesses nur eine Anpassung der Konfiguration notwendig ist.[13]
Literatur
- Patrick Cuba: The Data Vault Guru. A Pragmatic Guide on Building a Data Vault. Selbstverlag, ohne Ort 2020, ISBN 979-86-9130808-6.
- John Giles: The Elephant in the Fridge. Guided Steps to Data Vault Success through Building Business-Centered Models. Technics, Basking Ridge 2019, ISBN 978-1-63462-489-3.
- Kent Graziano: Better Data Modeling. An Introduction to Agile Data Engineering Using Data Vault 2.0. Data Warrior, Houston 2015.
- Hans Hultgren: Modeling the Agile Data Warehouse with Data Vault. Brighton Hamilton, Denver u. a. 2012, ISBN 978-0-615-72308-2.
- Dirk Lerner: Data Vault für agile Data-Warehouse-Architekturen. In: Stephan Trahasch, Michael Zimmer (Hrsg.): Agile Business Intelligence. Theorie und Praxis. dpunkt.verlag, Heidelberg 2016, ISBN 978-3-86490-312-0, S. 83–98.
- Daniel Linstedt: Super Charge Your Data Warehouse. Invaluable Data Modeling Rules to Implement Your Data Vault. Linstedt, Saint Albans, Vermont 2011, ISBN 978-1-4637-7868-2.
- Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0. Morgan Kaufmann, Waltham, Massachusetts 2016, ISBN 978-0-12-802510-9.
- Dani Schnider, Claus Jordan u. a.: Data Warehouse Blueprints. Business Intelligence in der Praxis. Hanser, München 2016, ISBN 978-3-446-45075-2, S. 35–37, 161–173.
Weblinks
- Dan Linstedts Website
- Hans Hultgrens Website
- Data Vault Ensemble Modeling Standards
- Kent Graziano: Data Vault Series
- Michael Olschimkes Blog
- Roelant Vos’ Blog (mit Schwerpunkt auf Data-Vault-Implementierung)
- Deutschsprachige Data Vault User Group
- 2150 Datavault Builder
- WhereScape Data Vault Express
Einzelnachweise
- Where did #datavault get it’s name?.
- Data Vault Series 1 – Data Vault Overview.
- The new evolution of Data Modeling.
- A short intro to #datavault 2.0.
- John Giles: The Elephant in the Fridge. Basking Ridge 2019, ISBN 978-1-63462-489-3.
- Data Vault in the Netherlands.
- Modeling to Support Agile Data Warehouses: Hyper Normalization and Hyper Generalization.
- Ensemble Modeling.
- Hans Hultgren: Modeling the Agile Data Warehouse with Data Vault. Denver u. a. 2012, ISBN 978-0-615-72308-2, S. 21–22.
- Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0. Waltham 2016, Kapitel 4.3.
- Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0. Waltham 2016, Kapitel 4.4.
- Daniel Linstedt, Michael Olschimke: Building a Scalable Data Warehouse with Data Vault 2.0. Waltham 2016, Kapitel 4.5.
- Data Vault – die revolutionäre Data Warehouse Modellierung?. Blogpost von Markus Bellmann, (linkFISH Consulting GmbH) vom 19. Januar 2015. Jetzt ganz einfach Data Vault modellieren. 6-teilige Webcast-Reihe zu Data Vault von Michael Müller (MID GmbH) vom Oktober 2014. Datenmodellierung mit Data Vault & ETL in die Data Vault Tabellen und in die Data Mart Dimensionen. Blogpost von Claus Jordan vom 15. Oktober 2013.