Genetische Repräsentation
Als genetische Repräsentation (auch Problemrepräsentation) wird die Art und Weise bezeichnet, wie ein Optimierungsproblem codiert wird, sodass es mit einem evolutionären Algorithmus (EA) gelöst werden kann. EA suchen Lösungen für Optimierungsprobleme mit Methoden der natürlichen Evolution. Der Begriff der genetischen Repräsentation umfasst dabei sowohl die konkreten Datenstrukturen und Datentypen, mit denen das genetische Material der Lösungskandidaten in Form eines Genoms realisiert wird, als auch die Beziehungen zwischen Suchraum und Problemraum. Im einfachsten Fall entspricht der Suchraum dem Problemraum (direkte Repräsentation). Die Wahl der Problemrepräsentation ist gebunden an die Wahl der genetischen Operatoren, beide wirken sich entscheidend auf die Effizienz der Optimierung aus.
Das Genom eines Lösungskandidaten hat oft die Form eines Bitstrings, einer Liste reeller Zahlen, einer Reihenfolge (bei kombinatorischen Problemen wie Travelling Salesman) oder eines Baumes.
Unterscheidung Such- und Problemraum
In der Natur ist die Information über sämtliche grundlegenden Eigenschaften (Phänotyp) eines Organismus (z. B. Äußere Erscheinung, Stoffwechsel oder basales Verhalten) innerhalb jedes Organismus gespeichert, wie schon Gregor Mendel um 1860 entdeckte. Heute ist bekannt, dass diese Speicherung mit dem genetischen Code realisiert wird. Auf molekularer Ebene sind die definierenden Eigenschaften als DNA codiert. Die gesamte genetische Ausstattung eines Organismus wird als Genotyp bezeichnet. Der Genotyp bestimmt den Phänotyp, allerdings über einen komplizierten Prozess, die Genexpression.
Analog zur Biologie wird bei evolutionären Algorithmen zwischen Problemraum (entspricht Phänotyp) und Suchraum (entspricht Genotyp) unterschieden. Der Problemraum enthält also konkrete Lösungen für das behandelte Problem, während der Suchraum die codierten Lösungen enthält. Die Abbildung (engl. map) von Suchraum auf Problemraum wird als Genotype-Phenotype-Mapping bezeichnet. Die genetischen Operatoren werden auf Elemente des Suchraums angewandt, zur Auswertung werden Elemente des Suchraums per Genotype-Phenotype-Mapping auf Elemente des Problemraums abgebildet.
Beziehungen zwischen Such- und Problemraum
Redundanz
Wenn mehr mögliche Genotypen als Phänotypen existieren, nennt man die genetische Repräsentation des EA redundant. In der Natur spricht man vom degenerierten genetischen Code. Bei einer redundanten Repräsentation sind neutrale Mutationen möglich, dabei handelt es sich um Mutationen, die den Genotyp verändern, die sich dabei aber nicht auf den Phänotyp auswirken. In der Biologie besagt die Neutrale Theorie der molekularen Evolution, dass dieser Effekt eine dominierende Rolle in der natürlichen Evolution spielt. Forschungsergebnisse im Bereich der evolutionären Algorithmen legen wiederum nahe, dass neutrale Mutationen die Funktionsfähigkeit von EA insofern verbessern können[1], als Populationen, die zu einem lokalen Optimum konvergiert sind, durch genetische Drift eine Möglichkeit besitzen, diesem lokalen Optimum zu entkommen.
Lokalität
Die Lokalität einer genetischen Repräsentation entspricht dem Maß, zu dem Abstände im Suchraum nach dem Genotype-Phenotype-Mapping im Problemraum erhalten bleiben. Das heißt, eine hohe Lokalität hat eine Repräsentation genau dann, wenn Nachbarn im Suchraum auch Nachbarn im Problemraum sind. Damit erfolgreiche Schemata durch das Genotype-Phenotype-Mapping nach einer geringfügigen Mutation nicht zerstört werden, muss die Lokalität einer Repräsentation hoch sein.
Skalierung
Beim Genotype-Phenotype-Mapping können die Elemente des Genotyps verschieden skaliert (gewichtet) werden. Der einfachste Fall ist die uniforme Skalierung: Alle Elemente des Genotyps sind im Phänotyp gleich gewichtet. Eine häufige Skalierung ist die exponentielle. Werden ganze Zahlen binär codiert, haben die einzelnen Stellen der entstandenen binären Zahl exponentiell verschiedene Gewichtungen bei der Repräsentation des Phänotyps.
- Beispiel: Die Zahl 90 wird binär (also zur Basis zwei) als 1011010 geschrieben. Verändert man nun eine der vorderen Stellen in der binären Schreibweise, hat dies deutlich größere Auswirkungen auf die codierte Zahl als etwaige Veränderungen an den hinteren Stellen (der Selektionsdruck wirkt an den vorderen Stellen exponentiell stärker).
Aus diesem Grund tritt bei exponentieller Skalierung der Effekt auf, dass die „hinteren“ Stellen im Genotyp zufällig fixiert werden, bevor die Population nahe genug am Optimum angelangt ist, um diese Feinheiten anzupassen.
Beispiel eines Genotyp-Phänotyp-Mappings
Bei kombinatorischen Aufgaben ist in der Regel eine umfangreiche Abbildung des Genoms auf den Phänotyp als Element des Problemraums erforderlich. Ein Phänotyp besteht je nach Aufgabenstellung aus einer oder mehreren Belegungsmatrizen, die die zeitliche Belegung einer Ressourcenart darstellen. Eine Belegungsmatrix besteht aus Ressourcen und Zeiteinheiten, wobei eine obere Abschätzung der benötigten Zeit darstellt. Der Inhalt eines Matrixelements ist die Kennung (meist ein Index in einer Tabelle) derjenigen Schedulingoperation, die die Ressourcenbelegung veranlasst hat. Dort sind meist weitere Daten hinterlegt, wie beispielsweise die erforderliche Dauer der Belegung. Was unter einer Schedulingoperation genau zu verstehen ist, hängt von der Aufgabenstellung ab. Dazu zwei Beispiele: Bei der Produktionsplanung (Job-Shop-Scheduling) sind es einzelne Arbeitsschritte, bei der Schulstundenplanung sind es Unterrichtsstunden einer Klasse, wobei hier mindestens 2 Ressourcen zu belegen sind: ein geeigneter Raum und eine geeignete Lehrkraft, der dann aber auch alle Unterrichtsstunden des betreffenden Faches zuzuordnen sind (zusätzliche Restriktion). Aus den Belegungsmatrizen können dann eine Reihe von Kennziffern für die Bewertung des Schedules und damit zur Fitnessermittlung abgelesen werden: Beispielsweise die Fertigstellungszeit eines Auftrags, die gesamte Bearbeitungszeit aller Aufträge, die Auslastung der Ressourcen oder die Freistunden von Schulklassen oder Lehrkräften.


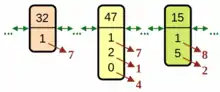
Die Erstellung einer Belegungsmatrix soll anhand des Schedulingbeispiels erläutert werden, das bereits bei der Beschreibung eines Genoms für komplexe Gene Verwendung gefunden hat. Das linke Bild zeigt noch einmal den dort gezeigten Chromosomausschnitt, der auf den im Beispiel definierten Gentypen beruht. Zur leichteren Beschreibung sind die Gene hier unterschiedlich eingefärbt und die braun gekennzeichneten Indizes entsprechen den Indizes der zu verplanenden Ressourcen, die durch die Genparameter aus der Menge der für den Teiljob geeigneten Ressourcen ausgewählt wurden. Der erste Genparameter gibt dabei die dem Teiljob zugeordnete Hardware an und der zweite die zu verwendende Software, sofern diese lizenzrechtlichen Mengenbegrenzungen unterliegt. Mit Hilfe des dritten Parameters kann dem Teiljob bei Bedarf zusätzliches Equipment zugeordnet werden. Jedes Gen beschreibt eine Schedulingoperation, wobei der Gentypcode dem zu verplanenden Teiljob der Workflows entspricht.
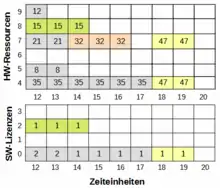
Zur Verwaltung der zu verplanenden Ressourcen mögen zwei Belegungsmatrizen dienen, eine für Rechnerhardware und zusätzliches Equipment und eine für die Software. Die Unterscheidung reflektiert den Umstand, dass im ersten Fall eine Ressource nur einmal belegt werden kann und es für die Auswertung wichtig ist, zu vermerken, durch welchen Teiljob. Bei der Software ist hingegen lediglich von Bedeutung, dass das Limit gleichzeitiger Verwendung nicht überschritten wird. Ausschnitte beider Matrizen sind im rechten Bild mit einer teilweisen Belegung durch bereits abgearbeitete Gene (grau) dargestellt. Dabei wird die SW 0 durch die Teiljobs 8 und 35 verwendet, was zu den unterschiedlichen Einträgen führt. Zuerst wird der Teiljob 32 verplant. Ihm hat der Genparameter die Ressource 7 zugeteilt, die er ab Zeiteinheit (ZE) 14 für drei ZE belegt. Danach wird das Gen für den Teiljob 47 abgearbeitet, der wegen der Belegung der Equipmentressource 4 erst ab ZE 18 starten kann. Daher entsteht für die ebenfalls belegte Hardwareressource 7 eine Lücke von einer ZE. Schließlich belegt Teiljob 15 die Hardwareressource 8 und die SW 2. Nach Abarbeitung des Chromosoms enthalten die Belegungsmatrizen den zugehörigen Phänotyp.
Das Beispiel zeigt deutlich, dass die Genotyp-Phänotyp-Abbildung recht aufwändig sein kann und phänotypische Eigenschaften nicht unbedingt direkt aus den Allelwerten des Genoms ablesbar sind. So steht beispielsweise das Gen von Teiljob 15 zwar hinter dem von Teiljob 47, aber der zugehörige Job wird im Beispiel trotzdem früher ausgeführt. Als weiteres Beispiel für komplexe Genotyp-Phänotyp-Abbildungen können die meisten simulationsbasierten Aufgabenstellungen angesehen werden, bei denen das Genom ein mehr oder weniger komplexes Simulationsmodell konfiguriert.
Bei der hier vorgestellten beispielhaften Interpretation dreier Gene eines Chromosoms wurde nicht berücksichtigt, dass die Teiljobs als Workflows organisiert sind und es demzufolge Reihenfolgerestriktionen gibt. Deren Beachtung kann durch eine entsprechende Erweiterung der Bewertung oder besser durch geeignete Reparaturmaßnahmen umgesetzt werden.
Einzelnachweise
- Edgar Galván-López, Stephen Dignum and Riccardo Poli: The Effects of Constant Neutrality on Performance and Problem Hardness in GP. In: Genetic Programming: 11th European Conference, EuroGP 2008, Naples, Italy, March 2008, Proceedings . Springer-Verlag, S. 313.
Literatur
- Franz Rothlauf: Representations for Genetic and Evolutionary Algorithms. Springer-Verlag, Berlin Heidelberg, ISBN 3-540-25059-X.