Earley-Algorithmus
Der Earley-Algorithmus oder Earley-Parser ist in der Informatik ein Algorithmus, der entscheidet, ob ein Wort von einer kontextfreien Grammatik erzeugt werden kann. Er wurde 1970 von Jay Earley entwickelt. Er ähnelt dem Cocke-Younger-Kasami-Algorithmus und löst wie dieser das Wortproblem der kontextfreien Sprachen. Er verwendet die Methode der dynamischen Programmierung.
Verwendung
Eine Aufgabe eines Compilers oder Parsers ist es, zu überprüfen, ob der eingegebene Quelltext den Regeln der entsprechenden Grammatik folgt, also der Syntax der Programmiersprache entspricht. Dies entspricht dem Lösen des Wortproblems. Da die meisten Programmiersprachen kontextsensitiv sind, werden dabei bestimmte Bedingungen zunächst ignoriert. Dadurch kann man erreichen, dass nur das wesentlich einfachere (nicht NP-vollständige) Wortproblem der kontextfreien Sprachen gelöst werden muss. Die kontextsensitiven Nebenbedingungen, wie etwa die Vollständigkeit der Variablendeklarationen, müssen dann mit einem anderen Algorithmus geprüft werden. So wird der erste Schritt der Syntaxprüfung auf das Wortproblem der kontextfreien Sprachen zurückgeführt. Diese wird vom Earley-Algorithmus und auch vom CYK-Algorithmus mit -Zeitaufwand erreicht, bei eindeutigen Grammatiken mit und in manchen speziellen Grammatiken mit . Beide sind optimal, um das Problem für eine allgemeine kontextfreie Sprache zu lösen. Der Earley-Algorithmus hat jedoch den Vorteil, dass keine Umwandlung der Grammatik in Chomsky-Normalform nötig ist. Nachteil ist die Einschränkung auf Epsilon-freie Grammatiken. Epsilon-Regeln können jedoch immer durch Umformung der Grammatik eliminiert werden.



In der Praxis versucht man meist, den relativ hohen Rechenaufwand der beiden Algorithmen zu vermeiden oder zu reduzieren. Man optimiert dabei den Compiler oder Parser speziell an die verwendete Programmiersprache und kann so oft einen geringeren Berechnungsaufwand erreichen. Besonders große Verbesserungen können dabei erreicht werden, wenn man die Syntax der Programmiersprache so weit einschränkt, dass sie LR1- oder sogar LL1-Eigenschaften hat. Dies wird bei der Entwicklung neuerer Programmiersprachen berücksichtigt. Für solche Programmiersprachen existieren Algorithmen, die in der Praxis schneller sind und weniger Speicher benötigen als der Earley-Parser. Für generelle kontextfreie Grammatiken sind der Earley-Parser und verwandte Algorithmen dagegen anderen überlegen.
Algorithmus
Der Algorithmus benötigt als Eingabe eine kontextfreie Grammatik und ein Wort über demselben Alphabet. Er entscheidet dann, ob die Grammatik das Wort erzeugen kann. Dabei geht er nicht wie der CYK-Algorithmus rückwärts wieder zum Startsymbol der Grammatik, sondern versucht das Wort zeichenweise zu erzeugen. In jedem Berechnungsschritt versucht er also, ein Zeichen des Wortes weiter zu kommen, bis das ganze Wort erzeugt ist. In einem solchen Fall ist das Wort von der Grammatik erzeugbar. Falls das Wort nicht erzeugbar (also nicht in der Sprache enthalten) ist, bricht der Algorithmus ab, da er an einem Zeichen ankommt, das er nicht vorhersagen kann. Bei der Eingabe eines Wortes verwendet der Algorithmus die Zustandsmengen . Ein Zustand (oder Earley-Zustand, engl. Earley item, auch dottet rule) des Algorithmus ist dabei eine Produktion, deren rechte Seite durch einen Teilungspunkt zerlegt ist. Alle Zeichen vor diesem Punkt gelten als schon überprüft. Ein solcher Zustand ist in einer Zustandsmenge enthalten und durch einen zusätzlichen Zähler gekennzeichnet. Dieser bestimmt, aus welcher Menge der Zustand ursprünglich stammt, damit der Algorithmus später mit Rekonstruktionschritten schnell einen Syntaxbaum erzeugen kann.






Am Anfang wird gesetzt. Dabei ist das Startsymbol der Grammatik. Der Algorithmus läuft nun Zeichen für Zeichen und wendet im ten Schritt immer die drei folgenden Regeln an, solange bis keine weiteren Zustände mehr angefügt werden können. Dabei ist zu beachten, dass Änderungen der Zustandsmenge auch vorherige Regeln erneut zur Anwendung bringen können. Zum Beispiel muss auf Zustände, die durch den completer hinzukommen, wieder der predictor aufgerufen werden.


| Voraussage (P) (engl. predictor) |
Falls in enthalten ist, füge für jede Regel der Grammatik den Zustand zu hinzu. |




| Überprüfung (S) (engl. scanner) |
Falls und , füge zu hinzu. |




| Vervollständigung (C) (engl. completer) |
Falls ein finaler Zustand existiert, füge für alle Zustände einen Zustand zu hinzu. |



Man nennt die drei Schritte auch prädiktive Erweiterung, lexikalische Konsumption und Konstituentenvervollständigung. In der Definition bedeuten Kleinbuchstaben terminierte Symbole (auch lexikalische Kategoriensymbole, engl. terminals), Großbuchstaben nichtterminierte Symbole (auch komplexe syntaktische Kategoriensymbole, engl. non-terminals) und griechische Buchstaben die gesamte rechte Seite einer Regel, bestehend aus verschiedenen Symbolen.
Genau dann, wenn am Ende in der Zustandsmenge enthalten ist, kann die Grammatik das Wort erzeugen.


Im Anschluss müssen die einzelnen Zustände durch einen geeigneten rekursiven Suchalgorithmus (engl. walker) wieder miteinander verknüpft werden, um den Syntaxbaum zu erzeugen.
Beispiel: einfacher mathematischer Ausdruck
Die folgende Grammatik (Anwendungsbeispiel aus [1])
|
|
|
|











beschreibt einfache mathematische Ausdrücke. Die Symbole stehen hier für start (), expression (), term (), factor () und number (, Platzhalter für Zahlen. Hier könnten weitere Regeln für den genauen Aufbau von Zahlen eingefügt werden). Als Beispiel soll der Ausdruck erkannt werden. Die nach Ablauf des Earley-Algorithmus im Speicher befindlichen Zustände sind in den Tabellen bis







| ||||||||||||||||||||||||||||||||||||||||||||












| ||||||||||||||||||||||||||||||||










| ||||||||||||||||||||||||||||||||



| ||||||||||||||||||||||||||||||||


gezeigt. Sie wurden durch mehrfache Anwendung der drei Schritte Voraussage (P), Überprüfung (S) und Vervollständigung (C) erzeugt, wie gekennzeichnet. Rot markiert sind die finalen Zustände, deren Punkt das Ende der Regel erreicht hat. Bis zu dieser Stelle entspricht also der Ausdruck einer gegebenen Regel. Jedoch nur wenn, wie in diesem Beispiel, in der letzten Zustandsmenge der finale Zustand der Startregel enthalten ist, wurde der gesamte Ausdruck erfolgreich erkannt und wird folglich durch die Grammatik erzeugt. Durch eine rekursive Suche kann nun, ausgehend von diesem letzten Zustand, der Pfad zurück zum Anfang zurückverfolgt und ein Syntaxbaum erzeugt werden.
Als gesuchter Syntaxbaum zu ergibt sich:
| → | ||||
| → | + | |||
| ↓ | → | |||
| ↓ | → | |||
|
→ |
||||
| → | ||||
| → |

Konstruktion des Syntaxbaums
Für die Berechnung des Syntax-Baumes schlug J. Earley in seiner Originalarbeit 1970 eine Rückverfolgung der Zustände vor, indem jeder Zustand einen Zeiger auf den Zustand speichert, der diesen erzeugt hat. Tomita[2] zeigte 1986, dass dieser Ansatz bei manchen mehrdeutigen Grammatiken zu falschen Syntaxbäumen führt. Um Syntaxbäume für generelle kontextfreie Grammatiken zu berechnen, muss eine rekursive Suche durchgeführt werden.
Dazu wird bei der finalen Startregel begonnen, die sich in der letzten Zustandsmenge befindet. Mit einer rekursiven Suche werden die Zustandsmengen und der Eingabe-String rückwärts durchlaufen. Dies kann wiederum mit einer Art Rückwärts-Scanner, Rückwärts-Predictor und Rückwärts-Completer realisiert werden, solange bis die anfängliche Startregel reproduziert wurde. Der Pfad zurück zum Anfang gibt den gesuchten Syntaxbaum wieder. Bei mehrdeutigen Situationen müssen rekursiv alle Möglichkeiten durchlaufen werden. Wenn bei einer mehrdeutigen Grammatik mehrere korrekte Syntaxbäume berechnet werden sollen, wird der gefundene Zustand gespeichert und die Rekursion solange fortgesetzt, bis in allen Rekursionsebenen alle Mehrdeutigkeiten abgearbeitet wurden.
Im Folgenden wird ein Algorithmus beschrieben, der nur die finalen Zustände und den Eingabe-String für die Rekursion benötigt. Nichtterminierte Zustände können vorher gelöscht werden. Es handelt sich um eine Modifikation des im Lehrbuch von D. Grune[3] beschriebenen Algorithmus, der den Eingabe-String bei der Rekursion nicht benötigt, stattdessen auch alle nichtterminierten Zustände. Beide Algorithmen sollten prinzipiell äquivalent sein.
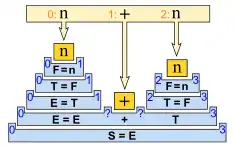
In der Abbildung entspricht die rekursive Suche einer Wanderung von rechts nach links über den Stapel aus verschachtelten Regeln. Die oberste Rekursionsebene der Suche entspricht in der Abbildung dem rechten Ende der unteren Startregel und die unterste Rekursionsebene dem linken Ende. Die Rekursionsebenen der Suche stehen also senkrecht im Bild. Der Punkt steht zunächst in allen Zuständen ganz rechts am Ende und wird während der Baumkonstruktion wieder an den Anfang zurück geschoben. Wenn der Punkt bei allen Zuständen, die Teil des Baumes sind, am Anfang steht, ist ein vollständiger Baum gefunden worden. Jeder Schritt über den Stapel hat drei Fälle:
- Rückwärts-Predictor (Stufe nach oben)
- Dieser Fall tritt ein, wenn ein nichtterminiertes Symbol vor dem Punkt steht. Die noch leere Vertiefung wird mit einem passenden Zustand befüllt, der dem Symbol vor dem Punkt entspricht. Ein Zustand darf nur dann eingefügt werden, wenn zwischen den Startpositionen entweder keine Lücke verbleibt oder bei dazwischenliegenden Symbolen mindestens so viele Stellen frei bleiben, wie Symbole vorhanden sind. Andernfalls können inkorrekte Bäume entstehen. Stehen mehrere Zustände zur Auswahl, muss später zu dieser Stelle zurückgegangen und die nächste Alternative durchlaufen werden. Wurde erfolgreich ein neuer Zustand platziert, kann eine Stufe weiter nach oben gegangen werden.
- Rückwärts-Scanner (Schritt nach links)
- Dieser Fall tritt ein, wenn ein terminiertes Symbol vor dem Punkt steht. Die Übereinstimmung mit der Eingabe muss erneut geprüft werden. Bei Übereinstimmung wird der Punkt des Zustandes wieder um eins nach links geschoben und in der Abbildung wird ein Schritt nach links gegangen.
- Rückwärts-Completer (Stufe nach unten)
- Dieser Fall tritt ein, wenn der Punkt am Anfang einer Regel angekommen ist. In diesem Fall geht es nach links eine Stufe hinab. In dem Zustand in dem man ankommt, wird der Punkt um eins zurück nach links geschoben.
Der Algorithmus kann unterwegs hängen bleiben, wenn der Rückwärts-Scanner einen Unterschied feststellt, oder der Rückwärts-Predictor keine Alternative mehr hat. Dann muss der Weg zum vorherigen Rückwärts-Predictor zurückgegangen und dort die nächste Alternative versucht werden. Gelangt man schließlich nach links an den Anfang des Stapels, wurde ein möglicher Syntaxbaum gefunden. Um die weiteren Bäume einer mehrdeutigen Grammatik zu finden, wird beim letzten Rückwärts-Predictor weitergemacht und dort die Suche bis zur nächsten vollständigen Alternative fortgesetzt.
Pseudocode
Der folgende Pseudocode beschreibt den gesamten Ablauf des Algorithmus:
Gegeben seien die zu parsenden Symbole s1...sN (Q0,...,QN) = ParseText(s1...sN) Falls die finale Startregel "S ->...*" in QN enthalten ist: i = N j = 0 b = Liste von Earley-Zuständen mit als einzigem Element der finalen Startregel BaumRekursion(i,j,b,(Q0,...,QN)) Sonst: gebe Syntaxfehler aus
Funktion ParseText(s1...sN):
Lege leere Zustandsmengen Qi mit i=0..N an
Füge die Startregel "S ->*..." zu Q0 dazu
Für i=0..N:
Füge Early-Zustände gemäß den drei Regeln predictor, scanner und completer
zu Qi hinzu, solange bis keine mehr hinzugefügt werden können
gebe Zustandsmengen (Q0,...,QN) zurück
Funktion BaumRekursion(i,j,b,(Q0,...,QN)): //i: Index der aktuellen Zustandsmenge Qi //j: Index des aktuellen Zustandes bj im Baum b Solange i > 0: //Rückwärts-Predictor Falls im Zustand bj vor dem Punkt ein Nonterminal steht: Wj = Wert des Nonterminals vor dem Punkt des Zustandes bj kj = Startindex des Zustandes bj pj = Punktposition des Zustandes bj (0 entspricht dem Anfang) Für alle finalen Zustände z in Qi mit Wertigkeit W, Startindex k und Punktposition p, für die gilt W = Wj und ((pj-1 = 0 und k = kj) oder (pj-1 > 0 und k-kj >= pj-1)): Hänge Kopie von z hinten an b an (alternativ: füge z nach bj ein) BaumRekursion(i,j+1,b,(Q0,...,QN)) Lösche das hinterste Element von b (alternativ: lösche Element bj+1) Beende den Funktionsaufruf (return) //Rückwärts-Scanner Falls im Zustand bj vor dem Punkt ein Terminal steht: Falls das Terminal vor dem Punkt gleich si ist: Setze Punkt von bj um eins zurück i = i-1 //Rückwärts-Completer Falls der Punkt von bj am Anfang steht: j = j-1 Setze Punkt von bj um eins zurück Falls bj die Startregel ist: Gebe gefundenen Syntax-Baum b aus
//Ausgabe bei der oben gezeigten Grammatik und dem Beispiel n+n
b =
S -> *E , 0
E -> *E+T , 0
E -> *T , 0
T -> *F , 0
F -> *n , 0
T -> *F , 2
F -> *n , 2
Auswertung des Syntaxbaumes
Um den mathematischen Ausdruck der gezeigten Beispiel-Grammatik auszuwerten, kann mithilfe eines Stacks direkt eine Handlungsvorschrift für die Berechnung erzeugt werden. Dazu wird die Reihenfolge der ermittelten Liste von Zuständen umgekehrt (oder rückwärts durchlaufen) und alle nicht für die Berechnung relevanten Regeln gelöscht oder ignoriert. Für jeden Schritt wird die entsprechende Zahl von Eingangswerten der Operation aus dem Stack geholt bzw. das Ergebnis der Operation in den Stack zurückgeschoben. Für das obige Beispiel ergibt sich:
F -> *n , 2: Schiebe n in den Stack
T -> *F , 2
F -> *n , 0: Schiebe n in den Stack
T -> *F , 0
E -> *T , 0
E -> *E+T , 0: Hole zwei Werte aus dem Stack, addiere
sie und schiebe das Ergebnis in den Stack
S -> *E , 0: Hole Wert aus dem Stack und gebe ihn aus
Auf diese Weise kann ein beliebig komplexer und verschachtelter mathematischer Ausdruck geparst und ausgewertet werden.
Literatur
- Jay Earley: An efficient context-free parsing algorithm. In: Communications of the Association for Computing Machinery. Band 13, Nr. 2, 1970, S. 94–102 (ccl.pku.edu.cn [PDF; 902 kB]).
- John Aycock, R. Nigel Horspool: Practical Earley Parsing. In: The Computer Journal. Band 45, Nr. 6, 2002, S. 620–630 (cs.uvic.ca [PDF; 162 kB]).
- Dick Grune, Ceriel J. H. Jacobs: Parsing Techniques. A Practical Guide. 1. Auflage. Ellis Horwood, New York 1990, ISBN 0-13-651431-6, S. 149–163 (ftp.cs.vu.nl [PDF; 1,9 MB]).
Einzelnachweise
- J. Aycock, N. Horspool: Directly-Executable Earley Parsing. In: Lecture Notes in Computer Science. 2027, 2001, S. 229–243, doi:10.1007/3-540-45306-7 (rsdn.ru PDF).
- Masaru Tomita, Efficient parsing for natural language, Kluwer Academic Publishers, Boston, p. 201, 1986.
- Dick Grune, Ceriel J. H. Jacobs: Parsing Techniques. A Practical Guide. 1. Auflage. Ellis Horwood, New York 1990, ISBN 0-13-651431-6, Kapitel 7.2.1.2, S. 153–154 (ftp.cs.vu.nl [PDF; 1,9 MB]).