Captcha
Ein Captcha ['kæptʃə] (der oder das, auch CAPTCHA; engl. completely automated public Turing test to tell computers and humans apart „vollautomatischer öffentlicher Turing-Test zur Unterscheidung von Computern und Menschen“) wird verwendet, um festzustellen, ob ein Mensch oder eine Maschine (Roboter[programm], kurz Bot) einbezogen ist. In der Regel dient dies zur Prüfung, von wem Eingaben in Internetformulare erfolgt sind, weil Roboter hier oft missbräuchlich eingesetzt werden. Captchas dienen also dem Schutz der Betreiber-Ressourcen, nicht dem Schutz des Benutzers oder dessen Daten. Im Unterschied zum klassischen Turing-Test, bei dem Menschen die Frage klären möchten, ob sie mit einem Mensch oder einer Maschine interagieren, dienen Captchas dazu, dass eine Maschine diese Frage klären soll.
Der Begriff Captcha wurde zum ersten Mal im Jahr 2000 von Luis von Ahn, Manuel Blum und Nicholas J. Hopper an der Carnegie Mellon University und von John Langford von IBM verwendet und ist ein Homophon des englischen Wortes capture (einfangen, erfassen).[1] Gelegentlich werden Verfahren zur Unterscheidung von Robotern und Menschen auch als HIP (engl. Human Interaction Proof) bezeichnet.



Erklärung
Captchas sind meist Challenge-Response-Tests, bei denen der Befragte eine Aufgabe (Challenge) lösen muss und das Ergebnis (Response) zurückschickt. In Captchas sind die gestellten Aufgaben idealerweise so, dass sie für Menschen einfach zu lösen sind, für Computer hingegen sehr schwierig. Beispiel dafür ist ein Text, der durch Bildfilter verzerrt wurde. Computer benötigen Mustererkennungs-Algorithmen, um derartige Bilder zu verarbeiten, die aufwendig zu programmieren sind und hohe Anforderung an die Hardware stellen. Neben grafischen Captchas werden mittlerweile auch Audio-Captchas oder Video-Captchas eingesetzt. Bei Asirra von Microsoft muss der Benutzer Tiere auf Fotos erkennen.
Captchas haben entsprechend ihrer Bezeichnung folgende Eigenschaften:
- Frage und Antwort werden bei jedem Zugangsversuch vollautomatisch per Zufallsgenerator und unter Einhaltung bestimmter Regeln generiert. Es wird also kein von Menschen vorgetragener Katalog mit Fragen und Antworten verwendet, da dessen begrenzter Wertebereich deutlich schneller zu Wiederholungen führen und damit einen Angriff erleichtern würde.
- Der verwendete Algorithmus ist veröffentlicht, damit Fachleute die Sicherheit des Systems beurteilen können. Captchas folgen damit Kerckhoffs’ Prinzip und verzichten auf Security through obscurity.
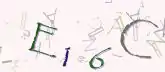
Nachteile
Es werden meist bildbasierte Rätsel verwendet; diese sind jedoch nicht barrierefrei, da sie schwer von sehbehinderten Menschen erkannt werden. Verschiedene Anbieter verwenden daher zusätzlich akustische Captchas, um die Zugänglichkeit zu erhöhen.[2] Taubblinde und Benutzer rein textbasierter Browser bleiben jedoch auch dadurch ausgeschlossen. Für Letztere würde sich jedoch eine weitere Methode eignen, welche textlich ein Wort abfragt, wie beispielsweise: „Wie nennt man ein motorbetriebenes, vierrädriges Fahrzeug“. Die Antwort wäre in diesem Fall „Auto“. Solche Frage-Antwortlisten müssten aber sehr schnell erweitert oder ständig umgeschrieben werden, da man einem Spambot solche Listen beibringen könnte. Außerdem stellen sie dann eine Barriere für Nicht-Muttersprachler oder intellektuell Benachteiligte dar.
Das Thema Barrierefreiheit im Zusammenhang mit Captchas wird auch in den Web Content Accessibility Guidelines (WCAG) der Web Accessibility Initiative (WAI) des World Wide Web Consortiums (W3C) thematisiert, wo unter anderem Minimalanforderungen für ein barrierearmes Captcha festgehalten sind.[3]
Grundsätzlich ist jedes schwierige Problem der Künstlichen Intelligenz geeignet, für ein Captcha verwendet zu werden. Die technische Eskalation bewirkt, dass die Captchas auch für den Menschen immer schwieriger zu lösen sein werden – bereits im Jahr 2010 zeigten Forscher der Stanford University in einer Studie auf, dass Captchas häufig selbst für menschliche Internetnutzer eine große Herausforderung sind[4] – und daher langfristig keine Lösung darstellen.[5]
Captchas sind unter Benutzerfreundlichkeits-Gesichtspunkten auch deshalb problematisch, da sie Hürden darstellen, die teilweise zu einem erheblichen Mehraufwand für den Nutzer bei der Zielerreichung führen. Zudem erschließt sich der Zweck eines Captchas vielen Betroffenen nicht intuitiv, was zu Irritationen über eine vermeintlich sinnlose Funktion führt.[6]
Google reCAPTCHA V3 nutzt dasselben Cookie, das auch von Chrome verwendet wird, um damit einen Teil seiner Risikoanalyse durchzuführen. Das führt dazu, dass Zugriffe ohne dieses Cookie mit einer höheren Wahrscheinlichkeit als gefährlich eingestuft werden. Auch ein VPN oder die Nutzung des Tor Browsers erhöhen den Risikowert.[7] Überdies ist nicht sicher, wozu die Daten verwendet werden. Google hat behauptet, dass die Informationen nur zur Risikoanalyse verwendet werden.[8]
Anwendungsgebiete
Mögliche Anwendungsgebiete sind Dienste, bei denen Bots den Dienst manipulieren oder missbrauchen können, wie etwa Online-Umfragen, Gästebücher, Registrieren von E-Mail-Adressen (von denen Spam gesendet werden kann) oder die Vermeidung von Spam durch Verschleierung der E-Mail-Adresse. Außerdem werden Captchas auch in Verbindung mit einer indizierten TAN-Liste zur Abwehr von Man-in-the-middle-Angriffen bei Online-Banking-Anwendungen verwendet.

Einen sekundären Nutzen aus der Lösung von Captchas erzielt Google Inc. mit dem Dienst reCAPTCHA für sein Projekt Google Bücher.[9] Nicht erkannte Textstellen beim Google-Bücher-Scan-Projekt werden als einzelne Wörter den Internet-Nutzern als Captcha angezeigt. Neben dem gescannten Wort wird noch ein echter Captcha angezeigt. Beide Wörter werden vom Nutzer aufgelöst. Das echte Captcha-Wort wird für die eigentliche Sicherheitsabfrage benutzt. Die Erkennung des gescannten Wortes wird gespeichert. Bei mehrfach gleicher Buchstabierung des gescannten Wortes bei unterschiedlichen Captcha-Vorgängen wird das Wort als richtig erkannt abgespeichert und wird so in das Google-Buch-Scan-Projekt übernommen.
Seit 2012 nutzt Google Fotos von Street View und lässt die Nutzer so die nicht erkannten Türnummern und andere Zeichen erkennen.
2014 beschloss Google Captcha für das Trainieren von KI zu nutzen.[10]
Umgehung von Captchas
Lösen durch Maschinen
Mit zunehmender Verbreitung von Captcha-geschützten Webseiten begann ein Wettlauf zwischen den Herstellern von Captchas und den Entwicklern maschineller Lösungen, so dass bald Programme entwickelt wurden, um den Schutz von Captchas zu umgehen. Viele mittlerweile ältere Implementierungen sind heute mit relativ geringem Aufwand auch für Maschinen lösbar.[11] Für verbreitete Implementierungen, wie die in der phpBB (Software zur Bereitstellung eines Internetforums) verwendete, existieren bereits Spambots, die die Captchas lesen und damit diesen Schutz umgehen können.[12] Ein weiteres Beispiel ist das Umgehen von Captchas durch Spammer beim automatischen Anlegen von Google-Mail-Konten mit einer Erkennungsquote von 20 bis 30 Prozent.[13] In der originalen Version der Captchas von SchülerVZ gelang es auch, diese zu umgehen und somit ein Massenkopieren von Profildaten in die Wege zu leiten. Ein automatisierter Bot, welcher lediglich aus einer einfachen Kombination eines Perl-Skripts und der Ajax-Programmierung bestand, konnte durchschnittlich 70 % der Captchas lösen.[14] Wie ein Versuch zeigt, existieren Algorithmen, die Captchas beispielsweise von Googles weit verbreitetem reCAPTCHA zu weit über 90 % richtig lösen, und somit eine höhere Erkennungsquote als Menschen aufweisen.[15]
Unwissentlich
Eine technisch einfache Möglichkeit, einen Captcha-Mechanismus zu umgehen, ist, eine Erkennungsaufgabe an unwissende Nutzer zu delegieren. Ein Spammer richtete beispielsweise einen Honeypot ein, um von den Besuchern Captchas lösen zu lassen, die vom Ziel des Spammers übernommen wurden.[16][17] 2007 enttarnten Trend Micro und Panda Security einen Trojaner, der das Lösen von Captchas als interaktives Striptease-Spiel tarnte.[18]
Wissentlich
Mittels kollaborativer Zusammenarbeit, auf sogenannten Captcha Exchange Servern, arbeiteten Ende der ersten Dekade des 21. Jahrhunderts Gruppen daran, sich gegenseitig Lösungen auf Vorrat anzulegen. Auf Grund technischer Entwicklungen und der Etablierung der Paid Services konnte sich die Idee kaum durchsetzen. In der dritten Welt gibt es einige Anbieter, die Captchas in Sweatshops lösen lassen.[19]
Weblinks
- Das namensgebende CAPTCHA-Projekt der Carnegie Mellon Universität (englisch)
- Reverse Engineering CAPTCHAs Abram Hindle, Michael W. Godfrey, Richard C. Holt, 24. August 2009 (englisch)
Einzelnachweise
- "CAPTCHA: Using Hard AI Problems for Security". Vorträge der Internationalen Konferenz über Theorie und Anwendung kryptografischer Techniken (EUROCRYPT 2003). Abgerufen: 16. Mai 2021
- Christian Radek: Barrierefreies E-Learning: Digitale Hürden überwinden, test.de vom 6. Mai 2014, abgerufen am 4. November 2014
- WCAG – Richtlinien des W3C für gut zugängliche Webinhalte. ionos.de/digitalguide. 13. April 2018. Abgerufen am 30. November 2018.
- How Good are Humans at Solving CAPTCHAs? A Large Scale Evaluation (englisch) web.stanford.edu. Abgerufen am 30. November 2018.
- Martin Ladstätter: CAPTCHAs im Spannungsfeld zwischen Accessibility und Sicherheit. 19. Februar 2008, abgerufen am 3. Januar 2022.
- Matthias Rauer: Captchas – Gratwanderung zwischen Sicherheit und Usability (updated). Abgerufen am 3. Januar 2022 (deutsch).
- Katharine Schwab: Google’s new reCAPTCHA has a dark side. 27. Juni 2019, abgerufen am 1. Mai 2021 (amerikanisches Englisch).
- Katharine Schwab: Google’s new reCAPTCHA has a dark side. 27. Juni 2019, abgerufen am 25. Juli 2021 (amerikanisches Englisch).
- Offizielle reCAPTCHA-Seite (englisch)
- James O'Malley 12 January 2018: Captcha if you can: how you’ve been training AI for years without realising it. Abgerufen am 1. Mai 2021 (englisch).
- PWNtcha – CAPTCHA-Decoder. In: Caca Labs (englisch).
- Bot registriert sich in mehreren tausend phpBB-Foren. In: Heise online, 20. März 2006.
- Spammer hebeln Googles Captchas aus. In: Heise online, 11. März 2008.
- Netzpolitik-Interview: Sicherheitslücken bei der VZ-Gruppe Von Markus Beckedahl, Netzpolitik, 20. Oktober 2009
- Algorithmus löst Captchas besser als Menschen Von Richard Meusers, SPIEGEL-ONLINE, 17. April 2014
- Cory Doctorow: Solving and creating captchas with free porn. In: boingboing.net, 27. Januar 2004 (englisch).
- Porno gegen Captchas. In: Heise online, 23. Juli 2008.
- Trojaner lässt Anwender Captchas lesen. In: Heise online, 29. Oktober 2007.
- Spammers Pay Others to Answer Security Tests By VIKAS BAJAJ, The New York Times, April 25, 2010