Apache Kafka
Apache Kafka ist eine freie Software der Apache Software Foundation, die insbesondere zur Verarbeitung von Datenströmen dient. Kafka ist dazu entwickelt, Datenströme zu speichern und zu verarbeiten, und stellt eine Schnittstelle zum Laden und Exportieren von Datenströmen zu Drittsystemen bereit. Die Kernarchitektur bildet ein verteiltes Transaktions-Log.
| Apache Kafka | |
|---|---|
 | |
| Basisdaten | |
| Maintainer | Apache Software Foundation |
| Entwickler | Apache Software Foundation, Linkedin |
| Erscheinungsjahr | 12. April 2014[1] |
| Aktuelle Version | 3.1.0[2] (21. Januar 2022) |
| Betriebssystem | Plattformunabhängig |
| Programmiersprache | Java[1], Scala[3] |
| Kategorie | Streamprozessor |
| Lizenz | Apache-Lizenz, Version 2.0, Apache-Lizenz |
| kafka.apache.org | |
Ursprünglich wurde Apache Kafka von LinkedIn entwickelt und ist seit 2012 Teil der Apache Software Foundation. Im Jahr 2014 gründeten die Entwickler das Unternehmen Confluent aus LinkedIn heraus, welches die Weiterentwicklung von Apache Kafka fokussiert. Apache Kafka ist ein verteiltes System, das skalierbar und fehlertolerant und somit für Big-Data-Anwendungen geeignet ist.
Funktionsweise
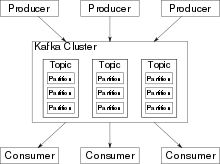
Den Kern des Systems bildet ein Rechnerverbund (Cluster), bestehend aus sogenannten Brokern. Broker speichern Schlüssel-Wert-Nachrichten zusammen mit einem Zeitstempel in Topics. Topics wiederum sind in Partitionen aufgeteilt, welche im Kafka-Cluster verteilt und repliziert werden. Innerhalb einer Partition werden die Nachrichten in der Reihenfolge gespeichert, in der sie geschrieben wurden. Lese- und Schreibzugriffe umgehen den Arbeitsspeicher durch die direkte Anbindung der Festplatten mit dem Netzwerkadapter (zero copy), so dass weniger Kopiervorgänge vor dem Schreiben oder Versenden von Nachrichten nötig sind.[4][5]
Anwendungen, die Daten in einen Kafka-Cluster schreiben, werden als Producer bezeichnet, Anwendungen, die Daten von dort lesen, als Consumer. Zur Datenstromverarbeitung kann Kafka Streams verwendet werden. Kafka Streams ist eine Java-Bibliothek, die Daten aus Kafka liest, verarbeitet und die Ergebnisse nach Kafka zurück schreibt. Kafka kann auch mit anderen Stream-Verarbeitungssystemen verwendet werden. Ab der Version 0.11.0.0 wird „transaktionales Schreiben“ unterstützt, so dass garantiert werden kann, dass Nachrichten genau ein einziges Mal verarbeitet werden, wenn eine Anwendung Kafka Streams verwendet (exactly-once processing).
Kafka unterstützt zwei Arten von Topics: „normal“ und „compacted“ Topics. Normale Topics garantieren, Nachrichten für einen konfigurierbaren Zeitraum vorzuhalten oder einen gewissen Speicherbedarf nicht zu überschreiten. Liegen Nachrichten vor, die älter sind als die konfigurierte „retention time“, oder ist das Speicherlimit einer Partition überschritten, kann Kafka alte Nachrichten löschen, um Festplattenspeicher freizugeben. Standardmäßig speichert Kafka Nachrichten für 7 Tage, aber es ist auch möglich, Nachrichten für immer zu speichern. Neben „normal“ Topics bietet Kafka auch „compacted“ Topics an, die keiner Zeit- oder Platzlimitierung unterliegen. Stattdessen werden neuere Nachrichten als Aktualisierung („updates“) alter Nachrichten mit dem gleichen Schlüssel interpretiert. Dabei wird garantiert, dass die neueste Nachricht pro Schlüssel nie gelöscht wird. Nutzer können Nachrichten jedoch explizit löschen, indem sie eine Spezialnachricht (sog. tombstone) mit null-Wert für den entsprechenden Schlüssel schreiben.
Kafka bietet vier Hauptschnittstellen an:
- Producer API
- Für Anwendungen, die Daten in einen Kafka-Cluster schreiben wollen.
- Consumer API
- Für Anwendungen, die Daten aus einem Kafka-Cluster lesen wollen.
- Connect API
- Import/Export-Schnittstelle zur Anbindung von Drittsystemen.
- Streams API
- Java-Bibliothek zur Datenstromverarbeitung.
Die Consumer- und Producer-Schnittstellen basieren auf dem Kafka-Nachrichtenprotokoll und können als Referenzimplementierung in Java angesehen werden. Das eigentliche Kafka-Nachrichtenprotokoll ist ein binäres Protokoll und erlaubt es damit, Consumer- und Producer-Clients in jeder beliebigen Programmiersprache zu entwickeln. Damit ist Kafka nicht an das JVM-Ökosystem gebunden. Eine Liste mit verfügbaren Nicht-Java-Clients wird im Apache Kafka Wiki gepflegt.[6]
Kafka Connect API
Kafka Connect (oder Connect API) bietet eine Schnittstelle zum Laden/Exportieren von Daten aus/in Drittsysteme. Es ist ab Version 0.9.0.0 verfügbar und baut auf der Consumer- und der Producer-API auf. Kafka Connect führt sogenannte Konnektoren („connectors“) aus, welche die eigentliche Kommunikation mit dem Drittsystem übernehmen. Dabei definiert die Connect-API die Programmierschnittstellen, die von einem Connector implementiert werden müssen. Es gibt bereits viele frei verfügbare und kommerzielle Konnektoren, die genutzt werden können. Apache Kafka liefert selbst keine produktreifen Konnektoren.
Kafka Streams API
Kafka Streams (oder Streams API) ist eine Java-Bibliothek zur Datenstromverarbeitung und ist ab Version 0.10.0.0 verfügbar. Die Bibliothek ermöglicht es, zustandsbehaftete Stromverarbeitungsprogramme zu entwickeln, die sowohl skalierbar, elastisch als auch fehlertolerant sind. Dafür bietet Kafka Streams eine eigene DSL an, die Operatoren zum Filtern, Mappen oder Gruppieren erhält. Des Weiteren werden Zeitfenster, Joins, und Tabellen unterstützt. Ergänzend zur DSL ist es auch möglich, eigene Operatoren in der Processor-API zu implementieren. Diese Operatoren können auch in der DSL genutzt werden. Zur Unterstützung zustandsbehafteter Operatoren wird RocksDB verwendet. Dies erlaubt es, Operatorzustände lokal vorzuhalten und Zustände, die größer als der verfügbare Hauptspeicher sind, als RocksDB-Daten auf die Festplatte auszulagern. Um den Anwendungszustand verlustsicher zu speichern, werden alle Zustandsänderungen zusätzlich in einem Kafka Topic protokolliert. Im Falle eines Ausfalls können alle Zustandsübergänge aus dem Topic ausgelesen werden, um den Zustand wiederherzustellen.
Kafka Operator für Kubernetes
Im August 2019 wurde ein Operator zum Aufbau einer Cloud-Native Kafka-Plattform mit Kubernetes veröffentlicht.[7] Dieser ermöglicht die Automatisierung der Bereitstellung von Pods der Komponenten des Kafka Ökosystems (ZooKeeper, Kafka Connect, KSQL, Rest Proxy), eine Überwachung von SLAs durch Confluent Control Center oder Prometheus, die elastische Skalierung von Kafka, sowie die Handhabung von Ausfällen und eine Automatisierung von Rolling Updates.[7]
Versions-Kompatibilität
Bis zur Version 0.9.0 sind Kafka-Broker mit älteren Client-Versionen rückwärtskompatibel. Ab Version 0.10.0.0 können Broker auch vorwärtskompatibel mit neuen Clients kommunizieren. Für die Streams-API beginnt diese Kompatibilität erst mit Version 0.10.1.0.
Literatur
- Ted Dunning, Ellen M. D. Friedman: Streaming Architecture. New Designs Using Apache Kafka and MapR. O’Reilly Verlag, Sebastopol 2016, ISBN 978-1-4919-5392-1.
- Neha Narkhede, Gwen Shapira, Todd Palino: Kafka: The Definitive Guide. Real-time data and stream processing at scale. O’Reilly Verlag, Sebastopol 2017, ISBN 978-1-4919-3616-0.
- William P. Bejeck Jr.: Kafka Streams in Action. Real-time apps and microservices with the Kafka Streams API. Manning, Shelter Island 2018, ISBN 978-1-61729-447-1.
Weblinks
Einzelnachweise
- projects.apache.org. (abgerufen am 8. April 2020).
- github.com.
- The apache-kafka Open Source Project on Open Hub: Languages Page. In: Open Hub. (abgerufen am 16. Dezember 2018).
- Alexander Neumann: Apache-Kafka-Entwickler erhalten 24 Millionen US-Dollar. In: heise Developer. Heise Medien GmbH & Co. KG, 9. Juli 2015, abgerufen am 21. Juli 2016.
- Thomas Joos: So analysieren Sie Logdateien mit Open Source Software. Realtime Analytics mit Apache Kafka. In: BigData Insider. Vogel Business Media GmbH & Co. KG, 24. August 2015, abgerufen am 21. Juli 2016.
- Kafka Clients support. In: Apache Kafka Wiki. Apache Software Foundation, 29. September 2020, abgerufen am 13. Januar 2021.
- Kafka-Operator für Kubernetes. Informatik Aktuell, 2. August 2019, abgerufen am 4. August 2019.