Scagnostics
Scagnostics (aus engl. Scatterplot diagnostics) bezeichnet eine Reihe von Maßzahlen, die bestimmte Eigenschaften einer Punktwolke in einem Streudiagramm kennzeichnen, die in der Praxis häufiger auftreten. Der Begriff wurde von John W. Tukey und Paul A. Tukey geprägt und später von Wilkison, Anand und Großmann ausgearbeitet.[1][2][3] Folgende neun Maßzahlen werden betrachtet:
- Für die Ausreisser in den Daten:
- Ausreisseranteil (outlying)
- Für die Dichte der Datenpunkte:
- Schiefe (skewed)
- Klumpigkeit (clumpy)
- Spärlichkeit (sparse)
- Gestreiftheit (striated)
- Für die Form der Punktwolke:
- Konvexität (convex)
- Dünnheit (skinny)
- Faserigkeit (stringy)
- Für einen Zusammenhang in den Daten:
- Monotonie (monotonic)
Tukeys Idee
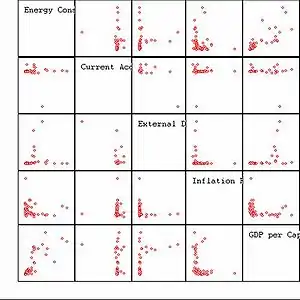
Eine Möglichkeit einen multivariaten Datensatz mit Variablen zu visualisieren ist eine Streudiagramm-Matrix; siehe das Beispiel rechts für fünf Variablen. Der Nachteil dieser Darstellung ist es, dass das Diagramm nur wenig Variablen enthalten darf sonst wird es unübersichtlich bzw. man kann kaum noch Datenstrukturen erkennen. Die Idee der Brüder Tukey war es, das Problem von Streudiagrammen auf eine kleinere Zahl von Streudiagrammen für die Maßzahlen zu reduzieren. Denn die Koeffizienten der Streudiagramme können dann wieder in einer Streudiagramm-Matrix dargestellt werden und mit Linking Methoden können die Streudiagramme der Daten herausgegriffen werden, die ungewöhnlich Werte der Koeffizienten zeigen.




Die Tukey-Brüder haben verschiedene Koeffizienten benutzt, z. B. Maße beruhend auf einer "geschälten" konvexen Hülle der Daten (Fläche, Durchmesser), auf geschlossenen Höhenlinien der geschätzten Dichtefunktion (Fläche, Durchmesser, Modalität, Konvexität), nicht-lineare principal curves usw. Damit wollten sie Besonderheiten der Punktwolken in Bezug auf der Dichte der Daten, Form, Richtung usw. aufdecken.
Ihre Maßzahlen wiesen jedoch ein paar Probleme auf:
- Einige der Maßzahlen hatten eine Berechnungskomplexität der Ordnung ( Anzahl der Beobachtungen im Datensatz), der sie für Datensätze mit vielen Beobachtungen ungeeignet macht.
- Implizit wurde angenommen, dass für jedes Paar von Variablen eine bivariate stetige Dichtefunktion existierte. In der Praxis sind jedoch viele Variablen diskret (oder klassiert).


Berechnung der Koeffizienten
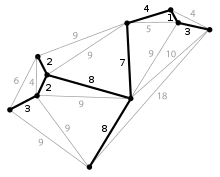
Um diesen Problemen zu umgehen haben Wilkinson, Anand und Grossman für die Berechnung der Maßzahlen graphentheoretische Ansätze gewählt:
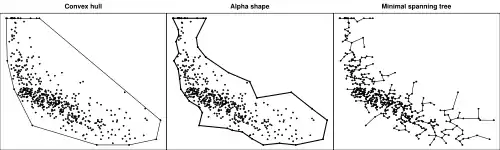
- Eine Delaunay-Triangulation der Daten und einen darauf aufbauend minimalen Spannbaum; siehe Grafik rechts. In einem minimalen Spannbaum werden alle Datenpunkte mit ihren Nachbarn so verbunden, dass ein Graph mit minimaler Länge entsteht, der alle Datenpunkte umfasst.
- Die konvexe Hülle der Datenpunkte, die sich als die äußeren Kanten in der Grafik rechts ergibt.
- Die Form der Datenpunkte. Sie ergibt sich als die Grenzen der Dreiecke der Delaunay-Triangulation, deren Umkreis einen Radius hat. Im Gegensatz zur konvexen Hülle kann die Form auch zu Löchern führen. ist hierbei das 90-%-Quantil der Kantenlängen des minimalen Spannbaums.


Da Ausreisser in den Daten die Maßzahlen stark beeinflussen können, wurden diese zum einen auf robusten Methoden basiert (wie auch schon bei den Tukeybrüdern) und zum anderen wurden sie bei der Triangulation ausgeschlossen. Des Weiteren wurden die Maßzahlen so gewählt, dass die Berechnungkomplexität nicht überschritt. Um die Berechnung weiter zu beschleunigen wurde noch Binning angewandt, d. h. nahe beieinanderliegende Datenpunkte wurden zusammengefasst.

Alle Maßzahlen liegen im Intervall von Null bis Eins. Um dies zu erreichen, werden in einem ersten Schritt alle Variablen des Datensatze auf das Intervall reskaliert:

- .

Mit den reskalierten Daten werden dann die folgenden Maßzahlen berechnet.
Ausreisseranteil
Man berechnet zunächst das 25-%-Quantil und das 75-%-Quantil der Kantenlängen im minimalen Spannbaum (MST). Kanten deren Länge größer als werden als lange Kanten gekennzeichnet.




Dies ist ein Maß für den Anteil der langen Kanten an allen Kanten im MST und

Schiefe
Man berechnet das 10-%-Quantil , das 50-%-Quantil und das 90-%-Quantil der Kantenlängen im MST.




Dies ist ein robustes Maß für die Schiefe der Verteilung der Kantenlängen im MST. Dies gibt eine Information über die relative Dichte der Datenpunkte.

Klumpigkeit
Eine schiefe Verteilung der Kantenlängen im MST heißt nicht unbedingt, dass die Daten in Teilgruppen zerfallen. Daher wird dafür ein Maß der Klumpigkeit definiert: Wird jeweils eine Kante aus dem MST entfernt, dann zerfällt der MST in zwei Teilgraphen. In dem kleineren der beiden Teilgraphen wird nun die längste Kante gesucht:


Die Maßzahl liegt nahe Eins, wenn z. B. eine (lange) Kante zwischen zwei Clustern entfernt wird. Innerhalb eines Cluster sind die Distanzen klein, so dass das Verhältnis nahe bei Null liegt und daher groß wird.


Spärlichkeit
Die Spärlichkeit ist definiert als das 90-%-Quantil der Kantenlängen des MST:


Gestreiftheit
Hierbei werden alle Kanten der Delaunay-Triangulation betrachtet. Haben zwei benachbarte Kanten einen Winkel von mehr als 138,5 Grad (genauer: ) dann werden sie als "gestreift" bezeichnet.



Konvexität
Um die Konvexität der Daten zu beurteilen wird die Fläche der Form mit der Fläche der konvexen Hülle verglichen:


Dünnheit
Um zu prüfen, wie „dünn“ die Datenpunkte verteilt sind wird die Form genutzt

Dies ist ein normiertes Maß. Wenn die Form ein Kreis ist, dann ergibt sich als Null.


Faserigkeit
Die Faserigkeit prüft, ob der MST aus einem durchgehenden Pfad besteht, d. h. keine Abzweigungen besitzt. Dafür wird der Durchmesser des MST als die Länge des längsten durchgehenden Pfades bestimmt.

Besitzt der MST keine Verzweigungen, dann ergibt sich ein Wert für von Eins.




Beispiel
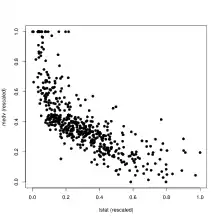
Die rechte Grafik zeigt bezirksweise den mittleren Hauspreis (medv) in Abhängigkeit vom Anteil der Unterschichtbevölkerung (lstat) der Boston Housing Daten. Folgende Scagnostics Maßzahlen wurden berechnet und die Ergebnisse mit den Beispieldatensätzen von oben verglichen.
| =0,1459 | Der Wert erreicht fast den maximale Wert der Beispieldatensätze. Dies weist auf einige Ausreißer in den Daten hin; tatsächlich gibt es große Abstände zwischen den Datenpunkten am rechten Rand. | |
| =0,7755 | Auch hier wird fast der maximale Wert der Beispieldatensätze erreicht. Man sieht deutlich in den Daten eine zentrale Region in der die Datenpunkte dichter sind und außerhalb weniger dicht. | |
| =0,0322 | Dieser Wert ist relativ klein. Die Daten zerfallen auch nicht in einzelne Cluster. | |
| =0,0353 | Der Wert liegt noch unterhalb des kleinsten Wertes der Beispieldatensätze. D. h. die Daten bedecken nur einen Teil der Gesamtfläche. | |
| =0,0463 | Der Wert liegt an der unteren Grenzen der Beispieldatensätze. Eine klare streifige Struktur ist daher nicht zu erkennen. | |
| =0,3501 | Der Wert liegt im Mittelfeld der Beispieldatensätze. Insbesondere bei nicht-linearen Zusammenhängen tritt dieser Wert in den Beispieldatensätzen auf. | |
| =0,5833 | Auch dieser Wert liegt im Mittelfeld der Beispieldatensätze. Dies weist auf eine Struktur hin, die einen Zusammenhang vermuten lässt zwischen diesen Variablen. | |
| =0,3557 | Dieser Wert liegt am unteren Rand der Beispieldatensätze. Eine glatte Struktur gibt es in den Daten nicht, d. h. der Datensatz enthält etwas Streuung. | |
| =0,7484 | Dieser Wert liegt am oberen Rand der Beispieldatensätze. Da es einen deutlichen Zusammenhang zwischen beiden Variablen ist das nicht überraschend. |






Zusammenfassend kann also gesagt werden: Dieses Streudiagramm enthält einen deutlichen nicht-linearen Zusammenhang mit vermutlich stärkerer Streuung. Die Daten zerfallen in eine zentralere dichte Region und eine weniger dichtere äußere Region, die einige Ausreißer enthält.
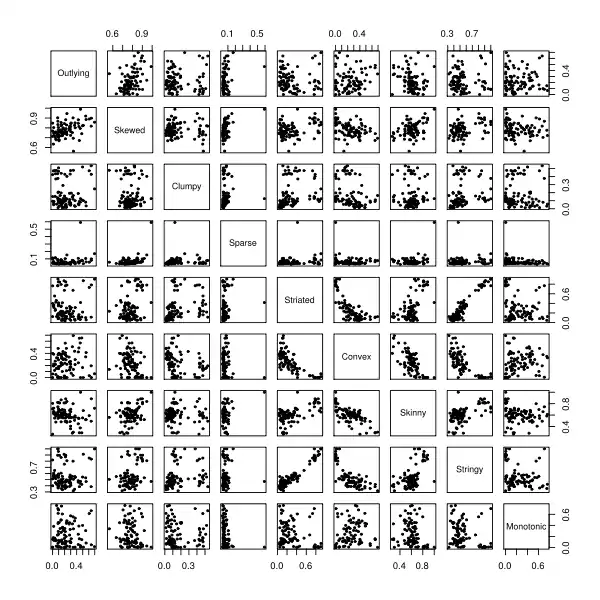
Die Boston Housing Daten bestehen aus 14 Variablen, daher ergeben sich 91 Streudiagramme, die man betrachten kann. In der folgenden Streudiagramm-Matrix sind die neun Maßzahlen für die 91 Streudiagramme dargestellt. Z. B. bei Sparse fällt ein extremer Wert auf. Dies ist das Streudiagramm der Variablen Charles-River Index mit zwei Merkmalsausprägungen (Bezirk grenzt an den Charles River oder nicht) und Index des Zugangs zu den radialen Autobahnen mit acht Merkmalsausprägungen. D. h. alle Beobachtungen im Streudiagramm dieser beiden Variablen müssen sich auf 16 Punkte konzentrieren!
Weblinks
- R package scagnostics
Einzelnachweise
- Leland Wilkinson, Anushka Anand, Robert Grossman: High-Dimensional Visual Analytics: Interactive Exploration Guided by Pairwise Views of Point Distributions. In: IEEE Transactions on Visualization and Computer Graphics. Band 12, Nr. 6, 2006, S. 1363–1372, doi:10.1109/TVCG.2006.94.
- J. W. Tukey, P.A. Tukey: Computer graphics and exploratory data analysis: An introduction. In: National Computer Graphics Association (Hrsg.): Proceedings of the Sixth Annual Conference and Exposition: Computer Graphics85. Band III. Fairfax, VA. 1985.
- Leland Wilkinson, Anushka Anand, Robert Grossman: Graph-Theoretic Scagnostics. In: Proceedings of the 2005 IEEE Symposium on Information Visualization. 2005, S. 157–164, doi:10.1109/INFOVIS.2005.14 (psu.edu [PDF; abgerufen am 6. Oktober 2012]).