Progressive Kompression
Progressive Kompression, auch kompakte Kompression oder solide Kompression (englisch solid compression), ist ein Verfahren bzw. ein Vorverarbeitungsschritt bei der Kompression mehrerer Dateien. Die Dateien werden dabei zu einem oder auch mehreren großen Blöcken zusammengefasst und dann dateiübergreifend komprimiert. Auf diese Weise erzielt man meist eine höhere Kompression, als wenn jede Datei einzeln komprimiert wird. Wie groß dieser Vorteil ist, hängt davon ab, wie ähnlich die Dateien sind.
Funktion
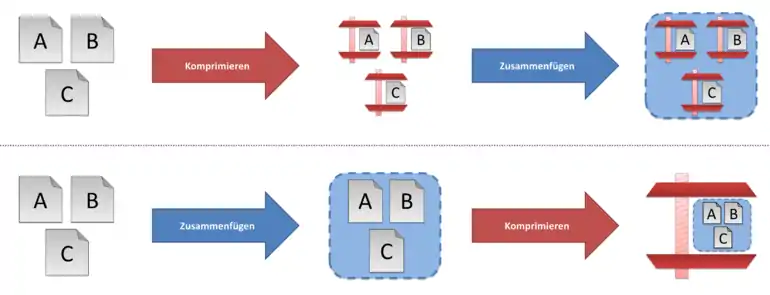
Solide Kompression kann immer dann eingesetzt werden, wenn mehrere Dateien in einem Archiv zusammengefasst werden. Kommt solide Kompression zum Einsatz, dann werden alle Dateien vor der eigentlichen Kompression zusammengefasst und dann als einzelner kontinuierlicher Datenstrom komprimiert. Andernfalls, d. h. ohne solide Kompression, werden die einzelnen Dateien zunächst unabhängig voneinander komprimiert und erst nach der eigentlichen Kompression zu einer Archivdatei zusammengefasst. Üblicherweise verbessert progressive Komprimierung die Kompressionsrate – besonders bei vielen kleineren und ähnlichen Dateien (wie etwa Logdateien). Dies ist darauf zurückzuführen, dass bei der soliden Kompression auch Redundanzen zwischen verschiedenen Dateien zur Datenreduktion ausgenutzt werden können, wohingegen ohne solide Kompression nur Redundanzen innerhalb der jeweiligen Datei ausgenutzt werden können.
Manche Archivierungsprogramme (z. B. RAR) sortieren die Dateien vorher nach Dateityp, um so die Kompressionsrate noch etwas mehr zu verbessern.[1]
Technische Erklärung
Moderne Packprogramme verwenden eine Kombination aus Wörterbuchkompression (z. B. LZ77) und Entropiekodierung (z. B. Huffman-Kodierung), wie dies u. a. beim Deflate-Algorithmus der Fall ist.
Ziel der Wörterbuchkompression ist es mehrfach vorkommende Byte-Folgen zu ersetzen, so dass diese nur einmal gespeichert werden müssen. Das dabei verwendete Wörterbuch (auch Lexikon) wird heute i. a. R. sukzessive während des Kompressions- bzw. Dekompressionsvorgangs aufgebaut (ausgehend von einem initialen, leeren Wörterbuch), damit das Wörterbuch nicht separat übertragen bzw. gespeichert werden muss. Übertragen werden ausschließlich Literale, also Byte-Folgen, die noch nicht im Wörterbuch enthalten sind, oder Referenzen auf bereits vorhandene Wörterbuch-Einträge. Alle übertragenen Literale werden sogleich dem Wörterbuch hinzugefügt – sowohl vom Kodierer als auch vom Dekodierer. Dies führt zu einer „Aufwärmphase“ am Beginn des Kompressionsvorganges, in der das Wörterbuch zunächst befüllt werden muss, bevor tatsächlich Daten durch Wörterbuch-Referenzen eingespart werden können (vgl. z. B. LZ77 und LZ78).
Ohne solide Kompression können nur Redundanzen innerhalb der jeweiligen Datei entfernt werden. Redundanzen zwischen mehreren Dateien bleiben unberücksichtigt, da bei jeder Datei wieder mit einem leeren Wörterbuch begonnen wird. Auch durch die jedes Mal neue „Aufwärmphase“ leidet die Kompression etwas. Bei der soliden Kompression hingegen kann durchgängig dasselbe Wörterbuch für alle Dateien verwendet werden. Dies ist insbesondere bei Dateien mit ähnlichem Inhalt von großem Vorteil. Bei kleinen Dateien ist dieser Vorteil umso stärker ausgeprägt, da hier die „Aufwärmphase“ einen größeren Anteil hat.
Die obigen Überlegungen gelten in ähnlicher Form auch für die adaptiven Kontextmodelle, die bei der Entropiekodierung verwendet werden (vgl. PPMD oder LZMA).
Nachteile
Da ein solides Archiv nur aus einem Datenstrom besteht, der fortlaufend komprimiert wurde, ist ein wahlfreier Zugriff auf einzelne Dateien nicht möglich. Das bedeutet, dass beim Entpacken einer bestimmten Datei erst alle Dateien, die sich im Archiv vor dieser Datei befinden, entpackt werden müssen. Dies geschieht meist nur im Arbeitsspeicher, da lediglich ein Teil der Daten später zur Dekompression der gewünschten Datei benötigt wird und der Rest wieder verworfen werden kann.[1] Bei einer Beschädigung des Archivs kann sich dadurch ein Fehler auch weiter über die betroffene Datei hinaus erstrecken. Wie weit, hängt von der Höhe der Kompressionsrate ab, kann aber bis hin zum Verlust aller Daten ab der Fehlerposition führen. Daher eignet es sich, jedes komprimierte Archiv mindestens doppelt zu speichern, damit Schäden durch Sektorenfehler durch Ergänzung in einem Byte-Editor behoben werden können.
Weitere Dateien können nur an das Ende des Archivs hinzugefügt werden.
Das Löschen von Dateien aus der Archivdatei ist nur möglich, indem der Datenstrom vollständig dekomprimiert wird, die zu löschenden Dateien entfernt werden und anschließend die Dateien wieder solide komprimiert werden.
Um nicht jedes Mal das komplette Archiv entpacken zu müssen, kann als Kompromisslösung auch die Länge zusammenhängend komprimierter Daten begrenzt und dadurch unabhängig komprimierte Blöcke erstellt werden.
Verwendung
Progressive Kompression wird unter anderem von den Archiv-Formaten 7z, RAR, ACE sowie ARC unterstützt.
In Unix-Umgebungen werden traditionell separate Werkzeuge zur Archivierung und zur Kompression verwendet (vgl. Unix-Philosophie). Üblicherweise werden zunächst alle Dateien mit dem Werkzeug tar zu einem (unkomprimierten) Archiv zusammengefasst, welches im Anschluss komprimiert werden kann. Zur Kompression kann z. B. gzip (ergibt .tar.gz), bzip2 (ergibt .tar.bz2) oder xz (ergibt .tar.xz) eingesetzt werden. Dieses Vorgehen entspricht einer progressiven Kompression.
Das verbreitete ZIP-Dateiformat hingegen unterstützt die progressive Archivierung nicht. Durch die Verwendung zweier geschachtelter ZIP-Archive kann jedoch eine progressive Kompression erreicht werden. Dazu fasst man zunächst alle Einzeldateien mit kompressionsloser ZIP-Archivierung zusammen. Anschließend komprimiert man diese ZIP-Datei mit der gewünschten Kompressionsstufe.
Einzelnachweise
- Archive file formats and archivers „Solid archives“ (Memento vom 27. April 2007 im Internet Archive) bei schmidt.devlib.org (englisch)