Objekterkennung
Der Begriff Objekterkennung beschreibt Verfahren zum Identifizieren bekannter Objekte innerhalb eines Objektraums mittels optischer, akustischer oder anderer physikalischer Erkennungsverfahren. So wird z. B. das Vorhandensein eines Objektes in einem digitalen Bild oder Videostream und dessen Position und Lage bestimmt.
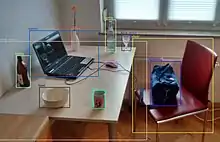
Anwendungen
Eine Objekterkennung ist zum Beispiel bei komplizierten Fertigungsprozessen notwendig. Dabei können sowohl optische als auch induktive, kapazitive oder auch magnetische Sensoren und Systeme eingesetzt werden. Oftmals wird hier die Übereinstimmung der Form eines Objektes mit einer Vorgabe ermittelt, oder die korrekte Lage desselben auf einem Fliessband geprüft.
In der abstrakten Bildverarbeitung dienen Objekterkennungsmethoden dazu, bestimmte Objekte bzw. Muster von anderen Objekten zu unterscheiden. Dazu muss das eigentliche Objekt zunächst mathematisch beschrieben werden. Oft genutzte Verfahren der Bildverarbeitung sind die Kantenerkennung, Transformationen sowie Größen- und Farberkennung. Je genauer die Beschreibung des Objektes möglich ist und je mehr auswertbare Informationen vorhanden sind, umso zuverlässiger arbeitet die Objekterkennung.
Etiketten, die es in roter oder blauer Ausführung gibt, können beispielsweise bereits durch einen einfachen Farbsensor unterschieden werden. Soll aber zudem noch erkannt werden, ob auf dem roten Etikett eine Schrift aufgebracht ist, so muss meist eine entsprechende Kamera eingesetzt werden.
In Fahrzeugen werden zunehmend kamerabasierte Fahrerassistenzsysteme eingesetzt, um beispielsweise Verkehrsschilder oder die Fahrspur automatisch zu erkennen.
Bei der Detektion von Verkehrszeichen wird nach kreisförmigen Objekten gesucht. Eine rote Umrandung deutet dann auf ein Verbotsschild hin. Alternativ kann auch nur mit Mustern bekannter Zeichen verglichen werden (Template-Matching).
Komplexere Formen der Objekterkennung kommen dann zum Einsatz, wenn sich drehende oder schnell bewegte Objekte in einem Bild verfolgt werden müssen. Dann kommen mathematische Korrelatoren zum Einsatz, die sich an das Objekt anpassen können, wie z. B. bei einem sich wegdrehenden Hubschrauber, dessen Position vor einem komplexen Hintergrund ermittelt werden muss. Mittels geeigneter Bildverarbeitungssysteme sind Positionsbestimmungen von Objekten unterhalb der Pixelauflösung der zugrunde liegenden Bilder möglich.
Pflanzenkrankheiten können mit Hilfe der App Plantix, die mit künstlichen neuronalen Netzen arbeitet, erkannt werden.[1]
Software
Auf Software basierende Methoden zur Objekterkennung fallen in der Regel entweder in Ansätze des maschinellen Lernens oder in Deep-Learning-basierte Ansätze. Für Ansätze des maschinellen Lernens ist es notwendig, zunächst Merkmale mit einer der folgenden Methoden zu definieren und dann eine Technik wie die Support Vector Machine (SVM) zur Klassifizierung zu verwenden.
Ansätze aus dem maschinellen Lernen:
- Viola-Jones-Methode, die auf Haar-Wavelets basiert
- Scale-invariant feature transform (SIFT) und Speeded Up Robust Features (SURF)
- Histogram of oriented gradients (HOG)
Auf der anderen Seite sind Deep-Learning-Techniken in der Lage, eine Objekterkennung durchzuführen, ohne händisch vorab bestimmte Merkmale definieren zu müssen. Diese Techniken basieren typischerweise auf einem Convolutional Neural Network (CNN). Ein solches künstliches neuronales Netz muss zuvor trainiert werden. Hierzu sind große Mengen an Bildern notwendig. Diese zum Training benutzten Bilder müssen zuvor in irgendeiner Form klassifiziert worden sein. Es muss also eine Information existieren, was auf dem Bild dargestellt ist. Hierfür existieren spezielle Datenbanken wie z. B. ImageNet oder der COCO-Datensatz[2].
Deep-Learning-Ansätze:[3]
- Region Proposals (R-CNN, Fast R-CNN, Faster R-CNN[4]) und darauf aufbauend Detectron[5].
- Single Shot MultiBox Detector (SSD)[6], mit einer einstufigen Detektionsstrategie.
- You Only Look Once (YOLO)[7][8], mit einer einstufigen Detektionsstrategie.
Eine einstufige Detektionsstrategie bedeutet, dass die zu analysierenden Bilder nur einmal gelesen werden müssen. Der Anfang 2020 wohl schnellste Ansatz ist das erst im selben Jahr veröffentlichte YOLOv5. Zu seiner Anwendung sind einfache Open-Source-Lösungen verfügbar[9]. Sie basieren auf folgendem Ansatz: Mit einer hohen Anzahl von Datensätzen aus der COCO-Datenbank wurde ein künstliches neuronales Netz aufwendig trainiert. Dieses fertig trainierte Netz ist als Datei verfügbar und kann dann mit Methoden aus dem "Deep Neural Network module (dnn)" der lokal installierten Software OpenCV benutzt werden, um Bilder oder Videosequenzen in Echtzeit zu untersuchen. In dem zu untersuchenden Bildmaterial werden dann die "eintrainierten" Objekte erkannt.
Siehe auch
Weblinks
- Objekterkennung (PDF; 1,01 MB)
- Kurs CS231n an der Stanford University. Lehrstoff im Bereich Computer Vision: Eigenen neuronalen Netze implementieren, trainieren und debuggen. Die Vorlesungsinhalte von 2017 sind online abrufbar. (englisch)
Einzelnachweise
- Die App Plantix erkennt kranke Pflanzen. Wired, 31. März 2017, abgerufen am 21. Januar 2019.
- COCO – Common Objects in Context. Abgerufen am 29. Januar 2019 (englisch).
- Adrian Rosebrock: YOLO object detection with OpenCV. In: PyImageSearch. 12. November 2018, abgerufen am 14. Januar 2019 (amerikanisches Englisch).
- Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. 4. Juni 2015, arxiv:1506.01497 [abs].
- Detectron. facebook research, abgerufen am 21. Januar 2019 (englisch).
- Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed: SSD: Single Shot MultiBox Detector. Band 9905, 2016, S. 21–37, doi:10.1007/978-3-319-46448-0_2, arxiv:1512.02325 [abs].
- Joseph Redmon, Ali Farhadi: YOLOv3: An Incremental Improvement. 8. April 2018, arxiv:1804.02767 [abs].
- Joseph Chet Redmon: YOLO: Real-Time Object Detection. Abgerufen am 14. Januar 2019.
- Jacob Solawetz: YOLOv5 New Version - Improvements And Evaluation. 29. Juni 2020, abgerufen am 23. September 2021 (englisch).