Normierte Programmierung
Die normierte Programmierung (NP) beschreibt eine standardisierte Ablaufsteuerung eines Datenverarbeitungsprogramms. Sie war in DIN 66220 genormt und wurde mit DIN 66260 in Richtung strukturierte Programmierung weiterentwickelt. Beide Ansätze unterstützten die modulare Programmierung.
Normierte Programmierung ist eine verallgemeinerte Programmablaufsteuerung, die die Teilaufgaben eines Stapelprogrammes wie Dateneingabe, Gruppenkontrolle, Verarbeitung / Ausgabe in ein einheitliches, logisch klares, funktionelles Schema gliedert. Für Programme mit solchen Aufgaben lässt sich dieses Schema unabhängig von der fachinhaltlichen Aufgabenstellung und „technologieneutral“ (z. B. in jeder imperativen/prozeduralen Programmiersprache) anwenden.
Historischer Rückblick
Zur Zeit der Entstehung der normierten Programmierung Ende der 1960er Jahre für die kommerzielle Datenverarbeitung gab es lediglich Stapelprogramme: sequentielle Dateien, in denen je nach Aufgabenstellung unterschiedliche 'Satzarten' gemischt/hintereinander auftraten, weil z. B. nur eine Magnetbandstation oder ein Lochkartenleser für die Eingabe verfügbar war. Ein Mischen im Programm war so nicht erforderlich und wäre bei Arbeitsspeichern von z. B. 64 KB inkl. Betriebssystem auch zu aufwändig gewesen. So las das Programm 'seine' Eingabedatei und verarbeitete einen Datensatz nach dem anderen. Über ein Datenfeld 'Satzart' wurden die Datenarten (Kunde, Bestellung …) inhaltlich unterschieden und über Ordnungsbegriffe einander zugeordnet. Das Programm 'lief' (mit GOTO) je nach Datenkonstellation zu bestimmten Stellen, zum Beispiel zu Rechenvorgängen, zum Drucken einer Listenzeile, um Daten nachzulesen und ebenfalls zu verarbeiten – und letztlich zum Programmende. Die Programme waren oft 'Spaghetticode', folgten kaum einheitlichen Strukturvorgaben und waren deshalb intransparent, fehleranfällig und änderungsunfreundlich.
Leistungsfähigere Rechner, neue Programmiersprachen, aber auch Fortschritte in den Methoden zur Softwareentwicklung führten sukzessive zu besseren Lösungen: Es entstanden Vorschläge für eine standardisierte Struktur von Stapelprogrammen. Darin war die gesamte Steuerung des Programms in eindeutig definierte 'Routinen' zergliedert, die die aufgabenspezifischen Verarbeitungsteile des Programms aufrufen – die 'Normierte Programmierung'.
Allerdings werden in der Praxis der (individuellen) Softwareentwicklung derart standardisierte Verfahren oft nicht angewendet – mit der Folge, dass das Erstellen des Programmcodes zur Programmsteuerung in vielen Fällen eine besondere Herausforderung bzw. 'Problemstellung' für die Entwickler blieb, die nicht selten hohen Entwicklungsaufwand verursacht und beim Softwaretest Fehler zutage fördert.
Zielsetzung
Laut einem kleinen Lehrbuch eines großen BUNCH-Computerherstellers von 1971 mit dem Titel Logik der Programmierung, Normierte Programmierung, mit dem damals angehende Programmierer und Systemanalytiker ausgebildet wurden, wurden „Vereinheitlichung und Standardisierung der Programmerstellung, Verkürzung der Programmierzeit, Ausschaltung möglicher Fehlerquellen und damit Verkürzung der Testzeit und Senkung der Kosten für die Programmierer“ als Ziele der normierten Programmierung bezeichnet. Dementsprechend sind diese Ziele dann von Bedeutung, wenn in einer Organisation mehrere/viele Entwickler Software mit Entwicklungswerkzeugen herstellen, in denen die Steuerungsfunktionen der Normierten Programmierung nicht als integrierter Bestandteil enthalten sind.
Die normierte Programmierung
Kernstück der normierten Programmierung ist die Programmablaufsteuerung. Die normierte Programmierung erzwingt die logische und funktionelle Ordnung eines Programms durch eine vereinheitlichte Programmablaufsteuerung, die unabhängig vom jeweiligen Programmierer ist. Da die Ablaufsteuerung explizit vom Programmierer festgelegt wird, lässt sich die Softwareentwicklung nach der normierten Programmierung dem Programmierparadigma der imperativen/prozeduralen Programmierung zuordnen.
Stapelprogramme haben dabei unabhängig von ihrer individuellen Aufgabenstellung immer dieselbe Struktur. Das heißt: Identische Bezeichnungen für die Verarbeitungsprozeduren; identische Steuerungslogik (die Blöcke B bis E sind nur auf die konkrete Aufgabenstellung wie Anzahl Dateien, Gruppenbegriffe … eingestellt). Die aufgabenspezifische Verarbeitung ist ausschließlich in Prozeduren der Blöcke G bis J, ggf. A und F enthalten.
Das Schema der Programmablaufsteuerung
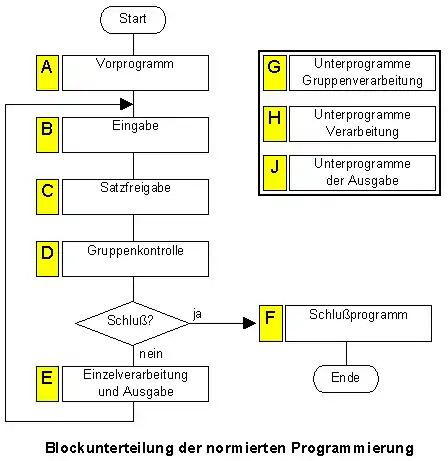
Der Programmablauf ist in Blöcke unterteilt, wobei jeder Block einen funktional zusammengehörigen Teil eines Programmes darstellt. Die Unterteilung stellt sozusagen den „natürlichen“ Aufbau eines kommerziellen Programms dar: Vor Beginn der eigentlichen Verarbeitung sind Anfangswerte zu setzen und Steuerinformationen auszuwerten, dann sind Eingabedaten zu lesen, der nächste Satz zur Verarbeitung ist auszuwählen, eventuell müssen Gruppenwechsel behandelt werden, schließlich ist der Datensatz zu verarbeiten und gegebenenfalls sind Daten auszugeben. Jeder Block stellt eine in sich geschlossene Einheit dar. Ein Block kann zur besseren Übersicht aus mehreren Unterblöcken bestehen. Der abgebildete Programmablaufplan zeigt folgende Blöcke:
- A: Vorprogramm für alle einmalig durchzuführenden Programmschritte
- B: Eingabe; sie besteht aus so vielen Unterblöcken wie es serielle Eingabedateien gibt. In jedem dieser Blöcke wird nicht nur die eigentliche Eingabe abgehandelt, sondern auch Plausibilitätsprüfungen und Reihenfolgekontrolle.
- C: Satzfreigabe; aus den gelesenen Sätzen je Datei wird ausgewählt, welcher Datensatz als nächster zu verarbeiten ist – und (vorher) zur Feststellung von Gruppenwechseln verwendet wird.
- D: Gruppenkontrolle und Aufruf der Gruppenwechsel-Unterprogramme für alle Gruppenstufen.
- E: Einzelverarbeitung; sie ist wiederum entsprechend der Anzahl Eingabedateien in Unterblöcke unterteilt.
- F: Schlussprogramm für alle einmalig nach dem eigentlichen Programmablauf zu durchlaufenden Programmbefehle.
- G: Unterprogramme der Gruppenverarbeitung; es gibt so viele Unterprogramme wie es Gruppenstufen gibt, jeweils für Vorläufe und Nachläufe getrennt.
- H: Unterprogramme der Einzelverarbeitung; diese Unterprogramme sollten möglichst klein und übersichtlich sein.
- J: Unterprogramme der sequentiellen Ausgabe und der wahlfreien Ein-/Ausgabe; für jede der genannten Dateien gibt es ein Unterprogramm.
Die Datenzufuhrsteuerung
Eine wesentliche Teilfunktion in der Normierten Programmierung ist die Automatik der ‚Datenzufuhr‘. Aus jeder Eingabedatei wird jeweils genau ein Datensatz gelesen – bis zum Dateiende inklusive. Aus den aktuellen (zuletzt gelesenen) Sätzen aller Dateien wird der nächste zu verarbeitende Satz ermittelt und der Verarbeitung zugeführt. Anschließend wird exakt aus dieser Datei wieder nachgelesen. Umgesetzt wird diese Art der Datenzufuhr in den Blöcken Eingabe und Satzfreigabe.
Gruppenbegriffsfelder
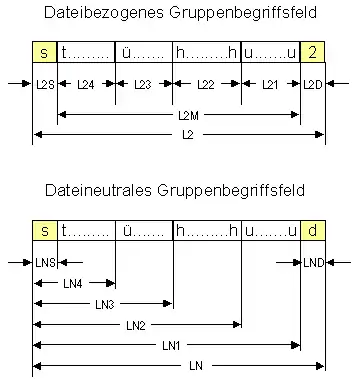
Der zentrale Schlüssel für die Steuerung des Programmablaufs ist der Gruppenbegriff, der in jedem Satz der Eingabedateien enthalten sein muss. Da die Gruppenbegriffe an unterschiedlichen Positionen der Eingabedateien liegen können, werden bei der normierten Programmierung die Gruppenbegriffe aus den Datensätzen herausgeholt und in separaten dateibezogenen Gruppenbegriffsfeldern von links nach rechts nach der Gruppenstufenhierarchie absteigend gespeichert. Es gibt für jede Eingabedatei ein solches, bei allen Dateien gleich großes und gleich-formatiges Gruppenbegriffsfeld – deshalb dateibezogen. Im Beispiel besteht das Gruppenbegriffsfeld der Eingabedatei 2 von rechts nach links aus der Dateinummer L2D („2“), den Gruppenbegriffen L21 (Untergruppenbegriff), L22 (Hauptgruppenbegriff), L23 (Übergruppenbegriff), L24 (ein noch höherer Gruppenbegriff) und aus dem Feld L2S für den Dateistatus. Die Felder Ln1 bis Ln4 können gemeinsam als LnM zur Paarigkeitsprüfung herangezogen werden. Die Namen der Felder wurden in Anlehnung an die damals weit verbreitete Terminologie von RPG (Report Program Generator) vergeben (L für Level, Gruppenstufe).
Neben den dateibezogenen Gruppenbegriffsfeldern gibt es zwei weitere, dateineutrale Felder, die für die Gruppenkontrolle verwendet werden:
- LA enthält den Gruppenbegriff des letzten verarbeiteten Satzes
- LN enthält den Gruppenbegriff des nächsten zu verarbeitenden Satzes
Die Größe stimmt mit der Größe der dateibezogenen Felder L0, L1, … voll überein. Lediglich die Definition der Felder ist aus Zweckmäßigkeitsgründen für die Gruppenkontrolle anders gewählt worden. Im Beispiel dient das Feld LN1 zur Kontrolle der Untergruppe, das Feld LN2 der Kontrolle der Hauptgruppe usw.
Die Datei-Nummer
Nach Eingabe eines Satzes von jeder Datei muss von allen Sätzen jener ausgewählt werden, der als Nächstes verarbeitet werden soll. Bei unterschiedlichen Gruppenbegriffen ist die Lösung einfach, der Satz mit dem kleinsten Gruppenbegriff ist als nächster zu verarbeiten. Sind die Gruppenbegriffe jedoch gleich (paarig), muss entschieden werden, welche Datei die höhere Priorität hat, d. h. die Dateinummer bestimmt die Priorität. Bei dem klassischen Fall einer Gegenüberstellung von Stamm- (z. B. Teilestamm) und Bewegungsdaten (z. B. Lagerbewegungen) bestimmen die Bewegungsdaten, ob die Stammdaten bearbeitet werden müssen oder nicht, der Bewegungssatz muss also als erster verarbeitet werden. Die Dateinummer – eine Konstante – bestimmt bei Paarigkeit der restlichen Gruppenbegriffe die Reihenfolge (Priorität) der Verarbeitung.
Der Datei-Status
Der Dateistatus unterscheidet vier Zustände:
- 0 = Satz nachziehen
- 1 = Satz nicht nachziehen
- 2 = Datei abgeschlossen
- 3 = Datei nicht vorhanden
Am Anfang stehen die Zustände aller Eingabedateien auf 0 („Satz nachziehen“). Nach dem Nachziehen einer Datei wird ihr Status auf 1 gesetzt. Erst wenn sie zur Verarbeitung freigegeben wird, wird der Status wieder auf 0 gesetzt. Der Status 3 kann z. B. auf Grund von Vorlaufdaten Ablaufvarianten mit unterschiedlichen oder vorhandenen/nicht vorhandenen Dateien steuern.
Der Steuerungsmechanismus
Die Steuerung des Programms geschieht (grob) nach der Logik wie sie im Schaubild 'Blockunterteilung der normierten Programmierung' dargestellt ist. Von hier aus werden alle Subroutinen der Verarbeitung (A bis G) angesteuert. Grundlage dazu sind die dateibezogenen und die dateineutralen Gruppenbegriffsfelder, wie sie beim Lesen und in der Satzfreigabe bereitgestellt werden.
Block A: Vorprogramm
Hier werden Aktionen durchgeführt, die zu Beginn des Programms erforderlich sind. Beispiele: Einlesen von Parametern (z. B. als 'Vorlaufkarten' zur Festlegung des Laufdatums oder von Laufvarianten); Initialisieren/Laden von Lookup-Tabellen und anderen Datenbereichen; Dateien eröffnen (OPEN); Schalter setzen; einmalige Ausgabe von Titelzeilen; kurz alle einmaligen Arbeiten vor Beginn des von den Eingabedaten abhängigen Verarbeitungszyklus.
Block B: Eingabe
Der Block B ist je nach der Anzahl der sequentiellen Eingabedateien in Unterblöcke B0, B1, B2, … unterteilt, die nacheinander durchlaufen werden. Je nach Dateistatus wird ein Satz gelesen oder nicht. Direkt nach dem Lesen erfolgt die Prüfung auf Dateiende. Falls ja, wird der Dateistatus auf „Dateiende“ gesetzt, andernfalls auf „nicht nachziehen“ und die dateispezifischen Gruppenbegriffsfelder werden gefüllt.
Wenn nicht gesichert ist, dass eine Eingabedatei immer in der richtigen Sortierfolge vorliegt, sollten in diesem Block eine Reihenfolgekontrolle oder andere Plausibilitätsprüfungen stattfinden – ggf. mit vorzeitigem Programmabbruch.
Auch kann hier evtl. ein Filtern, d. h. Überlesen bestimmter Datensätze stattfinden – die damit auch keine Gruppenwechsel auslösen.
Block C: Satzfreigabe

Im Block C erfolgt auf Grund der Inhalte der Gruppenbegriffsfelder je Datei die Auswahl und Freigabe des nächsten zu verarbeitenden Satzes. Der nächste zu verarbeitende Datensatz ist bei 'aufsteigender Folge' aller Gruppenbegriffe der mit dem niedrigsten Gesamt-Ordnungsbegriff. Ist für einen oder mehrere Ordnungsbegriffe 'absteigende Folge' festgelegt (Beispiel: Neuestes Datum zuerst verarbeiten), so muss dies bei der Satzfreigabe in geeigneter Weise berücksichtigt werden. Durch die prioritätssteuernd definierte Dateinummer wird auch bei aufgabenspezifisch gleichen Gruppenbegriffen in mehreren Dateien der richtige Datensatz zuerst ausgewählt.
Block D: Gruppenkontrolle
Die Gruppenkontrolle erfolgt mit Hilfe der dateineutralen Gruppenbegriffsfelder LN und LA. Zur Prüfung eines Gruppenwechsels der niedrigsten Stufe wird LN1 gegen LA1 (siehe Schaubild 'Dateineutrales Gruppenbegriffsfeld') verglichen, für einen Wechsel der zweitniedrigsten Stufe LN2 gegen LA2 usw. - bis zur höchsten Gruppenstufe.
Für festgestellte Gruppenwechsel werden die Unterprogramme des Blocks G aufgerufen, und zwar zunächst die Gruppen-Nachläufe (außer nach dem ersten Lesen; von der niedrigsten Stufe bis zur festgestellten Wechselstufe) und danach die Gruppen-Vorläufe (außer nach der Verarbeitung aller Datensätze; von der festgestellten Wechselstufe bis zur niedrigsten).
Block G: Gruppenverarbeitung
Hier wird aufgabenspezifisch verarbeitet, was am Ende bzw. am Anfang eines jeden Gruppenbegriffs zu tun ist. Die Verarbeitung erfolgt in den Unterblöcken G1, G2 usw. (Nummernteil identisch mit der Gruppenstufe, z. B. LN1, LN2). Durch zusätzliche Unterblöcke wie G1V, G2N … wird nach Gruppen-Vorlauf (Beispiel: Ausgabe einer Listen-Kopfzeile) und Gruppen-Nachlauf (Beispiel: Ausgabe von Summen) unterschieden. Die Aufrufe erfolgen aus Block D nur für die dort festgestellten Gruppenstufen.
Beachte: Die Ausführung des Vorlaufs und des Nachlaufs für einen konkreten Gruppenbegriff (z. B. PLZ 12345) liegt zeitlich weit auseinander; dazwischen liegt mindestens eine Einzelverarbeitung, ggf. auch die Gruppenverarbeitung für niedrigere Gruppenstufen.
Block E: Einzelverarbeitung
In den Unterroutinen des Blocks E werden die Datensätze aus den steuernden Eingabedateien verarbeitet. In den Unterblöcken E1, E2 usw. wird genau der Datensatz verarbeitet, der in der Satzfreigabe (Block C) ausgewählt wurde – und dessen Dateinummer im Feld LND steht. Evtl. erforderliche (alte) Gruppen-Nachläufe und (neue) Gruppen-Vorläufe sind zu diesem Zeitpunkt bereits verarbeitet.
Je nach Aufgabenstellung, Satzart etc., werden z. B. Daten zwischengespeichert, Summen berechnet und kumuliert, Daten / Einzelzeilen ausgegeben (durch Aufruf eines Unterprogrammes des J-Blockes), Schalter gesetzt (z. B. QL1, QL2, QG1, QG2, … auf die Schalter der normierten Programmierung wird hier nicht eingegangen) usw.
Block H: Unterprogramme der Verarbeitung
„Die häufige Verwendung von Unterprogrammen ist sehr zu empfehlen. Selbst wenn ein bestimmter Verarbeitungsteil im Programm nur einmal vorkommt, kann es sinnvoll sein, diesen Teil in ein Unterprogramm auszulagern, um die Ablauflogik des Verarbeitungsprogramms entsprechend klar und übersichtlich herauszuarbeiten.“ (SPERRY UNIVAC: Logik der Programmierung – Normierte Programmierung. um 1970)
Block J: Unterprogramme der seriellen Ausgabe und wahlfreien Ein-/Ausgabe
Es wird empfohlen, alles was zur Ausgabe im weiteren Sinn gehört, in diese Unterprogramme auszulagern, um die die Ausgabe veranlassenden Verarbeitungsroutinen von den dazu erforderlichen (oft formalen) Details zu 'entlasten'. Das kann (neben der eigentlichen Satzausgabe) z. B. sein: Druckbereiche löschen, bei Randomdateien die Satzadresse berechnen, Steueranweisungen für bestimmte Geräte absetzen usw.
Block F: Schlussprogramm
Hierzu gehört das Schließen von Dateien, die Ausgabe von z. B. Gesamtsummen und die Beendigung des Programms.
Die besonderen Merkmale der normierten Programmierung
Die Programmierzeit wurde im Vergleich zur „wilden“ Programmierung wesentlich verkürzt, ebenso die Testzeit. Das System ist relativ einfach zu erlernen, ist unabhängig von Maschinentypen und Programmiersprachen und unabhängig von den jeweiligen Programmierern (entsprechend wurde es von „Künstlern“ auch gerne abgelehnt). Jemand, der die Methode der normierten Programmierung kennt, kann sich schnell in ein fremdes Programm, das dieser Methodik folgt, einarbeiten.
Weitere Überlegungen
Steuernde / nicht steuernde Dateien
Ob eine Datei in der NP-Verarbeitung als steuernd behandelt wird, kann im Zweifel unterschiedlich entschieden werden. Von Bedeutung ist dies zum Beispiel, wenn in bestimmten Dateien die Daten nur verkürzte Gruppenbegriffe aufweisen. So könnten z. B. in einer Aufgabenstellung die Daten für Kunden, für Bestellungen und für Mahnungen aus drei Dateien stammen. Behandelt man die Kundendatei als steuernd, so entstehen Gruppenwechsel ohne Rücksicht darauf, ob Bestellungen oder Mahnungen vorliegen oder nicht. Alternativ könnten die Kundendaten als Teil der individuellen Verarbeitung (z. B. im Vorlauf_Kunde, sich aus Bestellungen ergebend) gezielt mit Direktzugriff oder sequentiell 'nachgelesen' werden.
Alternativ zur Steuerung über mehrere Eingabedateien können Daten im Lesezugriff (z. B. bei Nutzung der Datenbanksprache SQL) oder durch eigene Vorverarbeitungsprogramme zu nur einem gemeinsamen Datenbestand zusammengefasst werden.
Gruppenbegriffe als wesentliche Elemente
Gruppenbegriffe (auch Gruppierungsbegriff oder Ordnungsbegriff genannt) sind Inhalte von Datenfeldern, nach denen die zu verarbeitenden Daten zu Gruppen zusammengefasst werden, ggf. auch mehrstufig. Dies bedeutet zum Beispiel, dass zu Beginn eines Teilbegriffs Überschrifts-/Kopfzeilen und/oder am Ende Summenzeilen ausgegeben werden. Üblich sind solche Gruppierungen im Reporting, aber auch zu anderen Verarbeitungszwecken. Welche Feldinhalte als Gruppenbegriff(e) verwendet werden, wird stets durch den Verarbeitungszweck bestimmt.
Die nachfolgend beschriebenen besonderen Eigenschaften von Gruppenbegriffen (Beispiele) müssen ggf. im Rahmen der Programmentwicklung durch besondere Implementierungsmaßnahmen berücksichtigt werden:
- Gruppenbegriffe können einstufig (nur Postleitzahl) oder mehrstufig (PLZ und Altersgruppe …) sein.
- Sie treten einheitlich in allen Eingabedateien auf oder zum Teil nur verkürzt. Beispiel: Kundendaten mit nur Kundennummer, Bestelldaten zusätzlich mit Bestellnummer.
- Sie stammen aus direkt gespeicherten Informationen oder sind abgeleitete Informationen (wie Alter oder Altersgruppe (aus Geburtsdatum) oder Betrags-Größenklasse). Ableitungen müssen im Rahmen einer Vorverarbeitung hergestellt werden. Bei einfachen Ableitungen ist dies im Lesevorgang selbst möglich, ggf. sind vorgeschaltete Verarbeitungsprogramme erforderlich.
- Sie können dem vollständigen Inhalt eines Felds entsprechen oder Teil eines Feldes sein (wie Stelle 1 und 2 der Postleitzahl)
- Die Sortierung kann aufsteigend oder absteigend (neuestes Datum vorne) sein.
- Gruppenbegriffe können für den Datenbestand übliche Begriffe sein (Land, Postleitzahl bei Adressdaten) und/oder Begriffe, die zu besonderen Zwecken ausgewertet werden sollen (Anzahl Monate seit letzter Bestellung; Geburtstag MMTT). Derselbe Datenbestand kann so nach vielen unterschiedlichen Kriterien verarbeitet werden.
- Die Gruppenbegriffe stammen aus einem (1) oder mehreren Datenbeständen (Postleitzahl und Alter aus Kundendaten, Herstellerland aus Artikeldaten).
- Die Gruppenbegriffe weisen ggf. unterschiedliche Datenformate auf – entweder die einzelnen Teilbegriffe und/oder identische Begriffe aus unterschiedlichen Eingabedateien sind unterschiedlich formatiert.
- Die Datensätze müssen zur Verarbeitung in der definierten Reihenfolge sortiert sein oder so gelesen werden können. Meist wird diese Reihenfolge bei der Verarbeitung überprüft.
- Über die Gruppenbegriffe hinaus ist eine zusätzliche Sortierung der Datensätze üblich, zum Beispiel für die Rechnungserstellung nach Artikelnummer, obwohl in der Rechnung die Bestellungen nur je Kundennummer zusammengefasst sind.
Hilfsmittel für die Normierte Programmierung

Zur Erstellung eines Programms nach Normierter Programmierung sollten Hilfsmittel angewendet werden, mit denen der Aufwand zur Programmerstellung minimiert und die Qualität der erstellten Programme (z. B. bezüglich Richtigkeit, Testbarkeit, Einheitlichkeit) erhöht bzw. gesichert werden kann. Hierzu zählen:
- Programmgeneratoren: Im Systemsoftwaremarkt sind Generatoren verfügbar, mit denen auf der Basis zu definierender Vorgaben ein Programmrahmen erzeugt werden kann. Dieser enthält i. d. R. die komplette Programmsteuerung mit allen dazu erforderlichen Datenfeldern und den von der Hauptsteuerung angesprochenen Unterroutinen (Eingabe, Gruppenkontrolle und -Verarbeitung, Verarbeitung usw.). Oft unterstützen diese Generatoren nur bestimmte Programmiersprachen. Auch werden die Datenfelder und Unterroutinen in der Regel generator-spezifisch nach anderen als den hier verwendeten Namenskonventionen erzeugt.
- Programmtemplates: Wenn kein Generator verfügbar ist, ist ein Muster-Programmrahmen hilfreich, der ähnliche Strukturen wie unter 'Programmgeneratoren' genannt – und weitere Unternehmensstandards berücksichtigend – bereitstellt. Zum Erstellen eines neuen Programms wird der Rahmen kopiert und individuell auf die Aufgabenstellung (Anzahl Dateien und Gruppenbegriffe) angepasst.
In beiden Fällen liegt nach den vorgenannten vorbereitenden Aktivitäten die gesamte Ablaufsteuerung fertig vor, der Programmierer muss 'nur noch' die aufgabenspezifischen Verarbeitungsdetails in den noch leeren Unterroutinen (wie Gruppenvorlauf_1, Einzelverarbeitung_A usw.) einstellen.
Weitere Standardisierungen
Eine wörtliche Auslegung von 'Normierte Programmierung' könnte alle normierenden / standardisierenden Aspekte der Programmierung (= das Erstellen eines Computerprogramms im engeren Sinn) umfassen. Dazu können, neben der normierten Ablaufsteuerung (wie in diesem Artikel beschrieben) folgende Aspekte gehören:
- Namenskonventionen: HIER im Wesentlichen als Vorschlag für die Benennung der Funktionsblöcke beschrieben. Regeln für die Benennung von Datendefinitionen sollten ebenfalls im Detail vorgegeben sein.
- GOTO-freie Programmierung: Abhängig von der verwendeten Programmiersprache werden hierfür Schleifenkonstrukte angeboten. Ziel hierbei ist eine übersichtliche Programmlogik. Zumindest sollten direkte Sprünge in fremde Subroutinen niemals erlaubt sein, d. h. jede Subroutine springt zu ihrem Aufrufpunkt zurück.
- Standard-Funktionen: In vielen Unternehmen existieren für bestimmte Aufgaben (technisch / fachlich) vorgefertigte Routinen (Unterprogramme, Makros, Codesequenzen, …), die in individuellen Programmen zu verwenden sind. Beispiele: Open / Close, Datumsberechnung, Druckausgabe, …
- Standard-Datendefinitionen: Die Struktur von Datensätzen (ihre Feldfolge, Länge, Formate, …) sollte immer in einer Form vorliegen, die in allen diese Dateien verarbeitenden Programmen verwendet wird. Hierbei sollte es z. B. möglich sein, für die Eingabe einen anderen Präfix zu verwenden als für die Ausgabe.
- Gestaltung von Bildschirminhalten: Farben, Position von Eingabefeldern und Fehlermeldungen, …
- Gestaltung von Listen: Anordnung von Kopf- und Fußzeilen, …
- Programmkommentare: In einigen Unternehmen ist vorgeschrieben, die erstellten Befehle sehr detailliert zu kommentieren. Hierbei besteht die Gefahr von Redundanz zu anderen schriftlichen Vorgaben.
- …
Die Misserfolge bei den zahlreichen Versuchen nationaler oder gar weltweiter Standardisierung sollte die Unternehmen nicht davon abhalten, entsprechende Vorgaben als innerbetriebliche Regeln aufzustellen – und deren Einhaltung (als Teil der Qualitätssicherung) zu überprüfen.
Normierung / Standardisierung ist ein wesentlicher Aspekt von Qualität. Siehe auch Programmierstil.
Kritik und Weiterentwicklungen
Ende der 1960er und in den 1970er Jahren waren 'Top-down-Vorgehensweise, schrittweise Verfeinerung und modulare Programmierung' Diskussionsthemen zur Softwareentwicklung. Insbesondere die Vorschläge von Edsger W. Dijkstra zur strukturierten Programmierung wirken bis heute, konnten aber schon damals innerhalb von normierten Programmen realisiert werden. Einer schrittweisen Verfeinerung vor allem der Blöcke E, H und J stand die normierte Programmierung nicht im Wege. Die elementaren Grundstrukturen waren z. B. in COBOL umsetzbar, ein „GO TO“-freies Programm mit normierter Programmierung war möglich, das Blockkonzept war also auch mit Sprachen wie COBOL und PL/I, ja sogar mit Assembler möglich. Allerdings wird die Lesbarkeit der Programme bis heute von manchen Programmierern kritisiert, im Besonderen wenn der Quellcode von NP-Generatoren erzeugt wurde und z. B. ungewohnte Feld- und Prozedurbezeichnungen, zum Teil sogar „GO TO“-Befehle enthielt.
Der Ansatz der 'Normierten Programmierung' wird auch durch die Tatsache bestätigt, dass viele Reportgeneratoren und Datenbank-Auswertungssprachen strukturell nahezu identische Konstrukte verwenden: Der Benutzer kennt und definiert hier z. B. Listenkopf und -Fuß (entsprechend Programmvorlauf und -Ende), Gruppenkopf und Gruppenfuß (entsprechend Gruppenvorlauf und Gruppennachlauf) für mehrere, hierarchisch definierte Gruppenstufen. Die Einzelzeile (auch Detailbereich genannt) zeigt Informationen über den einzelnen Datensatz, was der Einzelverarbeitung entspricht.
In ihrem vollen Umfang enthält das Schema der normierten Programmierung Teilfunktionen, die unter gewissen Umständen überflüssig sein oder vereinfacht implementiert werden können. So kann z. B. im Block 'Satzfreigabe' die Auswahl des nächsten zu verarbeitenden Datensatzes entfallen, wenn nur ein Eingabebestand vorliegt.
Siehe auch
- Gruppenwechsel – eine vereinfachte Darstellung der Gruppenwechselverarbeitung.