Monolithischer Kernel
Ein monolithischer Kernel ist ein Kernel, in dem nicht nur Funktionen zu Speicher- und Prozessverwaltung und zur Kommunikation zwischen den Prozessen, sondern auch Treiber für die Hardwarekomponenten und möglicherweise weitere Funktionen direkt eingebaut sind.
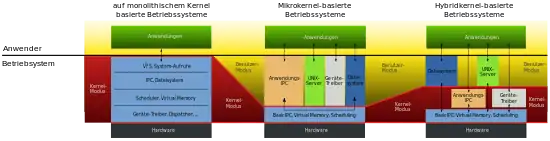
Für die Treiber werden keine zusätzlichen Programme benötigt – ein Geschwindigkeitsvorteil gegenüber einem Mikrokernel. Allerdings sind solche Kernel fehleranfälliger, da der Teil, der abgestürzt ist, nicht einfach (wie es bei einem Mikrokernel theoretisch möglich wäre) neu gestartet werden kann, sondern sogar einen Absturz des gesamten Systems nach sich ziehen kann.
Die Möglichkeit zur Portierung wird oft durch ein geschicktes internes Abstraktionsmodell umgesetzt, das die hardwarespezifischen Funktionen von den allgemeinen trennt. So kann auch in einer monolithischen Kernelarchitektur ein Höchstmaß an Portabilität auf andere Hardwareplattformen erreicht werden.
Beispiel Linux
Die Kernel-Entwickler von Linux haben die Schwächen des monolithischen Kernels schon früh erkannt und sind ihnen durch das Auslagern von Funktionalitäten in Kernel-Module begegnet. Durch die intensive Verwendung von Kernelmodulen, auch für betriebssystemnahe Funktionen, ist das Nach- oder Neuladen von Systemfunktionen, auch während des Betriebs, sowie während der Entwicklungsphase möglich. Sie laufen somit wieder im Kernel-Modus, so dass es sich bei Linux trotzdem weiterhin um einen monolithischen Kernel handelt. Dies hat den Nachteil, dass die Schutzmechanismen moderner Prozessoren bei den Kernelmodulen nur bedingt greifen und ein fehlerhaftes Modul (im Speziellen fehlerhaft arbeitende Treiber anderer Anbieter) das ganze System zum Absturz bringen kann.
Systemaufruf in monolithischer Architektur
Aufrufe von Betriebssystemfunktionen aus einem Anwenderprogramm heraus benötigen eine Schnittstelle (API). Die Systemaufrufe lösen den Eintritt in den privilegierten Modus (Kernelmodus) aus. Dafür werden Softwareinterrupts genutzt. Die Anwendung hinterlegt Parameter und einen Identifizierer für die gewünschte Funktion im Hauptspeicher und erzeugt einen Trap. Der Prozessor unterbricht die Anwendung und startet die Trap-Behandlungsroutine (trap handler) des Betriebssystems. Die CPU-Kontrolle wird vom Anwendungsprogramm (engl. user mode) an das Betriebssystem (engl. kernel mode) übergeben. Über den Identifizierer kann nun die angeforderte Funktion gestartet werden. Die im Hauptspeicher abgelegten Argumente werden in den Kernadressbereich kopiert und auf ihre Konsistenz überprüft. Die CPU arbeitet den Aufruf ab. Nach Beendigung kopiert die aufgerufene Funktion entweder das Resultat oder den entstandenen Fehlercode in den Speicherbereich der Anwendung. Die Trap-Behandlung wird abgeschlossen, und es erfolgt ein Rücksetzen des Prozessors in den unprivilegierten Zustand. Die Kontrolle wird wieder an die Anwendung übergeben.
Vorteile
- Da die gesamten Betriebssystemfunktionen im Kernel-Modus ablaufen, wird der zeit- und rechenaufwändige Wechsel zwischen den Ringen des Protected Mode minimal gehalten.
- Die Zuverlässigkeit wichtiger Funktionen des Betriebssystems (wie Speicherverwaltung) ist nicht direkt vom Verhalten der Userprogramme abhängig und muss nicht in diese abgebildet werden (Stichwort: Dynamischer Speicher).
- Es entfällt eine aufwändige Kommunikation zwischen den einzelnen Teilen des Betriebssystems. Dadurch werden Probleme vermieden, die beim weiteren Aufteilen der Betriebssystemfunktionalitäten entstehen.
Nachteile
- Das Auswechseln von Funktionalitäten muss durch eine geschickte Verwaltung (beispielsweise durch Module) erfolgen.
- Bei Änderungen ist es normalerweise notwendig, den ganzen Kernel neu zu übersetzen. Teilweise gibt es jedoch auch Möglichkeiten, nur einzelne Module zu kompilieren.