Kartesischer Baum
Ein kartesischer Baum ist ein aus einer Folge von Zahlen abgeleiteter Binärheap, mit der zusätzlichen Eigenschaft, dass ein in-order-Durchlauf wieder die ursprüngliche Folge liefert. Der kartesische Baum für eine Folge kann in Linearzeit konstruiert werden.
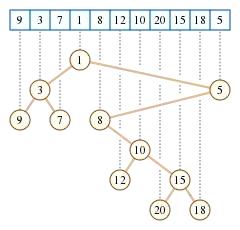
Definition
Der kartesische Baum einer Folge von Elementen, für die es eine Totalordnung gibt, ist wie folgt definiert:
- Der kartesische Baum ist ein Binärbaum.
- Für jedes Element der Folge existiert genau ein Knoten im Baum.
- Ein in-order-Durchlauf des Baumes liefert die ursprüngliche Folge. Das heißt: der linke Teilbaum der Wurzel besteht aus den Elementen, die in der Folge vor dem Wurzelelement stehen, der rechte Teilbaum aus den Elementen danach; dies gilt für jeden Teilbaum.
- Der Baum erfüllt die Heap-Eigenschaft (im Folgenden immer min-Heap).
Gemäß der Heap-Eigenschaft ist das Wurzelelement das kleinste Element der Folge. Dadurch lässt sich der Baum auch rekursiv definieren: Die Wurzel ist der minimale Wert der Folge und der linke und rechte Teilbaum sind die kartesischen Bäume der Teilfolgen links und rechts der Wurzel.
Falls die Elemente der Folge nicht paarweise verschieden sind, ist deren kartesischer Baum nicht eindeutig bestimmt. Die Eindeutigkeit lässt sich durch Wahl einer deterministischen Tie-Break-Regel gewährleisten (beispielsweise: "Betrachte das erste Vorkommen zweier gleicher Elemente als das kleinere").
Konstruktion
Aus der rekursiven Definition ergibt sich bereits ein naives Konstruktionsverfahren mit Worst-Case-Laufzeit . Die Konstruktion eines kartesischen Baums einer gegebenen Folge ist jedoch in Linearzeit möglich. Dazu wird von links nach rechts über die Folge der Elemente iteriert, sodass zu jedem Zeitpunkt (d. h. in Iteration ) bereits der kartesische Baum der ersten Elemente vorhanden ist. Um in der nächsten Iteration das nächste Element hinzuzufügen, beginne bei dem Knoten, der dem vorherigen Element entspricht, und folge von dort dem Pfad zur Wurzel, bis der tiefste Knoten erreicht wird, dessen zugehöriges Element kleiner als ist. Der Knoten für wird nun als rechter Teilbaum an angehängt und der vormals rechte Teilbaum von wird stattdessen der linke Teilbaum des neu eingefügten Knotens zu . In dem Spezialfall, dass auf dem Pfad zur Wurzel (einschließlich) kein Element gefunden wird, das kleiner als ist, wird die Wurzel des neuen kartesischen Baumes. Dazu wird die alte Wurzel als linkes Kind angehängt.





Die Gesamtlaufzeit für die Konstruktion ist linear in der Anzahl der Folgenelemente, da die Zeit für die Suche nach dem Knoten gegen die Anzahl der Knoten aufgerechnet werden kann, die nach der Iteration nicht mehr auf dem rechtesten Pfad liegen, während die Operationen zum Einfügen des neuen Knotens und das Umhängen eines Teilbaums in konstanter Zeit möglich sind.[1]
Programmierung
Das folgende Beispiel in der Programmiersprache C++ zeigt die Implementierung für das Erzeugen eines kartesische Baum. Die rekursive Funktion createCartesianTree erzeugt den Baum. Die einzelnen Knoten haben den Datentyp Node und jeweils einen linken und einen rechten Kindknoten vom Datentyp Node. In der Funktion main wird die in-order Reihenfolge des kartesischen Baums ausgegeben.[2]
#include <iostream>
#include <string>
#include <list>
using namespace std;
// Deklariert den Datentyp für die Knoten des Graphen
struct Node
{
int value;
Node* left, * right;
};
// Diese rekursive Funktion erzeugt den Teilbaum für den Wurzelknoten mit dem gegeben Index und gibt einen Zeiger auf den Knoten zurück
Node* createSubtree(int index, int numbers[], int parentValues[], int leftValues[], int rightValues[])
{
// Wenn der Index gleich -1 ist, wird ein Nullzeiger zurückgegeben
if (index == -1)
{
return 0;
}
// Erzeugt den Knoten und setzt den Wert für den gegebenen Index
Node* temp = new Node;
temp->value = numbers[index];
temp->left = createSubtree(leftValues[index], numbers, parentValues, leftValues, rightValues); // Rekursiver Aufruf für den linken Teilbaum
temp->right = createSubtree(rightValues[index], numbers, parentValues, leftValues, rightValues); // Rekursiver Aufruf für den rechten Teilbaum
return temp;
}
// Diese Funktion erzeugt den kartesischen Baum, indem der Index des Elternknotens, des linken Kindknotens und des rechten Kindknotens für jeden Knoten gespeichert werden und dann die Funktion createSubtree für den Index des Wurzelknotens aufgerufen wird
Node* createCartesianTree(int numbers[], int length)
{
int* parentValues = new int[length]; // Array für die Indexe der Elternknoten
int* leftValues = new int[length]; // Array für die Indexe der linken Kindknoten
int* rightValues = new int[length]; // Array für die Indexe der rechten Kindknoten
// Initialsiert die Arrays mit den Werten -1
memset(parentValues, -1, sizeof(parentValues));
memset(leftValues, -1, sizeof(leftValues));
memset(rightValues, -1, sizeof(rightValues));
int rootIndex = 0; // Variable für den Index mit dem aktuell kleinsten Wert
int lastIndex; // Variable für den zuletzt durchlaufenen Index
// Diese for-Schleife durchläuft alle Indexe vom zweiten bis zum letzten Element
for (int i = 1; i < length; i++)
{
lastIndex = i - 1;
rightValues[i] = -1;
// Diese while-Schleife durchläuft die Indexe bis zum Wurzelknoten, solange der Wert des Knotens nicht kleiner als der aktuelle Knoten ist
while (numbers[lastIndex] >= numbers[i] && lastIndex != rootIndex)
{
lastIndex = parentValues[lastIndex];
}
// Wenn der Wert zum gefundenen Index kleiner gleich als der aktuelle Wert ist, wird der aktuelle Index als Wurzel gesetzt
if (numbers[lastIndex] >= numbers[i])
{
parentValues[rootIndex] = i;
leftValues[i] = rootIndex;
rootIndex = i;
}
// Sonst Indexe für den eingefügten Knotens setzen
else
{
// Wenn der rechte Teilbaum für den zuletzt durchlaufenen Index leer ist, Knoten dort einfügen
if (rightValues[lastIndex] == -1)
{
rightValues[lastIndex] = i;
parentValues[i] = lastIndex;
leftValues[i] = -1;
}
// Sonst Knoten als Elternknoten des rechten Kindknotens des zuletzt durchlaufenen Knoten einfügen
else
{
parentValues[rightValues[lastIndex]] = i;
leftValues[i] = rightValues[lastIndex];
rightValues[lastIndex] = i;
parentValues[i] = lastIndex;
}
}
}
// Wenn der Wurzelknoten keine Elternknoten hat, Wert auf -1 setzen
parentValues[rootIndex] = -1;
return createSubtree(rootIndex, numbers, parentValues, leftValues, rightValues); // Aufruf der Methode für den Index des Wurzelknotens
}
// Gibt die in-order-Reihenfolge des Baums als Text zurück
string inOrderToString(Node* node)
{
if (node == 0)
{
return "" target="_blank" rel="nofollow";
}
string leftSubtreeString = inOrderToString(node->left);
string rootString = to_string(node->value);
string rightSubtreeString = inOrderToString(node->right);
return "(" + leftSubtreeString + rootString + rightSubtreeString + ")";
}
// Hauptfunktion die das Programm ausführt
int main()
{
// Initialisiert und deklariert ein Array mit 11 Werten für die Knoten des kartesischen Baums
int numbers[] = { 9, 3, 7, 1, 8, 12, 10, 20, 15, 18, 5 };
int length = sizeof(numbers) / sizeof(numbers[0]);
Node* root = createCartesianTree(numbers, length); // Aufruf der Funktion, die den kartesischen Baum erzeugt
cout << "In-order Reihenfolge:" << inOrderToString(root) << endl; // Aufruf der Funktion, die die in-order-Reihenfolge auf der Konsole ausgibt
}
|
Anwendungen
Range-Minimum-Query
Eine Bereichsminimumsanfrage (RMQ) auf einer Folge sucht das minimale Element einer zusammenhängenden Teilfolge. Im kartesischen Baum findet sich das Minimum der Teilfolge im tiefsten gemeinsamen Vorfahren (Lowest Common Ancestor) des ersten und des letzten Knotens der Teilfolge. In der oben verwendeten Beispielfolge findet sich zum Beispiel für die Teilfolge das Minimum im Lowest Common Ancestor des ersten und letzten Elements ( und ).




Da der Lowest Common Ancestor unter Verwendung einer Datenstruktur mit linearem Speicherplatz in linearer Zeit ermittelt werden kann[3][4], lassen sich mit Hilfe eines kartesischen Baumes auch RMQs innerhalb dieser Schranken beantworten.
3-seitige Bereichsanfragen
Der Name des kartesischen Baumes stammt von der Verwendung zur Beantwortung dreiseitiger Bereichsanfragen in der kartesischen Ebene. Gesucht sind alle Punkte die die Bedingungen (1) und (2) erfüllen. Dazu werden die Punkte zunächst nach x-Koordinate sortiert und der kartesische Baum mit Heap-Eigenschaft bezüglich der y-Koordinate konstruiert. Für eine konkrete Anfrage bilden nun die Punkte, die Bedingung (1) erfüllen, eine zusammenhängende Teilfolge, wobei der erste Knoten der Teilfolge (mit kleinster x-Koordinate) und der letzte (mit größter x-Koordinate) sei. Im Lowest Common Ancestor von und findet sich der Punkt aus diesem Intervall mit minimaler y-Koordinate. Falls die y-Koordinate von kleiner als die Schranke ist, ( liegt also im gesuchten Bereich) wird ausgegeben und rekursiv auf den Teilfolgen zwischen und sowie zwischen und weitergesucht. Auf diese Weise lassen sich, nachdem einmalig die Knoten und bestimmt wurden (z. B. mit binärer Suche), alle Punkte innerhalb des gesuchten Bereichs in konstanter Zeit pro Punkt ermitteln[1].







Geschichte
Kartesische Bäume gehen zurück auf Vuillemin (1980)[5], der einen Spezialfall der oben beschriebenen kartesischen Bäume für eine Folge von Punkten im kartesischen Koordinatensystem beschrieb: Dabei bezieht sich die Heap-Eigenschaft auf die y-Koordinate der Punkte, ein in-order-Durchlauf liefert die sortierte Folge der x-Koordinaten. Gabow, Bentley, und Tarjan (1984)[1] und weitere Autoren folgten der hier gegebenen Definition, in der ein kartesischer Baum für beliebige Folgen definiert wird und abstrahierten damit von dem ursprünglichen geometrischen Problem.
Einzelnachweise
- Gabow, H.N., J.L. Bentley, and R.E. Tarjan: Scaling and related techniques for geometry problems. In: Proceedings of the sixteenth annual ACM symposium on Theory of computing. 1984, S. 135–143. doi:10.1145/800057.808675.
- GeeksforGeeks: Cartesian Tree
- Baruch Schieber, Uzi Vishkin: On finding lowest common ancestors: simplification and parallelization. In: SIAM Journal on Computing. 17, Nr. 6, 1988, S. 1253–1262. doi:10.1137/0217079.
- Dov Harel, Robert E. Tarjan: Fast algorithms for finding nearest common ancestors. In: SIAM Journal on Computing. 13, Nr. 2, 1984, S. 338–355. doi:10.1137/0213024.
- Jean Vuillemin: A unifying look at data structures. In: ACM (Hrsg.): Commun. ACM. 23, Nr. 4, New York, NY, USA, 1980, S. 229–239. doi:10.1145/358841.358852.