Range Minimum Query
Range Minimum Queries (RMQs) adressieren innerhalb der Informatik das Problem, eine Anfrage nach dem kleinsten Element innerhalb eines spezifizierten Bereichs eines Arrays zu beantworten. Eine effiziente Beantwortung hat Relevanz für weitere Probleme der Informatik, wie z. B. für die Textindizierung und -kompression, Flussgraphen etc.
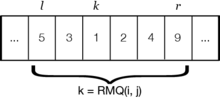
Definition
Sei ein Array der Länge mit Elementen eines Universums totaler Ordnung, dann liefere (mit und ) die Position des kleinsten Elements innerhalb des angegebenen Intervalls[1]. Abbildung 1 veranschaulicht die Anfrage auf eine Beispielsequenz.





Triviale Bearbeitung
Es existieren zwei triviale Lösungen zur Problembearbeitung, die entweder platz- oder zeitineffizient sind.[1]
- Lineares Scannen: Durch Scannen von wird für jede Query eine lineare Anfragezeit in worst-case und ein Platzbedarf von erreicht.
- Vorberechnung einer Lookup Tabelle: Naiv wird eine Tabelle vorberechnet, die die Antworten auf alle möglichen Range Minimum Anfragen speichert. Somit wird eine konstante Anfragezeit in erreicht, wobei Kombinationen Platz benötigen.





Angenommen wird allerdings, dass es sich bei um ein statisches Array handelt und die Anfragen on-line gestellt werden, wodurch eine geschickte Vorberechnung und die Konstruktion einer geeigneten Datenstruktur die Anfragezeit deutlich reduzieren kann. Hierbei wird eine nahezu konstante Anfragezeit mit linearem Platzverbrauch angestrebt.
Effiziente Konstruktion
Die vorberechneten RMQ-Datenstrukturen können in zwei Kategorien eingeteilt werden: (a) Array-Indexierung und (b) Array-Codierung. Im Fall (a) benötigt die vorberechnete Struktur Zugriff auf das Array um darauf RMQs zu beantworten. Im Fall (b) ist ein Zugriff auf nicht notwendig, um eine RMQ zu beantworten.[2] Die vorgestellten Lösungen sind der Kategorie der Array-Indexierung zuzuordnen.
Im Folgenden wird schrittweise dargestellt, wie das gegebene Problem mittels geschickter Vorberechnung auf eine Komplexität von (linearer Platzbedarf/Vorberechnungszeit, konstante Anfragezeit) reduziert werden kann.

Linearithmischer Platzbedarf
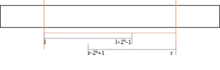
In M. A. Bender et al. (2005)[3] wird eine Möglichkeit beschrieben, um zu erreichen. Hierzu werden die Ergebnisse für alle möglichen Startpositionen und Längen der Form vorberechnet. Aufgrund dessen wird die tatsächliche RMQ in maximal zwei gleich lange Teilanfragen zerlegt, deren Längen Zweierpotenzen sind und sich möglicherweise überlappen. Hierbei wird die größtmögliche Zweierpotenz gewählt, wobei ist. Aufgrund der Vorberechnung kann das Ergebnis über das Intervall von in konstanter Zeit bestimmt werden. Abbildung 2 verbildlicht das Vorgehen und zeigt beispielhaft, wie die RMQ (Intervall = rote Linie) in zwei RMQs (graue Linien) zerlegt wird.
Sei die Tabelle mit den vorberechneten Antworten. Der Algorithmus umfasst insgesamt drei Schritte, um das Ergebnis einer RMQ zu bestimmen:










An dieser Stelle wird ersichtlich, dass die angegebene Lösung zur Kategorie (a) Array-Indexierung gehört, weil das kleinere der beiden Minima der Teilanfragen ermittelt werden muss und hierzu zwei Zugriffe auf benötigt werden.
Analyse
Aufgrund der Vorberechnung kann eine RMQ in beantwortet werden. Die zusätzliche Datenstruktur enthält für jede Position innerhalb des Arrays maximal vorberechnete Minima, weil es im worst-case Zweierpotenzen von der ersten Arrayposition bis zum Ende gibt. Hierdurch reduziert sich der Platzbedarf von auf .
Die Vorberechnung benötigt mittels dynamischer Programmierung eine Laufzeit von Schritten, wobei folgende Rekurrenz gelöst wird: (siehe Abbildung 3), um die entsprechende Tabelle zu berechnen. Die benötigte Zeit für die Vorberechnung liegt in .



Linearer Platzbedarf

Die vorgestellte Lösung stammt von Johannes Fischer and Heun (2011)[1]. Hierbei wird der Platzbedarf auf reduziert, wobei das Eingabearray in Blöcke der Länge zerlegt wird. O.B.d.A. sei . Visuell ist die Blockbildung in Abbildung 4 dargestellt, wobei hier beispielhaft in vier Blöcke zerlegt wurde. Die RMQ kann nun in max. drei Teile zerlegt werden:


- Eine Anfrage, die vollständige Blöcke umfasst ().
- Zwei Anfragen, die jeweils einen Teil eines Blocks [in-Block] betreffen (, ).



Aufgrund der Bearbeitung der max. drei Teilanfragen erhält man das jeweilige Minimum über den umspannten Bereich. Im letzten Schritt werden die konkreten Werte aus geladen und verglichen. Daraufhin kann die Position des kleinsten der max. drei Werte als Ergebnis ausgegeben werden. Auch an dieser Stelle wird ersichtlich, dass die angegebene Lösung der Kategorie (a) Array-Indexierung zuzuordnen ist.
Anfrage über vollständige Blöcke
Die RMQ, die an Blockgrenzen abschließt (also vollständige Blöcke umfasst), kann mittels der Konstruktion aus Abschnitt 3.1 in mittels zwei überlappender Anfragen beantwortet werden. Man speichere das Minimum eines jeden Blockes in einer Liste (Abbildung 4), zudem sei . Hierauf wird die bekannte Konstruktion angewandt, wodurch sich ein Platzbedarf von



ergibt. Zusammenfassend kann gesagt werden, dass für diesen Fall eine RMQ in konstanter Zeit berechnet werden kann, wobei die Hilfsdatenstruktur linear viel Platz benötigt.
Anfragen auf Blockteile

Jedem Block wird ein Kartesischer Baum zugeordnet. Ein Kartesischer Baum wird nach folgender, rekursiver Vorschrift konstruiert und ist beispielhaft in Abbildung 5 zu sehen.

- Wurzel: Position des Minimums in
- Linkes Kind: Kartesischer Baum von
- Rechtes Kind: Kartesischer Baum von



Lemma: Falls die Kartesischen Bäume zweier Arrays die gleiche Struktur aufweisen, so gilt .
Der interessierte Leser kann den Beweis des Lemmas in Johannes Fischer and Heun (2011, S. 472)[1] nachlesen.


Aufgrund des Lemmas ergibt sich eine Reduktion für in-Block RMQs, da nicht jeder Block einzeln vorberechnet wird, sondern nur die Antworten für alle möglichen Kartesischen Bäume über Elementen ausreichen, denn jeder Block lässt sich in Linearzeit (Johannes Fischer and Heun 2011)[1] auf einen Kartesischen Baum abbilden, da die Baumkonstruktion amortisiert in liegt. Die Anzahl der Bäume entspricht der Catalan-Zahl . Die Bitmuster der Bäume dienen als Index für die vorberechnete in-Block Tabelle . Ein Kartesischer Baum wird hierbei durch seine Level-order unary degree sequence (LOUDS) eindeutig repräsentiert, welche von Jacobson (1989)[4]
beschrieben wird und Bits benötigt.
Insgesamt ergibt sich daraus ein Platzbedarf von .





Wie gezeigt wurde, kann das Problem auf linearen Platzbedarf und konstante Anfragezeit reduziert werden, indem die ursprüngliche RMQ in drei Teilanfragen zerlegt wird. Das Minimum über vollständig umfasste Blöcke wird unter Zuhilfenahme des Schemas aus Abschnitt 3.1 berechnet, für in-Block Anfragen werden Blöcke auf Kartesische Bäume abgebildet, deren Ergebnisse vollständig vorberechnet nicht mehr als linear viel Platz bzgl. der Eingabe benötigen.
Anwendungen
Im Folgenden werden zwei Anwendungsfälle für RMQs vorgestellt. Weitere Anwendungen sind z. B. in Johannes Fischer and Heun (2007, S.3)[5] nachzulesen.
Lowest Common Ancestor
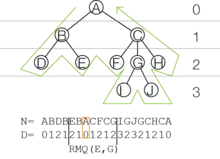
Eine LCA-Anfrage bzgl. eines Baumes und zwei Knoten liefert entweder (bzw. ), falls sich dieser auf dem Pfad von der Wurzel zu (bzw. ) befindet, oder denjenigen Knoten , an dem der gemeinsame Pfad zu und endet.





Wie erstmals von Gabow, Bentley, and Tarjan (1984)[6] beschrieben wurde, kann das LCA Problem linear auf das RMQ Problem reduziert werden (und umgedreht, siehe hierzu Bender and Farach-Colton (2000)[7]). Dies ist von Relevanz, da somit auch LCA-Anfragen in konstanter Zeit und linearem Platzbedarf bzgl. der Eingabe () gelöst werden können, wie es zum Beispiel in J. Fischer and Heun (2007)[5] dargestellt wird.
Die Reduktion beinhaltet eine Eulertour (bzw. einen in-Order Baumtraversal) in Zeit über den LCA-Baum zur Abbildung in ein Array , wobei für jedes Element in eine entsprechende Traversalnummer in gespeichert wird, indem beim Abstieg um dekrementiert (bzw. beim Aufstieg inkrementiert) wird, siehe hierzu Abbildung 6. Das Array benötigt linear viel Platz, weil die Kantenanzahl des Ursprungsbaumes durch dessen Knoten beschränkt ist. Für das Array kann nun die zuvor-beschriebene Vorberechnung für RMQs durchgeführt werden. Zur Lösung des LCA-Problems gilt nun: , wobei die Position der Eingabeknoten innerhalb kennzeichnen.




Längstes gemeinsames Präfix
In der Textindizierung können RMQs zum Auffinden von LCPs (Longest Common Prefix) bei der Mustersuche verwendet werden (bzw. Longest Common Suffix durch RMQ auf den umgedrehten Text), wobei das LCP eines gemeinsamen Präfixes der Suffixe berechnet, die in an Position und beginnen.



Hierzu wird das LCP-Array des Suffix-Arrays verwendet und zu ein inverses Suffix-Array berechnet, welches zum -ten Suffix im Suffixarray dessen Anfangsposition in liefert. Auf Basis dieser beiden Strukturen kann nun in konstanter Zeit die Länge des LCP mittels folgender Vorschrift berechnet werden: .[8]



Einzelnachweise
- Fischer, J. and V. Heun: Space-Efficient Preprocessing Schemes for Range Minimum Queries on Static Arrays. In: SIAM J. Comput. 40 (apr). 2011, S. 465–492. doi:10.1137/090779759.
- Gál, A. and Miltersen, P.: The Cell Probe Complexity of Succinct Data Structures. In: Automata, Languages and Programming. 2003, S. 190-190. doi:10.1007/3-540-45061-0_28.
- Bender, M. A., M. Farach-Colton, G. Pemmasani, S. Skiena, and P. Sumazin: Lowest common ancestors in trees and directed acyclic graphs. In: Journal of Algorithms. 57, Nr. 2, November 2005, S. 75–94. ISSN 0196-6774. doi:10.1016/j.jalgor.2005.08.001.
- Jacobson, G.: Space-efficient static trees and graphs. In: Foundations of Computer Science, 1989., 30th Annual Symposium. 1989, S. 549–554. doi:10.1109/SFCS.1989.63533.
- Fischer, J. and V. Heun: A new succinct representation of RMQ-information and improvements in the enhanced suffix array. In: Combinatorics, Algorithms, Probabilistic and Experimental Methodologies. 2007, S. 459–470. doi:10.1007/978-3-540-74450-4_41.
- Gabow, H.N., J.L. Bentley, and R.E. Tarjan: Scaling and related techniques for geometry problems. In: Proceedings of the sixteenth annual ACM symposium on Theory of computing. 1984, S. 135–143. doi:10.1145/800057.808675.
- Bender, M. A. and M. Farach-Colton: The LCA Problem Revisited. In: LATIN 2000: Theoretical Informatics. 2000, S. 88–94. doi:10.1007/10719839_9.
- Fischer, J. and V. Heun: Theoretical and practical improvements on the RMQ-problem, with applications to LCA and LCE. In: Combinatorial Pattern Matching. 2006, S. 36–48. doi:10.1007/11780441_5.