Kürzeste-Wege-Algorithmen mit externem Speicher
Ein Kürzeste-Wege-Algorithmus ist in der Algorithmik ein Algorithmus, der innerhalb eines Graphen die kürzesten Pfade zwischen zwei oder mehreren Knoten findet. In vielen Fällen sind die Eingabe-Daten für den Algorithmus zu groß für den Hauptspeicher, sodass sich ein Großteil der Daten auf einem externen Speicher (z. B. einer Festplatte oder Band-Laufwerk) befindet.
Da der Zugriff auf diesen externen Speicher wesentlich langsamer ist, werden in der Regel speziell angepasste External-Memory- oder Out-of-Core-Algorithmen verwendet. Bei dieser Art von Algorithmen möchte man in der Regel die Anzahl der (langsamen) Zugriffe auf den externen Speicher minimieren.
Allgemein
Es existieren unterschiedliche Varianten des Kürzeste-Wege-Problems bezüglich der Start- als auch Zielknoten. Im Folgenden werden Algorithmen vorgestellt, die von einem einzigen Startknoten aus die kürzesten Wege zu allen anderen Knoten berechnet. Dieses Problem wir auch als Single-Source Shortest Path (SSSP) bezeichnet.
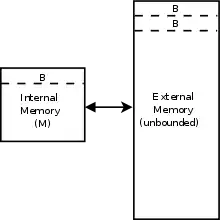
Zur Modellierung des Speichermodells wird häufig das External-Memory-Modell verwendet. Dabei besitzt das System einen Hauptspeicher mit begrenzten Größe jedoch sehr schnellen Zugriffszeiten. Zusätzlich existiert ein externer Speicher von beliebiger Größe auf den der Zugriff langsam und in Blöcken der Größe erfolgt.[1]


Anpassung des Dijkstra-Algorithmus
Eine mögliche Lösung des SSSP-Problems bietet der Dijkstra-Algorithmus. Die Idee dieses Greedy-Algorithmus ist es, ausgehend vom Start-Knoten immer die Kanten zu verfolgen, die zu dem nächsten noch nicht erreichten Knoten mit dem kürzesten Pfad führt. Dazu werden die nächsten möglichen Knoten in einer Prioritätswarteschlange gespeichert.
Man kann den Dijkstra-Algorithmus in einen externen Algorithmus abwandeln, indem man die verwendete Prioritätswarteschlange durch entsprechend angepasste External-Memory Datenstrukturen ersetzt. Dabei stößt man jedoch auf folgende Probleme[2]:
- In jedem Schritt des Algorithmus findet ein Zugriff auf alle adjazente (verbundenen) Kanten eines Knotens statt. Im schlechtesten Fall muss dadurch in jedem Schritt eine IO-Operation auf den externen Speicher ausgeführt werden. Dadurch ist die Laufzeit vor allem bei dünnbesetzten Graphen sehr schlecht. Bislang gibt es noch keinen bekannten Algorithmus, der das Problem auf beliebigen Graphen löst. Es gibt allerdings Lösungen für spezielle Graphen, wie z. B. planare Graphen[3].
- Der Algorithmus speichert immer, welche Knoten bereits erreicht wurden. Dieses Problem kann gelöst werden, in dem der Algorithmus phasenweisen ausgeführt wird[4]. In jeder Phase werden dabei die bereits besuchten Knoten in einer Hashtabelle gespeichert. Die Größe der Hashtabelle ist dabei so beschränkt, dass sie in den Hauptspeicher passt. Sobald die Hashtabelle voll ist, beginnt die nächste Phase. In dieser wird zunächst der komplette Graph durchlaufen und es werden alle Kanten entfernt, die zu bereits besuchten Knoten führen. Danach wird die Hashtabelle geleert und weiter der eigentliche Dijkstra-Algorithmus ausgeführt.
- Die verwendete Prioritätswarteschlange muss eine decrese_key-Operation unterstützen, also eine Funktion, mit der man die Priorität eines Elements in der Warteschlange nachträglich verringern kann. Dies ist notwendig, da während des Algorithmus kürzeren Pfade zu einem Knoten entdecken werden können, der sich bereits in der Warteschlange befindet. Viele bekannte External-Memory Prioritätswarteschlange bieten diese Funktion nur mit zusätzlichen IO-Operationen an.
Man kann allerdings, wenn wie zuvor genannten wurde ein phasenweiser Algorithmus verwendet wird, einen Knoten mehrfach in die Warteschlange einfügen. In diesem Fall müssen Knoten ignoriert werden, die bereits besucht wurden, weil man sie mehrfach in die Warteschlange hinzugefügt hat. Beim Wechsel in die nächste Phase kann man in dieser Variante die Warteschlange durchscannen und alle bereits besuchten Knoten entfernen.
Insgesamt ergibt sich daraus für den phasenweisen Algorithmus, dass Zugriffe auf den externen Speicher benötigt werden[2]. Dabei gibt die Anzahl der Knoten, die Anzahl der Kanten und die Größe des Hauptspeichers an. Außerdem gibt die Anzahl der notwendigen IO-Operationen beim Durchlaufen von Werten an und die Anzahl der IO-Operationen beim Sortieren von Werten[4].







Umsetzung mit Tournament Trees
Anstelle einer Prioritätswarteschlange kann man auch andere Datenstrukturen, wie die sogenannten Tournament Trees verwenden. Bei dieser werden die Elemente in der Warteschlange als Binärbaum dargestellt. Die Idee ist, dass die Elemente wie bei einem Turnier mit K.-o.-System angeordnet sind. In jedem Knoten (außer den Blättern) sind die Elemente aus den Kindknoten, die die höchste Priorität haben. Das Prinzip lässt sich anschaulich an dem Beispiel rechts erkennen. Hier haben die Element im Baum mit einer kleineren Zahl eine höhere Priorität. Dadurch befinden sich in der Wurzel des Baums die beiden kleinsten Elemente. Bei einem Tournament Tree handelt es sich um einen vollständigen Baum mit der Ausnahme, dass auf der untersten Tiefe von rechts Blätter fehlen dürfen.
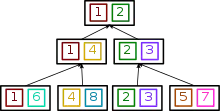
In unserem Fall enthält der Tournament Tree Elemente bestehend aus einem Tupel mit einem Knoten und einem Schlüssel nach dem die Elemente sortiert werden. Der Tournament Tree bietet die folgen Funktionen:


- deletemin: Gibt das Element mit dem kleinsten Schlüssel aus und ersetzt es durch .
- delete(x): Ersetzt das Element mit .
- update(x,newkey): Ersetzt das Element durch sofern





Diese Datenstruktur lässt sich effizient mit externem Speicher umsetzen. Dafür werden die einzelnen Operationen nicht sofort auf alle Knoten im Baum angewendet, sondern als sogenannte Signale in den einzelnen Knoten gespeichert. Jeder Knoten besteht dabei aus zwei Puffern, in den jeweils die Elemente des Knotens bzw. die Signale gespeichert werden. In jedem Puffer können dabei bis zu Objekte gespeichert werden. Die Größe muss dabei so gewählt werden, dass ein Knoten vollständig in den Hauptspeicher passt.
Zu Beginn werden alle Knoten des Trees mit als Schlüssel initialisiert. Die Signal-Puffer sind zunächst leer. Grundsätzlich werden Signale immer an der Wurzel eingefügt. Es gibt zwei verschiedene Arten von Signalen:

- Delete-Signale werden immer an die entsprechenden Kindknoten bis zu den Blättern weitergeleitet. Bei allen Knoten wird durch dieses Signal das Element aus dem Puffer entfernt. Eine Ausnahme bilden die Blätter: Hier wird der Schlüssel des Elements auf gesetzt.
- Update-Signale werden so lang an die Kindknoten weitergeleitet, bis der aktuelle Knoten das zu ändernde Element enthält. Ist der aktuelle Schlüssel des Elements im Knoten kleiner als der neue Schlüssel, der im Update-Signal enthalten ist, so wird das Signal verworfen. Ansonsten wird der Schlüssel abgeändert und das Signal weitergeleitet.
Wenn ein Signal an einem Knoten hinzugefügt wird, werden die Änderungen an dem Knoten selbst zunächst ausgeführt. Muss das Signal weitergeleitet werden, wird es in den Signal-Puffer eingefügt. Sobald der Puffer voll ist, muss er geleert werden. Dies geschieht, indem die Signale an die entsprechend zuständigen Kindknoten weitergeleitet werden. Dabei ist zu beachten, dass bei der Weitergabe der Signale an die Kindknoten muss der Knoten zunächst in den Hauptspeicher geladen werden.
Hat ein Knoten weniger als Elemente im Puffer, so muss der Knoten aufgefüllt werden. Dazu muss zunächst der Signal-Puffer wie zuvor beschrieben geleert werden. Anschließend wird der Knoten mit den Elementen der höchsten Priorität gefüllt. Sollte durch das Leeren des Signal-Puffers ein Kindknoten weniger als Elemente besitzen, so muss zuerst rekursiv der Kindknoten aufgefüllt werden.

Die Anzahl benötigter Zugriffe auf den externen Speicher bei einer Abfolge von Operationen beträgt höchstens:

Dijkstra kann mit dieser Datenstruktur modifiziert werden, um das SSSP-Problem im External-Memory-Modell effizient zu lösen. Dabei wird die Prioritätswarteschlange durch den Tournament Tree ersetzt. Der gesamte Anzahl der IO-Operationen, die Algorithmus benötigt beträgt:

wobei die Blockgröße ist, die bei einer IO-Operation übertragen wird.[5]
Einzelnachweise
- Peter Sanders: Memory Hierarchies — Models and Lower Bounds. In: Algorithms for Memory Hierarchies: Advanced Lectures (= Lecture Notes in Computer Science). Springer Berlin Heidelberg, Berlin, Heidelberg 2003, ISBN 978-3-540-36574-7, S. 5–7, doi:10.1007/3-540-36574-5_1.
- Irit Katriel, Ulrich Meyer: Elementary Graph Algorithms in External Memory. In: Algorithms for Memory Hierarchies: Advanced Lectures (= Lecture Notes in Computer Science). Springer Berlin Heidelberg, Berlin, Heidelberg 2003, ISBN 978-3-540-36574-7, S. 62–84, doi:10.1007/3-540-36574-5_4.
- Lars Arge, Gerth Stølting Brodal, Laura Toma: On external-memory MST, SSSP and multi-way planar graph separation. In: Journal of Algorithms. Band 53, Nr. 2, 1. November 2004, ISSN 0196-6774, S. 186–206, doi:10.1016/j.jalgor.2004.04.001 (sciencedirect.com [abgerufen am 30. Juli 2019]).
- Yi-Jen Chiang, Michael T. Goodrich, Edward F. Grove, Roberto Tamassia, Darren Erik Vengroff: External-memory Graph Algorithms. In: Proceedings of the Sixth Annual ACM-SIAM Symposium on Discrete Algorithms (= SODA '95). Society for Industrial and Applied Mathematics, Philadelphia, PA, USA 1995, ISBN 978-0-89871-349-7, S. 139–149 (acm.org [abgerufen am 30. Juli 2019]).
- Vijay Kumar, Eric J. Schwabe: Improved Algorithms and Data Structures for Solving Graph Problems in External Memory. In: Proceedings of the 8th IEEE Symposium on Parallel and Distributed Processing (SPDP '96) (= SPDP '96). IEEE Computer Society, Washington, DC, USA 1996, ISBN 978-0-8186-7683-3, S. 169– (acm.org [abgerufen am 30. Juli 2019]).