Itemanalyse
Eine Itemanalyse verwendet ein Bündel statistischer Verfahren, um die Eignung einzelner Items, derer Werte beispielsweise durch Fragen einer schriftlichen Umfrage generiert wurden, im Hinblick auf die Zielsetzung der Befragung zu untersuchen.

Ziel ist es dabei, die Qualität einer Skala (Skala bedeutet hier ein Instrument zur Messung bestimmter Variablen, z. B. der politischen Grundeinstellung oder des Umweltbewusstseins der Versuchsperson) durch Überprüfung der Items zu testen und gegebenenfalls zu verbessern. Aufgabe der Itemanalyse ist es somit, die Brauchbarkeit einzelner Items für einen bestimmten Test zu überprüfen.
Die Itemanalyse ist ein zentrales Instrument für die Testkonstruktion und Testbewertung und kommt per Definition dem Wesen der Reliabilität (als Testgütekriterium) am nächsten. Entscheidend für den Test als Gesamtes sind dagegen dessen Gütekriterien und insbesondere die Frage der Validität, d. h., was der Test (d. h. alle Items zusammengenommen) eigentlich messen soll.
Definition
Eine genaue Definition des Begriffs Itemanalyse ist in der Literatur nicht festgelegt. Sie dient zur Bestimmung empirischer psychometrischer Kriterien einzelner Testaufgaben. Meist zählen zur Itemanalyse bei der klassischen Testkonstruktion:
- die Analyse der Rohwertverteilung
- die Berechnung statistischer Kennwerte
- Itemschwierigkeit
- Trennschärfe
- Homogenität sowie die
- Dimensionalitätsprüfung.
Die Analyse wird an einer Stichprobe durchgeführt, die ein Abbild der Population darstellen soll, für die der Test konzipiert wurde. Die Daten der Itemanalyse werden für die Auswahl und Überarbeitung von Items, zu deren Reihung innerhalb des Tests und evtl. für die Konzeption eines Paralleltests verwendet.
Analyse der Rohwertverteilung
Es besteht die Möglichkeit, die Testwerte graphisch darzustellen (z. B. Histogramm). Hierdurch wird ein erster Überblick über die Verteilung der Werte ermöglicht. Im Hauptinteresse steht hierbei die Streuung und die Beantwortung der Frage, ob die Rohwertverteilung einer Normalverteilung entspricht. Da viele inferenzstatistische Verfahren eine Normalverteilung voraussetzen, ist eine dementsprechende Verteilung erwünscht.
Statistische Kennwerte
Itemschwierigkeit
Die Itemschwierigkeit wird durch einen Index gekennzeichnet, der dem Anteil derjenigen Personen entspricht, die das Item richtig lösen oder bejahen (Bortz & Döring, 2005). Früher wurde dieser Index darum auch Popularitätsindex genannt.
Zweck des Schwierigkeitsindexes ist die Unterscheidung von Probanden mit hoher Merkmalsausprägung und Probanden mit niedriger Merkmalsausprägung. Die Fähigkeit eines Items zu dieser Unterscheidung nennt man Trennschärfe. Bei klassischer Testkonstruktion haben Items mit mittlerer Itemschwierigkeit in der Regel die beste Trennschärfe.[1] Unbrauchbar sind extrem ausgedrückt demzufolge alle Items, die von allen Probanden, bzw. Items, die von keinem Probanden gelöst werden konnten oder bejaht wurden. Mit dem Schwierigkeitsindex sollten demnach die Items selektiert werden, die nicht diesen beiden Klassen zugehören. Optimal wird eine Itemschwierigkeit von 50 % angesehen, wobei Items unter 20 % und über 80 % in der Regel ausgeschieden werden.[1] Würde man allerdings nur Items mit einer Itemschwierigkeit von 50 % wählen, hätte man keine gute Differenzierung von Probanden mit niedriger Merkmalsausprägung und auch keine Differenzierung im Bereich hoher Merkmalsausprägungen (Deckeneffekt).[1] Das bedeutet beispielsweise, dass überdurchschnittlich Intelligente alle Aufgaben eines Intelligenztests lösen könnten, wenn er keine so schwierigen Aufgaben enthalten würde, dass nur noch besonders hochbegabte sie lösen können. Es wäre dann nicht mehr möglich, Unterschiede in der Gruppe der Hochbegabten festzustellen. Bei Niveautests sollten die Schwierigkeitsindices über möglichst den ganzen Bereich des gemessenen Merkmals streuen, um einen möglichst großen Anwendungsbereich für den Test zu erhalten. Sind die Itemschwierigkeiten aber sehr unterschiedlich, leidet auch die interne Konsistenz der Skala, sprich durch die Beantwortung eines leichten Items lässt sich nicht vorhersagen, ob ein schwieriges beantwortet wird. Deshalb ist die Konstruktion von Niveautests mit klassischer Testtheorie schwierig.
Schwierigkeitsberechnung bei zweistufigen Antworten (z. B. stimmt/stimmt nicht):

= Zahl der „Richtiglöser“, N = Zahl der Probanden,
p = Schwierigkeitsindex (nur bei zweistufigen Antworten!)

Dies stellt eine Lösung für den einfachsten Fall dar. Sollten Probanden die Aufgabe nicht gelöst haben oder wird vermutet, dass die Antworten teilweise nur „richtig erraten“ wurden, so muss auf andere Lösungsalternativen zurückgegriffen werden (vgl. Fisseni, 1997, 41–42).
Schwierigkeitsberechnung bei mehrstufigen Antworten:
In diesem Fall ist p nicht definiert.
Mögliche Lösung des Problems:
- Dichotomisierung der Item-Scores (z. B. 0 und 1), dann Berechnung als zweistufig mit p.
- Berechnung von Mittelwert und Streuung (Mittelwert äquivalent zu p, jedoch muss die Streuung beachtet werden).
- = Index für mehrstufige Antworten:

vereinfachte Formel:

zur exakteren Berechnung liegen von verschiedenen Autoren verschiedene Berechnungsvorschläge vor (vgl. Fisseni, 2004, 43–45).
Schwierigkeitsunterschiede zwischen zwei Items können über eine Mehrfeldertafel geprüft werden.
Diese Formeln gelten streng genommen nur für reine Niveautests, d. h. solchen, die keine Testzeitbegrenzung vorschreiben und/oder bei denen Probanden alle Aufgaben bearbeiten konnten. Ist Letzteres nicht erfüllt, wie es oftmals bei Leistungstests der Fall ist, darf die Anzahl der „richtigen“ Antworten nicht in Beziehung zur Gesamtzahl der Probanden gesetzt werden, sondern nur der Zahl, die die jeweilige Aufgabe überhaupt bearbeitet hat (vgl. Lienert, 1989).
Trennschärfe
Der Trennschärfe eines Items ist zu entnehmen, wie gut das gesamte Testergebnis aufgrund der Beantwortung eines einzelnen Items vorhersagbar ist (Bortz & Döring, 2005). Eine hohe Trennschärfe bedeutet also, dass das Item zwischen den Probanden im Sinne des Gesamttests zu differenzieren vermag (d. h., Probanden mit hoher Merkmalsausprägung lösen ein Item „richtig“, Probanden mit niedriger dagegen nicht).
Die Trennschärfe wird durch den Trennschärfekoeffizienten dargestellt. Dieser Korrelationskoeffizient zwischen einem Einzelitem und dem Gesamttestscore als Kriterium wird für jedes einzelne Item berechnet und richtet sich nach dem Skalenniveau der Testwerte. Ist der Test-Score intervallskaliert und normalverteilt, so wird als Trennschärfe () die Produkt-Moment-Korrelation zwischen den Werten je Item i und dem korrigierten Gesamtwert t gewählt:


Ist = 0, wird ein Item von Probanden mit hoher wie niedriger Merkmalsausprägung gleichermaßen gelöst. Sofern negative Trennschärfen nicht mit einer Bedeutungsumkehr der Itemformulierung (oder Skala) gerechtfertigt sind, gelten diese Items als unbrauchbar.
A priori sind möglichst hohe absolute Trennschärfen wünschenswert, insbesondere aber für Niveautests. Die Trennschärfe eines jeden Items ist abhängig von seiner Schwierigkeit, der Homogenität bzw. Dimensionalität des Tests, der Stellung des Items innerhalb des Tests und der Reliabilität des Kriteriums. (Als Kriterium kann neben dem Testwert auch ein Außenkriterium herangezogen werden; dann handelt es sich gleichzeitig um einen Validitätskoeffizienten.) Die höchsten Trennschärfen findet man bei Items mit mittlerer Schwierigkeit (vgl. Lienert, 1989).
Homogenität
Die Homogenität gibt an, wie hoch die einzelnen Items eines Tests im Durchschnitt miteinander korrelieren. Bei hoher Homogenität erfassen die Items eines Tests ähnliche Informationen (Bortz & Döring, 2005).

Werden alle k Testitems paarweise miteinander korreliert, ergeben sich Korrelationskoeffizienten (), deren (via Fisher’scher Z-Transformation errechneter) Mittelwert () die Homogenität des Tests beschreibt.



Die Höhe der Iteminterkorrelationen ist abhängig von der Schwierigkeit. Je größer die Schwierigkeitsunterschiede zwischen den Items, desto geringer wird die Interkorrelation, die wiederum die Reliabilität eines Tests beeinflusst. In der Regel werden daher für einen (Sub-)Test entweder unkorrelierte (d. h. heterogene) Items gleicher Schwierigkeit oder positiv korrelierte (d. h. homogene) Items unterschiedlicher Schwierigkeit genutzt (vgl. Lienert, 1989).
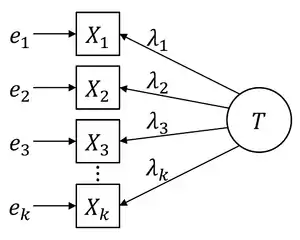
Dimensionalität
Die Dimensionalität eines Tests gibt an, ob er nur ein Merkmal bzw. Konstrukt erfasst (eindimensionaler Test) oder ob mit den Testitems mehrere Konstrukte bzw. Teil-Konstrukte operationalisiert werden (mehrdimensionaler Test) (Bortz & Döring 2005).
Literatur
- Bortz & Döring (2005): Forschungsmethoden und Evaluation. Heidelberg: Springer-Verlag. ISBN 3-540-41940-3
- Fisseni, H.-J. (1997): Lehrbuch der psychologischen Diagnostik. Göttingen: Hogrefe. ISBN 3-8017-0982-5
- Lienert, G. A. (1989): Testaufbau und Testanalyse (4. Aufl.). München: PVU. ISBN 3-621-27086-8
Einzelnachweise
- Hans Dieter Mummendey, Ina Grau: Die Fragebogen-Methode: Grundlagen und Anwendung in Persönlichkeits-, Einstellungs- und Selbstkonzeptforschung. Hogrefe Verlag, 2014, ISBN 978-3-8409-2577-1, S. 97–98 (eingeschränkte Vorschau in der Google-Buchsuche).