External Memory Minimaler Spannbaum
Ein externer minimaler Spannbaum bezeichnet in der Informatik einen minimalen Spannbaum, der für einen in den Sekundärspeicher ausgelagerten Graphen berechnet wurde. Letzteres ist für Graphen nötig, deren Anzahl Knoten und Kanten zu groß ist, als das sie gleichzeitig vollständig in den Hauptspeicher passen. Als Anwendungsbeispiel kann man einen Crawl des sozialen Netzwerkes Twitter aus dem Jahre 2010 heranziehen.[1] Wenn man das Kantengewicht vernachlässigt und eine Kante als Paar von Knotenindizes speichert, so ergibt sich für den Graphen eine Größe von

, was 9,55 Gigabytes entspricht. Wenn man davon ausgeht, dass ein Desktop-PC für gewöhnlich über 8 GB Hauptspeicher verfügt, so würden diese nicht ausreichen, um auf dem Graphen einen minimalen Spannbaum vollständig intern zu berechnen.

Für externe Algorithmen verwendet man als Berechnungsmodell das External Memory Modell. Es besteht aus Hauptspeicher der Größe und Sekundärspeicher und man kann Datenblöcke der Größe zwischen ersterem und letzterem übertragen. Das Lesen (Schreiben) eines Blocks vom (in den) Sekundärspeicher in den (vom) Hauptspeicher, bezeichnet man als I/O (= Input/Output). Letzteres ist die Kerngröße in diesem Modell, die es zu minimieren gilt. Im Gegensatz zu Modellen wie der Random Access Machine steht hier nicht die asymptotische Laufzeit im Vordergrund, sondern die Anzahl I/Os. Aufgrund der deutlich erhöhten Zugriffszeit des Sekundärspeichers, relativ zu der des Hauptspeichers, werden die I/Os oft zum Flaschenhals des Systems.[2]


Semiexterne Berechnung
Eine Einschränkung zur Definition aus der Einleitung bilden semiexterne Algorithmen zur Berechnung minimaler Spannbäume. Jene Algorithmen verarbeiten ungerichtete Graphen, von denen nur die Knoten in den Hauptspeicher passen. Formal ist das durch die Beziehung
gegeben, wobei eine Konstante ist.[3]


Der Algorithmus von Kruskal lässt sich leicht als semiexterne Variante umsetzen.[4] Dazu muss man die Kanten zunächst nach aufsteigendem Gewicht extern sortieren, was sich mithilfe von (die Sortierschranke) I/Os realisieren lässt. Die Union-Find-Struktur lässt sich vollständig im Hauptspeicher verwalten, wodurch sich insgesamt I/Os ergeben.


Externe Berechnung
Falls die Knotenmenge ebenfalls zu groß für den Hauptspeicher ist, so lässt sich ein minimaler Spannbaum durch externe Algorithmen berechnen.
Algorithmus von Prim
Der Algorithmus von Prim kann mithilfe einer externen Prioritätswarteschlange als externer Algorithmus ausgeführt werden.[5] Sie speichert die Kanten des Graphen, wobei als Priorität deren Gewichte genommen werden. Der Algorithmus wählt iterativ die Kante geringsten Gewichts aus und fügt sie zum bisherigen minimalen Spannbaum hinzu. Die leichteste Kante erhält man durch eine extractMin()-Operation der Warteschlange. Im Folgenden ist der Algorithmus in Pseudocode beschrieben (es ist zu beachten, dass die gerichteten Kanten von betrachtet werden).

c: Gewichtsfunktion der Kanten
s V(G): beliebiger Startknoten
Adj: adjazenten Knoten eines Knoten
Inc: inzidente Kanten eines Knoten

external_prim(G,c,s): 01 T // T = (V,E): Knoten und Kanten des zu berechnenden MST 02 Q leere externe Prioritätswarteschlange 03 für alle e Adj(s) 04 Q.insert(e, c(e))05 solange Q nicht leer 06 (u,v) Q.extractMin()07 wenn v nicht Teil von T 08 V(T) V(T) {v} 09 E(T) E(T) {(u,v)} 10 für alle e Inc(v) \ {(v,u)} // denn (u,v) ist schon aufgenommen worden 11 Q.insert(e, c(e))12 return T



Es wird angenommen, dass die Kantengewichte paarweise verschieden sind. So kann man die Überprüfung in Zeile 7, ob der v Knoten bereits im Spannbaum enthalten ist, leicht realisieren. Man muss dazu lediglich überprüfen, ob die nächste Kante minimalen Gewichts gleich (u,v) (aus Zeile 6) ist, was nur eine zusätzliche extractMin()-Operation der Warteschlange Q erfordert. Denn jeder Knoten fügt seine inzidenten Kanten in Q ein und falls v schon Teil des Spannbaums sind, so befindet sich die Kante (v,u) ebenfalls in Q. Darin muss diese Kante aber der unmittelbare Nachfolger von (u,v) sein, da nach Annahme keine zwei Kanten dasselbe Gewicht haben.
Die gesamte I/O-Komplexität umfasst I/Os.[5] Zunächst werden für jeden Knoten dessen adjazente Knoten ausgelesen, was bei Umsetzung per Adjazenzliste I/Os erfordert. Der Algorithmus verarbeitet weiterhin alle Kanten von und führt pro Kante höchstens zwei Operationen der Warteschlange aus. Wenn man davon ausgeht, dass die Warteschlange Operationen mit I/Os unterstützt, dann beträgt die Gesamtkomplexität I/Os.




Kantenreduktion
Ein anderer Ansatz ist es iterativ Kanten des minimalen Spannbaumes zu identifizieren, sodass man diese entfernen kann. Das führt man solange fort, bis der resultierende Graph ausreichend dicht ist. Ist der Graph ausreichend dicht, so fällt die Komplexität für das Berechnen des minimalen Spannbaumes auf dem verbleibenden Graphen insgesamt nicht mehr ins Gewicht.[6]
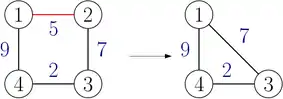



Konkret will man die Anzahl Knoten auf mindestens reduzieren, um dann auf dem resultierenden Graphen den Algorithmus von Prim laufen zu lassen, wodurch sich dessen Komplexität zu I/Os vereinfacht.

Die Reduktion entstammt dem Algorithmus von Borůvka, weswegen der folgende Ablauf auch Boruvka-Phase genannt wird: für jeden Knoten wählt man die leichteste adjazente Kante aus, welche Teil des minimalen Spannbaums sein muss. Anschließend kontrahiert man jede solche Kante, sodass sich die Anzahl Knoten mindestens halbiert. Bei der Kontraktion können neue Kanten entstehen, sodass man für diese Verweise auf dessen ursprüngliche Kante speichern muss. Letzteres ist nötig, um am Ende einen minimalen Spannbaum für den ursprünglichen Graphen konstruieren zu können.
Insgesamt sind dafür Phasen nötig. Eine einzelne Phase lässt sich mit I/Os implementieren[7], sodass sich insgesamt I/Os ergeben.[8] Die Maximumsbildung in der Komplexität rührt daher, dass mindestens eine Boruvka-Phase nötig ist.


Randomisierter Sweep
Anstatt den deterministischen Verfahren kann man die Berechnung auch randomisiert durchführen.[9] Die Idee ist es die Anzahl Knoten solange zu reduzieren, bis man auf dem verbleibenden Graphen einen semiexternen Algorithmus ausführen kann. Die Reduktion wird ebenfalls durch Kantenkontraktion, wie oben beschrieben, umgesetzt. Dabei wird iterativ ein zufälliger Knoten ausgewählt und nur dessen leichteste Kante kontrahiert, nachdem sie in den minimalen Spannbaum aufgenommen wurde.
Ein Problem ergibt sich, wenn die zufällige Auswahl direkt umgesetzt wird: für jeden Knoten fällt ein I/O an, da auf die Knoten in willkürlicher Reihenfolge zugegriffen wird. Man kann dem entgegnen, indem man stattdessen eine zufällige Permutation der Knotenindizes erstellt und die Knoten nach deren neu zugewiesenen Indizes absteigend abarbeitet (= Sweeping).
Auch hier wird wieder eine externe Prioritätswarteschlange benutzt, welche die Kanten des Graphen speichert. Als Priorität wird der größere Knotenindex der Kante gewählt, wobei bei zwei gleichen Indizes die Kante mit kleinerem Gewicht die höhere Priorität bekommt. Dadurch kann man effizient die zu einem Knoten inzidente leichteste Kante bestimmen. Durch die Sortierung nach Knotenindizes und weil in jedem Schritt von einem Knoten nur die leichteste Kante betrachtet wird, lässt sich die Kantenkontraktion ohne weiteres umsetzen. Dazu wird in der nächsten Iteration die Kante als Kante mit selbem Gewicht in die Warteschlange eingefügt.




Die erwartete Anzahl betrachteter Kanten, bis die Anzahl Knoten auf reduziert wurde, beträgt .[9] Damit werden insgesamt Operationen auf der Warteschlange ausgeführt und es ergeben sich insgesamt I/Os.[10]



Literatur
Einzelnachweise
- What is Twitter, a Social Network or a News Media? Abgerufen am 26. Juli 2019.
- Jeffrey Scott Vitter: Algorithms and Data Structures for External Memory. (PDF) S. 3, abgerufen am 31. Juli 2019.
- Algorithms for Memory Hierarchies. In: Lecture Notes in Computer Science. 2003, ISSN 0302-9743, S. 65, doi:10.1007/3-540-36574-5 (springer.com [abgerufen am 18. Juli 2019]).
- Abello, Buchsbaum, Westbrook: A Functional Approach to External Graph Algorithms. In: Algorithmica. Band 32, Nr. 3, 1. März 2002, ISSN 1432-0541, S. 8, doi:10.1007/s00453-001-0088-5.
- Lars Arge, Gerth Stølting Brodal, Laura Toma: On external-memory MST, SSSP and multi-way planar graph separation. In: Journal of Algorithms. Band 53, Nr. 2, 1. November 2004, ISSN 0196-6774, S. 190–191, doi:10.1016/j.jalgor.2004.04.001 (sciencedirect.com [abgerufen am 18. Juli 2019]).
- Algorithms for Memory Hierarchies. In: Lecture Notes in Computer Science. 2003, ISSN 0302-9743, S. 77, doi:10.1007/3-540-36574-5 (springer.com [abgerufen am 18. Juli 2019]).
- Lars Arge, Gerth Stølting Brodal, Laura Toma: On external-memory MST, SSSP and multi-way planar graph separation. In: Journal of Algorithms. Band 53, Nr. 2, 1. November 2004, ISSN 0196-6774, S. 192–193, doi:10.1016/j.jalgor.2004.04.001 (sciencedirect.com [abgerufen am 18. Juli 2019]).
- Algorithms for Memory Hierarchies. In: Lecture Notes in Computer Science. 2003, ISSN 0302-9743, S. 81, doi:10.1007/3-540-36574-5 (springer.com [abgerufen am 18. Juli 2019]).
- Roman Dementiev, Peter Sanders, Dominik Schultes, Jop Sibeyn: Engineering an External Memory Minimum Spanning Tree Algorithm. In: Exploring New Frontiers of Theoretical Informatics (= IFIP International Federation for Information Processing). Springer US, 2004, ISBN 978-1-4020-8141-5, S. 195–208, doi:10.1007/1-4020-8141-3_17 (springer.com [abgerufen am 25. Juli 2019]).
- Peter Sanders: Vorlesung "Algorithm Engineering" SS19. (PDF) S. 279, abgerufen am 31. Juli 2019.