Elasticsearch
Elasticsearch ist eine Suchmaschine auf Basis von Lucene. Das in Java geschriebene Programm speichert Dokumente in einem NoSQL-Format (JSON). Die Kommunikation mit Klienten erfolgt über ein RESTful-Webinterface. Elasticsearch ist neben Solr der am weitesten verbreitete Suchserver.[4] Er ermöglicht auf einfache Weise den Betrieb im Rechnerverbund zur Umsetzung von Hochverfügbarkeit und Lastverteilung.[5]
| Elasticsearch | |
|---|---|
| Basisdaten | |
| Entwickler | Elastic |
| Erscheinungsjahr | 2010 |
| Aktuelle Version | 7.16.3[1] (13. Januar 2022) |
| Betriebssystem | plattformunabhängig |
| Programmiersprache | Java |
| Kategorie | Suchserver |
| Lizenz | Server Side Public License[2][3], Elastic License[2][3] |
| www.elastic.co/elasticsearch | |
Lizenzierung
Der Vertrieb durch das Unternehmen Elastic NV folgte dem „Open Core“-Model, das heißt, der Kern der Software unterlag Open-Source-Lizenzen (hauptsächlich Apache License 2.0), andere Teile standen unter der kommerziellen Elastic License.[6]
OpenSearch (Abspaltung)
Im Januar 2021 kündigte Elastic an, den Apache 2.0 lizenzierten Code in Elasticsearch und Kibana neu zu lizenzieren: Ab der Version 7.11 wird dieser unter der Doppellizenz Server Side Public License und der Elastic License angeboten (vgl. MongoDB#Lizenzierung und Unterstützung).[7][8] Elastic machte daraufhin Amazon Web Services für diese Änderung verantwortlich und beanstandete deren Verwendung von Elasticsearch in der Vergangenheit.[9][10] Einen Tag darauf kündigte sich eine Abspaltung an, welche das Projekt unter der freien Apache-Lizenz weiterführen möchte.[11][12] Im April 2021 veröffentlichten AWS, Logz.io, Red Hat, SAP und Capital One diese Abspaltung unter dem Namen OpenSearch auf GitHub.[13][14]
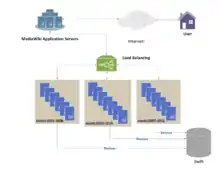
Physischer Aufbau
Elasticsearch zerteilt jeden Index in mehrere Stücke, so genannte shards (Scherben, Bruchstücke). Die shards eines Indexes können vom Anwender bei Bedarf auf mehrere Server (nodes) aufgeteilt werden (die Gruppe heißt cluster), um die Rechenlast zu verteilen oder um Serverausfälle zu kompensieren. Läuft die Suchmaschine auf mehreren nodes, so wird einer als master node der Gruppe bestimmt.
Ein shard ist ein Lucene-Index. Elasticsearch nutzt Apache Lucene für die Indexierung und Suche als core library. Ein Elasticsearch-Index besteht also aus mehreren Lucene-Indizes. Ein Lucene-Index besteht aus einem Ordner mit Dateien, die einen invertierten Index beinhalten.
Funktionsweise
Dokumente, Typen und Indizes
Die kleinste Einheit, mit der gearbeitet wird, sind Dokumente (englisch documents). Jedes Dokument, das durchsucht werden soll, muss zuvor indiziert werden. Sollen beispielsweise Informationen zu Büchern durchsuchbar gemacht werden, könnten die Informationen über jedes einzelne Buch in jeweils ein Dokument geschrieben werden, welches anschließend indexiert werden muss. Ein Index entspricht dabei in etwa einer SQL-Tabelle, ein Dokument einer Zeile dieser Tabelle. Jedoch sind die Anzahl und Typen der Felder nicht notwendigerweise starr vorgegeben, können aber bei Bedarf durch eine Typzuweisung (englisch mapping) explizit typisiert werden.
Um indiziert werden zu können, müssen die Dokumente im JSON-Format an Elasticsearch gesendet werden. Als JSON-Dokumente bestehen sie jeweils aus einem Satz an Paaren von Schlüsseln und Werten. Ein Beispiel für ein Dokument, das ein Buch beschreiben soll:
{
"titel": "Granatenstarke Suchmaschinentechnologie",
"autor": "Michael Käfer",
"erscheinungsjahr": "1794",
"verlag": "Müller-Verlag"
}
Suchanfragen
Auch die Suchanfragen (englisch queries) werden als JSON-Dokumente an Elasticsearch gesendet. Obiger Beispieldatensatz würde beispielsweise von folgender Suchanfrage gefunden werden:
{
"query": {
"match": {
"titel": "suchmaschinentechnologie"
}
}
}
Der wichtigste Bestandteil einer Suchanfrage ist der Parameter query (sein Inhalt bestimmt, welche Dokumente in welcher Reihenfolge gefunden werden sollen), weitere sind die Parameter size (bestimmt die maximale Anzahl an Treffern), from (dient der Aufteilung langer Trefferlisten auf mehrere Seiten), _source (ermöglicht es, nicht ganze Dokumente als Resultate zu erhalten, sondern nur bestimmte Felder dieser Dokumente) und sort (ermöglicht eine alternative, vom Benutzer definierbare Sortierung der Ergebnisse).
Einer Anfrage (query) können verschiedene Parameter zugeteilt werden. Einige Beispiele:
"match_all": { }
|
|
"match": {
"titel": "granatenstarke"
}
|
|
"multi_match": {
"query": "granatenstarke",
"_source": ["titel","autor"]
}
|
|
"bool": {
"must": {
"match": {"titel": "quick"}
},
"must_not": {
"match": {"titel": "lazy"}
},
"should": {
"match": {"titel": "brown"},
"match": {"titel": "green"}
}
}
|
|
Kommunikation mit der REST-API
Sowohl für die Indexierung der JSON-Dateien als auch für Suchanfragen wird mit der REST-API von Elasticsearch kommuniziert. Es gibt verschiedene Möglichkeiten, diese Kommunikation durchzuführen. Die am weitesten verbreitete und am besten dokumentierte ist, Dokumente und Suchanfragen mit Verwendung des Programms cURL an die REST-API zu senden. Weiter bieten sich verschiedene Programme an (etwa Postman), die benutzerfreundlich zu dieser Art der Kommunikation fähig sind, aber auch die Kommunikation über selbst erstellte Skripte in den gängigen Programmiersprachen. Ein Beispiel, in dem das obige JSON-Dokument mit cURL über ein Terminal an den Server gesendet wird, auf dem Elasticsearch läuft:
curl -X PUT '78.47.143.252:9200/materialienzusuchmaschinen/buecher/1?pretty' -d '{
"titel": "Granatenstarke Suchmaschinentechnologie",
"autor": "Michael Käfer",
"erscheinungsjahr": "1794",
"verlag": "Müller Verlag"
}'
Dem Index, in den das Dokument geladen wird, gibt man in diesem Beispiel den Namen „materialienzusuchmaschinen“, dem Typ den Namen „buecher“. Sind ein Index und ein Typ dieses Namens nicht ohnehin bereits vorhanden, so werden sie automatisch neu erstellt. Das gesendete Dokument wird unter der hier ebenfalls angegebenen ID „1“ abgelegt.
Indexierung
Schickt man ein Dokument zur Indexierung, startet Elasticsearch einen Analyseprozess (englisch analysis), während das Dokument für den Index aufbereitet wird. Dabei wird der zu indexierende Text des Dokuments umgewandelt, damit später die daraus gewonnenen Resultate in den Index geschrieben werden können. Zuerst wird der Text an definierten Stellen (wie Leerzeichen oder Kommas) in die einzelnen Wörter zerbrochen (etwa „Granatenstarke Suchmaschinentechnologie“ in „Granatenstarke“ und „Suchmaschinentechnologie“). Die Buchstaben jedes einzelnen dieser Wörter werden anschließend vollständig in Kleinbuchstaben umgewandelt (etwa „Granatenstarke“ in „granatenstarke“). Es folgen noch weitere Schritte; darüber hinaus ist es möglich, auch eigene Umwandlungsstufen einzubauen.
Zum einen speichert Elasticsearch die Resultate des Analyseprozesses (etwa „granatenstarke“) im Index ab, zum anderen werden auch die ursprünglich geschickten Originaldokumente an einem anderen Ort gespeichert.
Literatur
- Radu Gheorghe, Matthew Lee Hinman, Roy Russo: Elasticsearch in Action, Version 17. Manning, 2015, ISBN 978-1-61729-162-3
- Clinton Gormley, Zachary Tong: Elasticsearch. The definitive guide. 1. Auflage. O’Reilly, 2015, ISBN 978-1-4493-5854-9
Einzelnachweise
- github.com. 13. Januar 2022 (abgerufen am 26. Januar 2022).
- Upcoming licensing changes to Elasticsearch and Kibana. 14. Januar 2021.
- github.com.
- DB-Engines Ranking of Search Engines, Stand April 2016
- Oliver B. Fischer: Volltextsuche mit ElasticSearch. In: heise Developer. 26. Juli 2013, abgerufen am 6. Juni 2015.
- Open Source, Distributed, RESTful Search Engine. Contribute to elastic/elasticsearch development by creating an account on GitHub. elastic, 14. März 2019, abgerufen am 14. März 2019.
- Elastic: Doubling down on open, Part II. In: elastic.co. 14. Januar 2021, abgerufen am 21. Januar 2021 (deutsch).
- Suchmaschine Elasticsearch beendet freie Lizenzierung. In: heise online. 15. Januar 2021, abgerufen am 21. Januar 2021.
- Elastic: Amazon: NOT OK - why we had to change Elastic licensing. In: elastic.co. 19. Januar 2021, abgerufen am 21. Januar 2021.
- Elastic: Amazon ist schuld am Open-Source-Ende. In: heise online. 20. Januar 2021, abgerufen am 21. Januar 2021.
- Truly Doubling Down on Open Source. In: logz.io. 20. Januar 2021, abgerufen am 21. Januar 2021 (englisch).
- Elastic: Jetzt kommt der Fork. In: heise online. 21. Januar 2021, abgerufen am 21. Januar 2021.
- OpenSearch gegen Elasticsearch: Amazons Fork-Klatsche. In: heise online. 13. April 2021, abgerufen am 14. April 2021.
- OpenSearch auf GitHub