C4.5
C4.5 ist ein Algorithmus des maschinellen Lernens, der verwendet wird, um aus Trainingsdaten einen Entscheidungsbaum zu erzeugen, mit dem Datensätze klassifiziert werden können.[1] Er wurde als Erweiterung des ID3-Algorithmus von Ross Quinlan entwickelt.[2]
Neben den bekannten CARTs und CHAIDs gewinnt C4.5 immer mehr an Bedeutung. Er wird mittlerweile bereits von verschiedenen Softwarepaketen eingesetzt.
Grundsätzlich verhält sich dieser Algorithmus ähnlich wie der CART-Algorithmus. Der Hauptunterschied besteht darin, dass bei C4.5 keine binäre Aufteilung erfolgen muss, sondern eine beliebige Anzahl Verzweigungen eingebaut werden können. Der Baum wird breiter. Er ist meist weniger tief als der korrespondierende CART-Baum. Dafür werden nach der ersten Klassifizierung die nachfolgenden Aufsplittungen weniger bedeutungsvoll.
Ein weiterer Unterschied zeigt sich beim sogenannten Pruning, beim Stutzen des Baumes. CART erzeugt einige Subtrees und testet diese mit neuen, vorher noch nicht klassifizierten Daten. C4.5 hingegen beschneidet den Baum ohne Beachtung der gegebenen Datenbasis.
Algorithmus
C4.5 generiert aus Trainingsdaten einen Entscheidungsbaum, mit dem zukünftige Instanzen, die nicht in den Trainingsdaten enthalten waren, klassifiziert werden können. Dabei wird, ähnlich wie beim ID3-Algorithmus, die Berechnung der Entropie verwendet, um die Reihenfolge der Entscheidungsknoten in deren Abstand zum Wurzelknoten innerhalb des zu generierenden Entscheidungsbaumes zu bestimmen.
Ablauf
Die Trainingsdaten seien eine Menge , bestehend aus den bekannten Trainingsbeispielen. Jedes Trainingsbeispiel dieser Menge sei ein p+1-dimensionaler Vektor aus den zu erlernenden Merkmalen (Instanz) und der zu erlernenden Zielklassifikation : . Bei der Erzeugung des obersten Knotens im Entscheidungsbaum sucht C4.5 nach dem ersten Entscheidungsmerkmal. Zu dessen Bestimmung vergleicht C4.5 für jedes Merkmal die Effizienz, mit der die Trainingsdatenmenge unter diesem Merkmal aufgeteilt würde, und entscheidet sich für das beste. Als Kriterium gilt dabei der durch das Merkmal zu erreichende höchste Zugewinn an Information (Kullback-Leibler-Divergenz). Die Trainingsdaten werden daraufhin in Teilmengen gemäß ihren Werten des ausgewählten Merkmales aufgeteilt, für die jeweils ein Ast unterhalb des Wurzelknotens entsteht. Der Algorithmus wird rekursiv fortgeführt, indem der bisherige Ablauf erneut für jeden dieser Äste unter Einschränkung der diesem Ast zugeordneten Teilmenge der Trainingsdaten angewandt wird. Wenn an einem Ast kein Zugewinn an Information durch eine weitere Unterteilung der Trainingsdaten möglich ist, entsteht an diesem Ast ein Blatt mit der verbleibenden Zielklassifikation. Der höchst mögliche maximale Grad des Baumes beträgt somit .






Beispiel
Sarah geht an einigen Tagen segeln, an anderen Tagen nicht. Ob sie an einem bestimmten Tag segeln geht, sei vorwiegend von den folgenden Merkmalen abhängig: Wetterlage (sonnig / bedeckt / regnerisch); Temperatur; Luftfeuchtigkeit; Windstärke (leicht / stark). An 14 zufälligen Tagen wurden diese Daten zusammen mit der Information, ob Sarah segeln geht, erfasst:
| Wetterlage | Temperatur in °C | Luftfeuchtigkeit in % | Windstärke | Sarah geht segeln |
|---|---|---|---|---|
| Sonnig | 29 | 85 | Leicht | Falsch |
| Sonnig | 27 | 90 | Stark | Falsch |
| Bedeckt | 28 | 78 | Leicht | Wahr |
| Regnerisch | 21 | 96 | Leicht | Wahr |
| Regnerisch | 20 | 80 | Leicht | Wahr |
| Regnerisch | 18 | 70 | Stark | Falsch |
| Bedeckt | 17 | 65 | Stark | Wahr |
| Sonnig | 22 | 95 | Leicht | Falsch |
| Sonnig | 21 | 70 | Leicht | Wahr |
| Regnerisch | 24 | 80 | Leicht | Wahr |
| Sonnig | 24 | 70 | Stark | Wahr |
| Bedeckt | 22 | 90 | Stark | Wahr |
| Bedeckt | 27 | 75 | Leicht | Wahr |
| Regnerisch | 21 | 80 | Stark | Falsch |
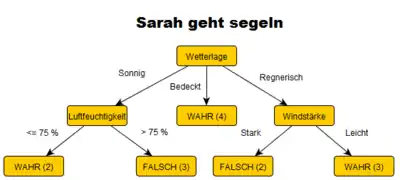
Maschinelles Lernen soll eingesetzt werden, um den Zusammenhang zwischen den vier tagesbedingten Merkmalen und der Aussage, ob Sarah segeln geht, aufzudecken. Hat man einmal diesen Zusammenhang ermittelt, dann lässt sich auch für beliebige andere Tage bei Kenntnis der Wetterdaten bestimmen, ob Sarah segeln geht. C4.5 generiert aus den in der Tabelle gegebenen Trainingsdaten den abgebildeten Entscheidungsbaum. Die Zahlen in den Klammern geben die Anzahl der Trainingsdatensätze an, die diesem Pfad entsprechen.
Verbesserungen gegenüber ID3
Als Erweiterung des ID3-Algorithmus bietet C4.5 einige Verbesserungen:
- Anwendbarkeit sowohl auf diskrete als auch auf kontinuierliche Attribute – Enthalten die Datensätze beispielsweise eine reelle Größe als eines der Merkmale, so werden die Merkmalswerte in diskrete Intervalle eingeordnet.
- Anwendbarkeit auf Trainingsdaten mit fehlenden Attributswerten – Unter Anwendung von C4.5 können nicht verfügbare Merkmalswerte als unbekannt (?) markiert werden. Unbekannte Werte werden bei der Berechnung des Information Gain einfach ignoriert.
- Mögliche Kostengewichtung der Attribute – Aufwändig zu bestimmenden Merkmalen kann eine höhere Kostengewichtung zugeordnet werden. Merkmale mit hohen Kostengewichtungen werden tendenziell weiter unten im Entscheidungsbaum als Verzweigungen angeordnet, sodass für weniger Klassifizierungen dieses Merkmal überhaupt bestimmt werden muss. Beispielsweise könnte die Anwendung von C4.5 zur Krankheitsdiagnostizierung unter der Datenbasis von Symptomen und medizinischen Untersuchungswerten so angepasst werden, dass kostenintensive Untersuchungen eher vermieden werden und möglichst nur im Zweifelsfall zwischen mehreren möglichen Diagnosen zum Einsatz kommen.
- Stutzen (Pruning) des Entscheidungsbaumes nach dessen Erstellung – Um die Anzahl der möglichen Ergebnisklassen der Klassifizierung zu verringern, schneidet C4.5 lange Äste ab. Dies verhindert außerdem Überanpassung an die Trainingsdaten.
Siehe auch
Einzelnachweise
- Tom M. Mitchell: Machine Learning, 1997
- Quinlan, J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers, 1993.