String-Matching-Algorithmus
In der Informatik sind String-Matching-Algorithmen eine Gruppe von Algorithmen, die das Finden von Textsegmenten in einer Zeichenkette (englisch string) anhand eines vorgegebenen Suchmusters beschreiben. Sie zählen somit zur Klasse der Zeichenkettenalgorithmen.
Im engeren Sinne suchen diese Algorithmen nach exakten Übereinstimmungen (englisch matches). Im weiteren Sinne sind auch Algorithmen gemeint, die ungefähre Übereinstimmungen zulassen, wobei der Begriff ungefähr durch ein Toleranzkriterium genau definiert sein muss.
Das Problem besteht darin, diese Aufgabe möglichst effizient zu lösen. In der Praxis ist dies bedeutsam, wenn in großen Textmengen (wie z. B. einer Wikipedia) Suchbegriffe gefunden werden sollen.
Exakte Suche
Problemstellung
Grundsätzlich sind zwei Situationen zu unterscheiden:
- Nach Vorgabe einer Suchmaske sollen beliebige Texte durchsucht werden.
- Der Text ist vorgegeben, und dann sollen beliebige Suchmasken im Text gefunden werden.
Der zweite Fall entspricht etwa der Aufgabe, die Wikipedia derart aufzubereiten, dass beliebige Suchmasken schnell und effizient aufgefunden werden. Auch Suchmaschinen im Internet finden sich in der zweiten Situation.
Im Folgenden wird jedoch nur auf die erste Situation eingegangen.
Naiver Algorithmus
Der einfachste Algorithmus besteht darin, ein so genanntes Suchfenster von der Länge der Suchmaske über den Text zu schieben. In jeder Position der Suchmaske werden die Symbole der Maske mit denen des darunterliegenden Textes verglichen. Wenn ein nicht übereinstimmendes Symbol gefunden wird, wird das Fenster um eine Position verschoben, und erneut ein Vergleich angestellt; wenn alle Symbole im Fenster übereinstimmen, ist die Suchmaske gefunden worden. Der Algorithmus endet, wenn der ganze Text vom Fenster abgesucht worden ist.
Dieser Algorithmus hat eine Laufzeit von der Ordnung , wenn m die Länge der Suchmaske und n die Länge des Textes ist.

Pseudocode:
Eingabe: Strings T = T1… Tn und P = P1 … Pm Ausgabe: q die Stellen an denen P in T auftritt
for q = 0 to n – m do
if P[1] = T[q+1] and P[2] = T[q+2] and … and P[m] = T[q+m] then
write q
Überraschenderweise ist der naive Ansatz in der Praxis sehr schnell, da Fehler in natürlichsprachigen Texten nach 1 bis 2 Zeichen auftauchen. Für die englische Sprache ergibt sich eine Wahrscheinlichkeit von 1.07 Zeichen. Somit ist der naive Ansatz nahezu linear schnell.
Dies wird auch deutlich wenn man sich den ungünstigsten Fall selbst ansieht. Er lautet
Text: aaa...aab Muster: ab
Derartige Fälle sind in natürlich sprachlichen Texten äußerst unwahrscheinlich.
Endlicher Automat
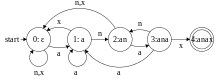
Bei dem String-Matching-Algorithmus mit Hilfe von endlichen Automaten wird ein für ein Alphabet und ein gegebenes Suchmuster der Länge ein Automat mit Zustandsmenge erstellt. Dabei stellt die Anzahl von übereinstimmenden Buchstaben an der aktuellen Stelle vom Anfang des Suchmusters an betrachtet dar. Zur Einfachheit sei das Präfix des Suchmusters bis einschließlich des Buchstabens an der Stelle . Die Übergangsfunktion mit gibt nun für wieder einen Zustand zurück, bei dem die maximale Anzahl von Buchstaben darstellt, mit der ein Suffix vom Wort ist. Also . Ist das Suchmuster gefunden, wird im Endzustand verharrt, also .















Der Vorteil dieses Algorithmus gegenüber dem naiven Algorithmus liegt darin, dass er auch beim finden eines nicht-passenden Zeichens das erlangte Wissen über den bereits verarbeiteten Teil der Zeichenkette nicht verwirft. Angenommen, wir suchen das Muster anax im Text ananax. Trifft der automatenbasierte Algorithmus bei der Suche auf das Zweite n in ananax, so wird er die ersten beiden Buchstaben verwerfen und beginnend mit ananax weitersuchen. Der naive Algorithmus hingegen hätte den kompletten bereits verarbeiteten Teil verworfen und hätte beginnend mit ananax einen nächsten Versuch begonnen.
Python-Implementation
def is_suffix(suffix, word):
'''Überprüft ob das suffix ein Suffix von word ist.'''
return word.endswith(suffix)
def transition(pattern, state, event):
'''Hier wird die Übergangsfunktion berechnet.'''
for k in range(state + 1, 0, -1):
if is_suffix(pattern[:k], pattern[:state] + event):
return k
return 0
def create_matcher(alphabet, pattern):
'''Erzeugt alle Zustände und eine Übergangsfunktions-Tabelle'''
transition_table = {}
for state in range(0, len(pattern) + 1):
for event in alphabet:
transition_table[(state, event)] = \
transition(pattern, state, event)
return transition_table, len(pattern)
def match(matcher, text):
'''Gibt die gefundenen Treffer im Text mit dem Automaten der aus create_matcher
erstellt wurde.'''
transition_table, last_state = matcher
matches = []
state = 0
text_pos = 0
for text_pos in range(0, len(text)):
state = transition_table[(state, text[text_pos])]
if state == last_state:
matches.append(text_pos - last_state + 1)
return matches
def find(alphabet, pattern, text):
matcher = create_matcher(alphabet, pattern)
return match(matcher, text)
Der Knuth-Morris-Pratt-Algorithmus
Der Knuth-Morris-Pratt-Algorithmus baut auf dem naiven Suchalgorithmus auf. Wesentlicher Unterschied ist, dass das Vergleichsfenster nicht immer um nur eine Position weitergerückt wird, sondern eventuell um mehr als eine Position.
Dazu muss zu Anfang die Suchmaske analysiert werden, so dass bei jeder teilweisen Übereinstimmung, etwa der ersten k Symbole, bekannt ist, ob der Anfang der Suchmaske mit dem Ende der letzten übereinstimmenden Teilmaske übereinstimmt. Die Verschiebung der Suchmaske erfolgt nach der überlappenden Übereinstimmung; zusätzlicher Vorteil ist, dass die schon verglichenen Symbole nicht noch einmal verglichen werden müssen.
Suche im Suffixbaum
Insbesondere wenn der zu durchsuchende Text im Voraus bekannt ist, und in diesem später nach vielen unterschiedlichen Mustern gesucht werden soll, bietet sich die Konstruktion eines Suffixbaums an. Diese Konstruktion kann in erfolgen. Anschließend kann jedes Muster ohne erneute Vorbereitung des Texts in gesucht werden: Sofern es vorhanden ist, kann man von der Quelle des Suffixbaums den entsprechenden Knoten erreichen, ansonsten schlägt die Suche fehl (es ist kein entsprechender Knoten vorhanden).[1]


Übersicht
| Algorithmus | Vorbereitungszeit | Suchzeit |
|---|---|---|
| Naiver Algorithmus | (keine) | |
| Rabin-Karp-Algorithmus | average , worst | |
| Endlicher Automat | ||
| Knuth-Morris-Pratt-Algorithmus | ||
| Boyer-Moore-Algorithmus[2] | average , worst | |
| Shift-Or-Algorithmus | ||
| Suche im Suffixbaum |









Wobei m die Länge der Suchmaske und n die Länge des Textes ist.
Weitere Algorithmen
- Skip-Search-Algorithmus
- Baeza-Yates-Gonnet-Algorithmus (Shift-Or oder Shift-And)
- BNDM (Backward Nondeterministic Dawg Matching)
- BOM (Backward Oracle Matching)
Multi-String-Matching
Die Suche nach mehreren Mustern in einem Text nennt sich Multi-String-Matching[3]. Die meisten Algorithmen sind abgeleitet von einem entsprechenden String-Matching Algorithmus für genau ein Muster. Eine besondere Herausforderung bei der Suche nach mehreren Suchwörtern ist die Behandlungen von Wort-Überlappungen.
Liste von Algorithmen
| Multi-String-Algorithmus | passender Single-String-Algorithmus |
|---|---|
| Multi-Shift-And | Shift-And |
| Aho-Corasick | Knuth-Morris-Pratt |
| Commentz-Walter | Boyer-Moore |
| Set-Horspool | Horspool |
| Wu-Manber | Horspool/Rabin-Karp |
| Set-BOM | BOM |
Mustervergleichssuche
Die Suche nach Mustern ist zwischen unscharfer und exakter Suche anzusiedeln, da der Benutzer explizit angeben muss, welchen Spielraum er für bestimmte Zeichenklassen an bestimmten String-Positionen zulässt.
Unscharfe Suche
Bei der unscharfen Suche entscheidet üblicherweise der Algorithmus nach Vorgabe eines Güte- oder Abstandskriteriums, wie groß die Abweichung von Treffern gehen darf.
Diese Form der Suche umfasst auch Suchen nach gleichlautenden Wörtern in einem Text (phonetische Suche). Beispiele von Algorithmen sind:
Siehe auch
- Suchverfahren
- Levenshtein-Distanz (approximative Suche)
- Gestalt Pattern Matching (approximative Suche)
- Volltextrecherche
Weblinks
- Java-Animationen, die die Funktionsweise so gut wie aller exakten Suchalgorithmen veranschaulichen
- StringSearch – high-performance pattern matching algorithms in Java – Implementierungen vieler String-Matching-Algorithmen in Java (BNDM, Boyer-Moore-Horspool, Boyer-Moore-Horspool-Raita, Shift-Or)
- StringsAndChars – Implementierungen von String-Matching-Algorithmen für ein und mehrere Muster in Java.
- einfache und ausführliche Erklärung des Boyer-Moore-Algorithmus
Einzelnachweise
- Dan Gusfield: Algorithms on Strings, Sequences and Trees. 1997, ISBN 0-521-58519-8, Kapitel 7.1.APL1 (1999 korrigierte Ausgabe).
- R. S. Boyer, J. S. Moore: A fast string searching algorithm. In: Communications of the ACM. 20, 1977, S. 762–772. doi:10.1145/359842.359859.
- Gonzalo Navarro, Mathieu Raffinot: Flexible Pattern Matching Strings: Practical On-Line Search Algorithms for Texts and Biological Sequences. 2008, ISBN 0-521-03993-2.