Samplesort
Samplesort ist ein Sortieralgorithmus, der 1970 von W. D. Frazer und A. C. McKellar in der wissenschaftlichen Publikation Samplesort: A Sampling Approach to Minimal Storage Tree Sorting veröffentlicht wurde. Der Algorithmus arbeitet ähnlich wie Quicksort und verfolgt wie dieser das Teile-und-herrsche-Verfahren. Der Algorithmus teilt die Eingabesequenz in mehrere Teilsequenzen auf, die dann rekursiv sortiert werden.
Pseudocode
Der folgende Pseudocode stellt die Arbeitsweise des Algorithmus grundlegend dar.[1] Dabei enthält die zu sortierenden Daten, entspricht dem Oversamplingfaktor und der Anzahl der zu nutzenden Splitter. Die Anzahl der Splitter gibt an, in wie viele Teilsequenzen die Eingabedaten aufgeteilt werden (für entspricht der Algorithmus Quicksort), während sich durch einen großen Oversamplingfaktor die Größen der Buckets statistisch gesehen weniger unterscheiden.




// if average bucket size is below a threshold switch to e.g. quicksort // select samples // sort sample // select splitters // classify elements









Die Wahl des richtigen Buckets in der Schleife kann für jedes Element mit binärer Suche in Zeit ausgeführt werden.

Der angegebene Pseudocode unterscheidet sich von der von Frazer und McKellar beschriebenen Ursprungsform.[2] Im Pseudocode wird Samplesort rekursiv aufgerufen, um die erzeugten kleineren Teilmengen zu sortieren. Frazer und McKellar verwendeten dafür Quicksort, d. h. die Funktion Samplesort wird nur einmal aufgerufen.
Die Anzahl Vergleiche, die dieser Algorithmus durchführt, nähert sich für große Eingabesequenzen asymptotisch dem informationstheoretischen Optimum an und brauchte in den von Frazer und McKellar durchgeführten Experimenten mehr als 15 % weniger Vergleiche als Quicksort.

Oversampling
Der Oversamplingfaktor gibt an, wie groß die Stichprobe zur Auswahl der Splitter größer ist, als die Anzahl der Splitter. Ziel ist es, die Verteilung der Eingabedaten möglichst gut anzunähern. Nach der Klassifikation enthält im Idealfall jeder Bucket genau Elemente, um die folgende Arbeit des Algorithmus gleichmäßig auf die Buckets aufzuteilen.

Nach der Wahl des Samples der Größe wird das Sample sortiert. Als Splitter, die als Bucketgrenzen verwendet werden, werden die Elemente in an den Stellen sowie und als linke und rechte Grenzen des linkesten und rechtesten Buckets verwendet.





Größe der Buckets
Mit der Größe des Samples bzw. dem Oversamplingfaktor kann die erwartete Bucketgröße und insbesondere die Wahrscheinlichkeit dafür, dass ein Bucket eine gewisse Größe überschreitet, abgeschätzt werden. Für einen Oversamplingfaktor werden wir zeigen, dass mit einer Wahrscheinlichkeit von weniger als ein Bucket mehr als Elemente enthält.



Sei dafür die Eingabe bereits in sortierter Form. Damit ein Prozessor mehr als Elemente erhält, muss es eine Sequenz der Eingabe der Länge geben, aus der maximal Elemente für das Sample gewählt werden. Das wird wie folgt als Zufallsvariable dargestellt:



Daraus folgt:


Dabei bezeichnet die Wahrscheinlichkeit, dass weniger als Samples im Bucket liegen. Mithilfe der Chernoff-Ungleichung sieht man, dass


- für


Samplesort auf Systemen mit verteiltem Speicher
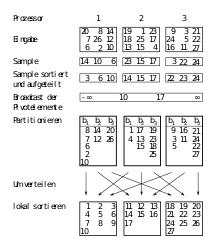


Samplesort wird oft in parallelen Systemen mit verteiltem Speicher verwendet[3][4][5][6], da es durch die variable Anzahl von Buckets im Gegensatz zum Beispiel zu Quicksort einfach an eine beliebige Anzahl Prozessoren angepasst werden kann. Die Eingabedaten liegen dabei verteilt auf Prozessoren vor, das heißt, jeder Prozessor hat Elemente gespeichert. Entsprechend werden ebenso viele Splitter ausgewählt, um für jeden Prozessor einen Bucket zu erzeugen.
Um die Splitter auszuwählen, ist es ausreichend, wenn jeder Prozessor aus seinen Eingabeelementen Elemente auswählt. Diese werden mit einem verteilten Sortieralgorithmus sortiert und an alle Prozessoren verteilt. Es entstehen Kosten von für das Sortieren der Elemente auf Prozessoren, sowie für das Verteilen der gewählten Splitter auf Prozessoren.



Mit den erhaltenen Splittern partitioniert jeder Prozessor die eigenen Eingabedaten in lokale Buckets. Die Zeit dafür beträgt mit binärer Suche . Anschließend verteilen die Prozessoren die Buckets an die jeweiligen Prozessoren mit Zeit , wobei der Größe des größten Buckets entspricht. Prozessor enthält entsprechend von allen Prozessoren die lokalen Buckets und sortiert diese lokal. Der Zeitbedarf für die lokale Sortierung von allen Prozessoren beträgt .






Wählt man wie im vorherigen Abschnitt beschrieben , so erhält man eine Gesamtlaufzeit von

Effiziente Implementierung von sequentiellem Samplesort
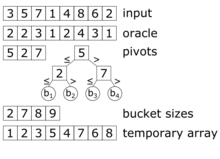
Wie oben beschrieben klassifiziert der Algorithmus die Elemente anhand der gewählten Splitter und partitioniert diese entsprechend. Eine effiziente Implementierung wird im Paper Super Scalar Sample Sort[1] beschrieben. Dort werden zwei Arrays der Größe genutzt: ein Array für die Eingabedaten, sowie ein temporäres Array. Entsprechend arbeitet Samplesort in diesem Fall nicht in-place. In jedem Rekurssionsschritt werden die Daten von einem zum anderen Array kopiert und währenddessen partitioniert. Falls die Daten nach dem letzten Rekursionsschritt im temporären Array vorliegen, so werden diese in das originale Array zurückkopiert. Die wesentlichen Schritte sind die Klassifikation der Elemente anhand der Splitter und die anschließende Partitionierung. Beides wird im Folgenden genauer erklärt.

Klassifikation der Elemente
In einem vergleichsbasierten Sortieralgorithmus ist der performancekritische Teil die Klassifikation der Elemente, d. h. die Zuordnung von Elementen zu Buckets. Diese Zuordnung benötigt Schritte pro Element. Super Scalar Sample Sort nutzt einen balancierten Suchbaum, der implizit in einem Array gespeichert ist. Das heißt, die Wurzel befindet sich an Stelle 0, und der linke Nachfolger eines Elementes befindet sich in , der rechte Nachfolger in . Bei einem gegebenen Suchbaum und einem Element berechnet der Algorithmus den Index des entsprechenden Buckets wie folgt (der Ausdruck sei 1 falls und 0 andernfalls, sei eine Zweierpotenz):










Da die Anzahl der Buckets bei der Übersetzungszeit bekannt ist, kann die Schleife vom Compiler ausgerollt werden. Falls die Prozessorarchitektur es unterstützt, kann in der Schleife ganz auf bedingte Sprünge verzichtet werden und es treten keine fehlerhaften Sprungvorhersagen auf.
Partitionierung
Zum effizienten Partitionieren muss der Algorithmus die Größen der Buckets vor dem Kopieren der Elemente kennen. In einer naiven Implementierung könnten alle Elemente klassifiziert werden, um die Bucketgrößen zu bestimmen. Anschließend könnten die Elemente an die richtige Stelle kopiert werden. So müsste der Bucket für jedes Element zweimal bestimmt werden (einmal für das Zählen der Elemente der Buckets und einmal zum Kopieren). Super Scalar Sample Sort vermeidet diese doppelte Klassifikation, indem das Ergebnis der Klassifikation in einem zusätzlichen Array (dem „Orakel“) zwischengespeichert werden. Dieses ordnet jedem Element den Bucketindex zu. Zuerst bestimmt Super Scalar Sample Sort die richtigen Werte von , indem jedes Element klassifiziert wird. Danach werden die Größen der Buckets bestimmt und jedes Element anhand von an die richtige Stelle kopiert. Der Speicherbedarf von Array beträgt bits, was im Vergleich zu den Eingabedaten nur wenig Speicher bedeutet.




Paralleler in-place-Samplesort für Systeme mit gemeinsamem Speicher
Die oben gezeigte Samplesort-Implementierung arbeitet nicht in-place, da ein zweites Array der Größe benötigt wird. Effiziente Implementierungen von z. B. Quicksort arbeiten in-place und benötigen daher weniger Speicher. Samplesort kann allerdings auch in-place für parallele Systeme mit gemeinsamem Speicher implementiert werden.[7] Im Folgenden wird eine solche Implementierung beschrieben. Zu beachten ist, dass der zusätzliche Speicherplatz des Algorithmus immer noch von abhängt, im Gegensatz zum oben erklärten Super Scalar Sample Sort aber nur zusätzlichen Speicherplatz benötigt. Eine modifizierte Variante des Algorithmus, der nur noch Speicherplatz unabhängig von benötigt, ist ebenfalls in[7] beschrieben.

Der in-place Algorithmus kann in vier Phasen aufgeteilt werden:
- Sampling: Auswahl der Splitter.
- Lokale Klassifikation: Gruppieren der Eingabe in Blöcke, so dass alle Elemente eines Blockes zu einem Bucket gehören (allerdings muss nicht jeder Bucket zusammenhängend im Speicher liegen).
- Blockpermutation: Vertauschen der Blöcke, so dass diese global in der richtigen Reihenfolge liegen.
- Aufräumen: Kopieren der übrigen Elemente an die Kanten der Buckets.
Da durch diesen Algorithmus jedes Element zweimal gelesen und geschrieben werden muss (einmal bei der Klassifikation und einmal während der Blockpermutation) ergibt sich ein höherer Schreib- und Leseaufwand. Trotzdem ist der Algorithmus bis zu dreimal schneller als aktuelle in-place Wettbewerber und bis zu 1,5 mal schneller als andere aktuelle sequentielle Wettbewerber, einschließlich des oben beschrieben Super Scalar Sample Sort. Da das Sampling und die Auswahl der Splitter bereits oben (Pseudocode) beschrieben ist, folgen an dieser Stelle nur noch die detaillierten Erklärungen der drei anderen Phasen.
Lokale Klassifikation
Das Eingabearray wird zuerst in (Anzahl der Prozessoren/Threads) Bereiche gleicher Größe aufgeteilt. Jeder Prozessor enthält einen solchen Bereich und teilt diesen weiter auf in Blöcke, die jeweils Elemente enthalten. Zusätzlich allokiert jeder Prozessor (Anzahl Buckets) Puffer, die ebenfalls Elemente speichern können. Jeder Prozessor verarbeitet anschließend seinen zugewiesenen Bereich und kopiert die Elemente in die entsprechenden allokierten Puffer. Falls ein Puffer voll ist, wird dessen Inhalt in den vom Prozessor verarbeiteten Bereich kopiert. Die dortigen Elemente, die dadurch überschrieben werden, sind bereits verarbeitet, da ansonsten kein Puffer voll sein könnte. Zur Auswahl der richtigen Buckets/Puffer siehe Klassifikation der Elemente. Nach dieser Phase enthält jeder Bereich mehrere Blöcke mit Elementen jeweils eines Buckets und darauffolgend leere Blöcke. Die übrigen Elemente sind noch in den Pufferblöcken. Zusätzlich speichert jeder Prozessor die Größe jedes Buckets.

Blockpermutation
In dieser Phase werden die Blöcke im Eingabearray in die richtige Reihenfolge gebracht. Mithilfe einer Präfixsumme über die Größe der Buckets werden deren Grenzen bestimmt. Da in dieser Phase nur ganze Blöcke verschoben werden, werden die Grenzen auf ganze Blöcke aufgerundet. Die fehlenden Elemente befinden sich noch in den Pufferblöcken. Da die Größe des Eingabearrays nicht zwangsläufig durch die Blockgröße teilbar ist, müssen einige Elemente des letzten (nicht vollständigen) Blockes in einen Überlaufpuffer verschoben werden.
Bevor mit der Blockpermutation begonnen wird, müssen eventuell einige leere Blöcke an das Ende ihres Buckets verschoben werden. Anschließend wird für jeden Bucket ein Schreibpointer angelegt, der auf den Beginn der Buckets zeigt und ein Lesepointer , der auf den letzten nichtleeren Block im Bucket zeigt.


Um gegenseitige Blockierungen der Prozessoren zu vermeiden, verarbeitet jeder Prozessor anfangs einen eigenen (primären) Bucket . Außerdem erhält jeder Prozessor zwei Tauschpuffer, die jeweils genau einen Block speichern können. Falls beide Tauschpuffer leer sind, wird der Block an Stelle von in einen der Tauschpuffer platziert. Durch Klassifikation des ersten Elements im Puffer wird der Zielbucket dieses Blocks bestimmt und an Stelle kopiert. Um zu verhindern, dass ein dortiger Block überschrieben wird, muss dieser vorher in einen freien Tauschpuffer kopiert werden. Mit diesem Block im Tauschpuffer wird dann analog verfahren. Die Pointer und werden entsprechend angepasst.




Sind alle Blöcke des primären Buckets an der richtigen Stelle, werden die Blöcke des nächsten Buckets weiterverarbeitet, bis alle Blöcke ihren Zielbucket erreicht haben. Danach endet diese Phase.
Aufräumen
Da nur ganze Blöcke in der Blockpermutationsphase verschoben wurden, können einige Elemente noch an Stelle außerhalb ihres Buckets liegen. Da es für alle Elemente noch genug Platz im ursprünglichen Array gibt, können die verbleibenden Elemente aus den Puffern an die freien Plätze kopiert werden. Zuletzt wird der Inhalt des Überlaufpuffers kopiert.
Literatur
- W. D. Frazer, A. C. McKellar: Samplesort: A Sampling Approach to Minimal Storage Tree Sorting. In: Journal of the ACM. Band 17, Nr. 3, Juli 1970, ISSN 0004-5411, S. 496–507.
- Peter Sanders et al.: Vorlesung Parallele Algorithmen, Karlsruhe 2009, S. 75–80.
Erweiterungen für parallele Berechnungen:
- ohio-state.edu (Memento vom 8. Juni 2011 im Internet Archive) (PDF)
- citeseer.ist.psu.edu
- citeseerx.ist.psu.edu
- Verwendung auf der GPU (PDF; 869 kB)
Einzelnachweise
- Peter Sanders, Sebastian Winkel: Super Scalar Sample Sort. In: Algorithms – ESA 2004 (= Lecture Notes in Computer Science). Springer, Berlin, Heidelberg, 2004, ISBN 978-3-540-23025-0, S. 784–796, doi:10.1007/978-3-540-30140-0_69.
- W. D. Frazer, A. C. McKellar: Samplesort: A Sampling Approach to Minimal Storage Tree Sorting. In: Journal of the ACM (JACM). Band 17, Nr. 3, 1. Juli 1970, ISSN 0004-5411, S. 496–507, doi:10.1145/321592.321600 (acm.org [abgerufen am 22. März 2018]).
- Guy E. Blelloch, Charles E. Leiserson, Bruce M. Maggs, C. Greg Plaxton, Stephen J. Smith: A comparison of sorting algorithms for the connection machine CM-2. ACM, 1991, ISBN 0-89791-438-4, S. 3–16, doi:10.1145/113379.113380 (acm.org [abgerufen am 23. März 2018]).
- Alexandros V. Gerbessiotis, Leslie G. Valiant: Direct Bulk-Synchronous Parallel Algorithms. In: JOURNAL OF PARALLEL AND DISTRIBUTED COMPUTING. Band 22, 1992, S. 22––251 (psu.edu [abgerufen am 1. April 2018]).
- Jonathan M. D. Hill, Bill McColl, Dan C. Stefanescu, Mark W. Goudreau, Kevin Lang: BSPlib: The BSP Programming Library. 1998 (psu.edu [abgerufen am 1. April 2018]).
- William L. Hightower, Jan F. Prins, John H. Reif: Implementations of randomized sorting on large parallel machines. ACM, 1992, ISBN 0-89791-483-X, S. 158–167, doi:10.1145/140901.140918 (acm.org [abgerufen am 1. April 2018]).
- Michael Axtmann, Sascha Witt, Daniel Ferizovic, Peter Sanders: In-Place Parallel Super Scalar Samplesort (IPSSSSo). In: 25th Annual European Symposium on Algorithms (ESA 2017) (= Leibniz International Proceedings in Informatics (LIPIcs)). Band 87. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, Germany 2017, ISBN 978-3-95977-049-1, S. 9:1–9:14, doi:10.4230/LIPIcs.ESA.2017.9 (dagstuhl.de [abgerufen am 30. März 2018]).