Nebenläufige Hashtabelle
Eine nebenläufige Hashtabelle (englisch concurrent hash table oder concurrent hash map) ist eine Implementierung von Hashtabellen, die den gleichzeitigen Zugriff (concurrent access) durch mehrere threads ermöglicht.[1][2]
Nebenläufige Hashtabellen sind somit eine zentrale nebenläufige Datenstruktur in der parallelen Berechnung, da sie effizientere, parallelisierte Berechnungen auf gemeinsamen Daten ermöglichen.[1]
Aufgrund von Ressourcenkonflikten, die aus dem gleichzeitigen Datenzugriff resultieren, unterscheiden sich Implementierungen von nebenläufigen Hashtabellen oft in der Art und Weise in denen auf die Tabelle gleichzeitig zugegriffen werden kann. Darüber hinaus ist nicht garantiert, dass die Beschleunigung durch eine nebenläufige Hashtabelle linear mit der Anzahl der Threads steigt, da zusätzlicher Overhead für die Auflösung von Ressourcenkonflikten benötigt wird.[1] Es gibt mehrere Ansätze um diesen Overhead zu minimieren, die jeweils zudem noch sicherstellen, dass die Korrektheit der Operationen auf der Tabelle erhalten bleibt.[1][2][3][4]
Wie bei ihrem sequentiellen Gegenstück können nebenläufige Hashtabelle erweitert werden, um in verschiedenen Anwendungsgebieten verwendet werden zu können (z. B. komplexe Datentypen für Schlüssel und Werte). Solche Erweiterungen können sich jedoch negativ auf die Performanz auswirken und sollten daher entsprechend den Anforderungen der Anwendung gewählt werden.[1]
Gleichzeitiger Zugriff
Bei der Erstellung von nebenläufigen Hashtabellen müssen die Zugriffsalgorithmen der Hashtabelle angepasst werden, um gleichzeitigen Zugriff von mehreren threads zu erlauben. Hierfür müssen vor allem Ressourcenkonflikte aufgelöst werden um die Integrität und Korrektheit der Tabelle zu gewährleisten. Im Idealfall sollten diese Änderungen auch eine effizientere parallele Nutzung ermöglichen.
Herlihy und Shavit[5] beschreiben, wie ein sequentieller Zugriffsalgorithmus ohne Strategien zur Auflösung von Ressourcenkonflikten – in ihrem Beispiel eine simple Version auf Basis des Kuckucks-Hashing-Algorithmus – für den nebenläufigen Gebrauch angepasst werden kann. Weiter beschreiben Fan et al.[6] einen weiteren auf Kuckucks-Hashing basierenden Algorithmus, der sowohl gleichzeitigen Zugriff erlaubt, als auch die Platzeffizienz des Kuckucks-Hashings erhält und darüber hinaus zudem noch die Cache-Lokalität sowie den Durchsatz von Inserts verbessert.
Wenn Hashtabellen keine feste Größe haben und somit bei Bedarf wachsen sowie schrumpfen, so muss die Hashfunktion angepasst werden um alle möglichen Schlüssel der neuen Tabelle abzudecken. Eine Möglichkeit eine wachsende Tabelle nebenläufig zu gestalten wird von Maier et al.[1] beschrieben.
Auflösen von Ressourcenkonflikten
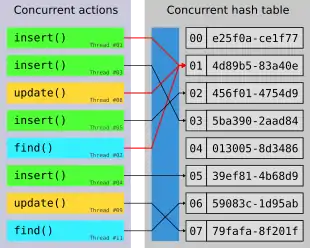
Wie andere nebenläufige Datenstrukturen leiden auch nebenläufige Hashtabellen unter einer Vielzahl von Problemen, die durch Ressourcenkonflikte entstehen.[3] Beispiele hierfür sind das ABA-Problem, Race Conditions und Deadlocks. Wie stark, oder gar ob, diese Probleme auftreten, hängt immer von der jeweiligen Implementierung ab; insbesondere davon, welche Operationen auf der Tabelle gleichzeitig ausgeführt werden können, sowie von den Strategien zur Behandlung von Problemen rund um Ressourcenkonflikte.
Bei der Behandlung von Ressourcenkonflikten liegt das Hauptziel wie bei jeder anderen nebenläufigen Datenstruktur darin, die Korrektheit jeder Operation auf der Tabelle zu gewährleisten. Weiterhin sollte dies idealerweise so gestaltet werden, dass die nebenläufige Implementierung selbst dann noch immer schneller als die sequentielle Version arbeitet.
Atomare Anweisungen
Mit atomaren Operationen wie Compare-and-swap oder Fetch-and-add können Probleme die durch Ressourcenkonflikte entstehen reduziert werden, indem sichergestellt wird, dass ein Zugriff abgeschlossen wird bevor ein anderer Zugriff die Möglichkeit hat sich einzumischen. Operationen wie compare-and-swap schränken dabei allerdings oft die Datengröße der unterstützten Variablen oft stark ein, woraus folgt, dass die Schlüssel- und Werttypen einer Tabelle entsprechend ausgewählt oder konvertiert werden müssen.[1]
Unter Verwendung von so genanntem Hardware Transaktionalem Speicher (HTM), kann man Tabellenoperationen ähnlich wie Datenbanktransaktionen[3] betrachten, wodurch die Atomizität gewahrt wird. Ein Beispiel für HTM in der Praxis sind die Transactional Synchronization Extensions.
Locking
Mit Hilfe von locks können Operationen, die versuchen gleichzeitig auf die Tabelle oder deren Werte zuzugreifen, geregelt ausgeführt werden, sodass ein korrektes Verhalten gewährleistet ist. Dies kann sich jedoch negativ auf die Performanz auswirken[1], insbesondere wenn die locks zu restriktiv gesetzt sind. Dadurch werden Tabellen-Zugriffe blockiert, die sonst ohne Probleme ausführbar wären. Weitere Überlegungen müssen angestellt werden um Probleme zu vermeiden, die zudem die Korrektheit der gesamten Tabelle gefährden. Beispiele für solche Probleme wären z. B. Livelocks, Deadlocks oder Starvation.[3]
Phasennebenläufigkeit
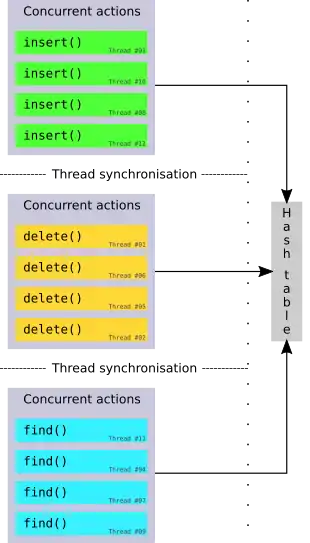
Eine Phasennebenläufige Hashtabelle gruppiert Zugriffe in Phasen, in denen nur eine Art von Operation erlaubt ist (d. h. eine reine Schreibphase, reine Lesephase etc.). Nach jeder Phase folgt eine Prozesssynchronisation des Tabellenzustands über alle Threads hinweg. Ein formal bewiesener Algorithmus wurde von Shun und Blelloch präsentiert.[2]
Read-copy-update
Read-copy-update (RCU) mechanismen sind weit verbreitet im Linux-Kernel.[3] Diese sind besonders nützlich wenn die Anzahl der Lesezugriffe bei weitem die Anzahl der Schreibzugriffe übersteigt.[4]
Anwendungen
Nebenläufige Hashtabellen finden überall dort Anwendung, wo sequentielle Hashtabellen auch sinnvoll sind. Der Vorteil, den die Parallelität hierin bietet, liegt in der möglichen Beschleunigung dieser Anwendungsfälle sowie in deren erhöhter Skalierbarkeit[1]. In Anbetracht von Hardware wie Mehrkernprozessoren, die für parallele Berechnungen immer leistungsfähiger werden, wächst die Bedeutung nebenläufiger Datenstrukturen somit stetig.[3]
Leistungsanalyse
Maier et al.[1] führen eine gründliche Analyse einer Vielzahl von nebenläufigen Hashtabellen-Implementierungen durch, worin ein Einblick dafür gegeben wird, wie effektiv diese jeweils innerhalb verschiedener Situationen sowie in häufig auftretenden, realen Anwendungsfällen sind.
| Operation | Konfliktanzahl | Notizen | |
|---|---|---|---|
| Niedrig | Hoch | ||
find | Sehr große Speedups sowie mit erfolgreichen als auch nicht erfolgreichen unique finds, selbst mit vielen Ressourcenkonflikten | ||
insert | Große Speedups sind möglich, viele Ressourcenkonflikte wirken sich negativ auf die Performanz aus, wenn ein Key mehr als einen Wert halten kann (wenn nicht, werden inserts einfach verworfen) | ||
update | Sowohl bei dem Überschreiben, als auch bei dem Abändern von Werten können große Speedups erreicht werden, wenn die Konfliktanzahl gering ist. Ansonsten kann die Performanz schlechter seien als im sequentiellen Fall. | ||
delete | Mit Phasennebenläufigkeit konnte die höchste Skalierbarkeit erreicht werden. In Implementationen, bei denen delete durch update realisiert wurde, war die Performanz leicht geringer. | ||
Wie erwartet zeigt jede Operation der Hashtabelle positives Verhalten wenn nur wenige Ressourcenkonflikte auftreten. Eine hohe Anzahl an Konflikten führt hierbei jedoch zu Problemen für das Schreiben. Das Letztere ist dabei allerdings eher ein generelles Problem in der Parallelverarbeitung, da eine hohe Anzahl an Konflikten zu hohen Kosten für deren Behandlung führt. Da die sequentielle Version kein solches Konflikt-Management benötigt, ist diese dabei natürlicherweise performanter. Trotz allem ist hier jedoch zu vermerken, dass bestimmte Implementierungen gleichzeitige Schreibzugriffe in einer Art und Weise ausführen, mit der selbst bei einer hohen Anzahl an Konflikten noch immer hohe Speedups erreicht werden.
Weiterhin ist es wichtig darauf zu achten, dass in der realen Welt nur selten Sequenzen bestehend aus einem alleinigem Operationstyp vorkommen, da es z. B. eher selten ist in eine Tabelle nur zu schreiben, diese aber nie zu lesen. Betrachtet man somit die Performanz einer Mischung verschiedener Operationen, wie das sehr häufig auftretende Paar insert und find, so zeigt sich der Nutzen einer nebenläufigen Hashtabelle sehr eindeutig in der hohen Skalierbarkeit. Diese ist vor allem genau dann sehr hoch, wenn eine prozentual hohe Anzahl an find Operationen durchgeführt wird.
Letztendlich ist die endgültige Performanz einer nebenläufigen Hashtabelle von einer Vielzahl an Faktoren abhängig, die je nach gewünschtem Verwendungszweck variieren. Bei der Wahl einer entsprechenden Implementation muss dabei auf Aspekte wie Generalität, Konfliktbehandlung sowie Größe der Tabelle geachtet werden. Für den letzten Punkt ist beispielsweise die Überlegung notwendig, ob die Größe der gewünschten Tabelle im Vorfeld ermittelt werden kann, oder ob ein Ansatz mittels dynamischer Größe verwendet werden muss.
Implementierungen
- Seit Java 1.5, werden nebenläufige Hashtabellen basierend auf dem concurrent map interface bereitgestellt.[7]
- libcuckoo stellt nebenläufige Hashtabellen für C/C++ zur Verfügung, die paralleles Lesen und Schreiben ermöglichen. Die Bibliothek ist verfügbar auf GitHub.[8]
- Threading Building Blocks bieten nebenläufige ungeordnete Hashtabellen für C++, welche gleichzeitiges Einfügen sowie Durchlaufen ermöglichen und in einem ähnlichen Stil gehalten sind wie der C++11
std::unordered_mapContainer. Enthalten sind zudem die nebenläufigen ungeordneten Multimaps, die es ermöglichen mehrere Werte für den gleichen Schlüssel in einer solchen Map zu speichern.[9] Zusätzlich werden nebenläufige Hash Maps bereitgestellt, die auf der nebenläufigen ungeordneten Map aufbauen und weiterhin das gleichzeitige Löschen ermöglichen sowie integrierte Locks enthalten.[10]
- growt stellt nebenläufige wachsende Hash-Tabellen für C++ auf der Grundlage der sogenannten Folklore-Implementierung zur Verfügung. Basierend auf dieser nicht wachsenden Implementierung wird eine Vielzahl von verschiedenen wachsenden Hashtabellen bereitgestellt. Diese Implementierungen ermöglichen gleichzeitiges Lesen, Einfügen, Aktualisieren (insbesondere Aktualisieren von Werten basierend auf dem aktuellen Wert am Schlüssel) und Entfernen (basierend auf Aktualisieren mit Hilfe von Tombstones). Darüber hinaus werden Varianten auf Basis von Intel TSX angeboten. Die Bibliothek ist verfügbar auf GitHub.[11][1]
- folly bietet nebenläufige Hashtabellen[12] für C++14 und später, die wait-free Reader und lockbasierte, fragmentierte Writer. Wie auf der GitHub-Seite angegeben, bietet diese Bibliothek nützliche Funktionen für Facebook.[13]
- Junction stellt mehrere Implementierungen von nebenläufigen Hashtabellen für C++ auf der Grundlage von atomaren Operationen zur Verfügung, um die Thread-Sicherheit für jede beliebige Funktion der Tabelle zu gewährleisten. Die Bibliothek ist verfügbar auf GitHub.[14]
Siehe auch
Literatur
- Maurice Herlihy, Nir Shavit: Chapter 13: Concurrent Hashing and Natural Parallelism. In: The Art of Multiprocessor Programming. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA 2008, ISBN 978-0-12-370591-4, S. 299–328.
Einzelnachweise
- Tobias Maier, Peter Sanders, Roman Dementiev: Concurrent Hash Tables: Fast and General(?)!. In: ACM (Hrsg.): ACM Trans. Parallel Comput.. 5, Nr. 4, März 2019, ISSN 2329-4949, S. 1–32, Artikel 16. doi:10.1145/3309206.
- Julian Shun, Guy E. Blelloch: Phase-concurrent Hash Tables for Determinism. In: SPAA '14. ACM, 2014, S. 96–107. ISBN 978-1-4503-2821-0 doi:10.1145/2612669.2612687
- Xiaozhou Li, David G. Andersen, Michael Kaminsky, Michael J. Freedman: Algorithmic Improvements for Fast Concurrent Cuckoo Hashing. In: EuroSys '14. ACM, 2014, S. 1–14, Artikel 27. ISBN 978-1-4503-2704-6 doi:10.1145/2592798.2592820
- Josh Triplett, Paul E. McKenney, Jonathan Walpole: Resizable, Scalable, Concurrent Hash Tables via Relativistic Programming. In: USENIXATC'11. USENIX Association, 2011. doi:10.1145/2592798.2592820
- Maurice Herlihy, Nir Shavit: Chapter 13: Concurrent Hashing and Natural Parallelism. In: The Art of Multiprocessor Programming. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA 2008, ISBN 978-0-12-370591-4, S. 316–325.
- Bin Fan, David G. Andersen, Michael Kaminsky: MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing. In: nsdi'13. USENIX Association, 2013, S. 371–384.
- Java ConcurrentHashMap Dokumentation
- GitHub repository für libcuckoo
- Threading Building Blocks concurrent_unordered_map und concurrent_unordered_multimap Dokumentation
- Threading Building Blocks concurrent_hash_map Dokumentation
- GitHub repository für growt
- GitHub-Seite für die Implementierung von nebenläufigen Hash-Maps in folly
- GitHub repository für folly
- GitHub repository für Junction