Hierarchischer Temporalspeicher
Ein hierarchischer Temporalspeicher (englisch hierarchical temporal memory, HTM) ist ein Modell des maschinellen Lernens, welches von Jeff Hawkins und Dileep George (Numenta, Inc.) entwickelt wurde. Dieses Modell bildet einige Eigenschaften des Neocortex ab.
Aufbau und Funktion
HTMs sind als hierarchisch aufgebautes Netz von Knoten organisiert. Jeder Knoten implementiert, wie in einem Bayes’schem Netz, eine Lern- und Speicherfunktion. Die Struktur ist dahingehend aufgebaut, um anhand von zeitveränderlichen Daten eine hierarchische Präsentation dieser Daten zu erstellen. Dies ist jedoch nur möglich, wenn die Daten sowohl im (Problem-)Raum, als auch in der Zeit hierarchisch repräsentierbar sind.
Ein HTM führt die folgenden Funktionen aus, wobei die letzten zwei – je nach Implementierung – optional sind:
- Erkennung und Repräsentation von Elementen und Zusammenhängen.
- Inferenz von neuen Elementen und Zusammenhängen anhand der bekannten Elemente und Zusammenhängen.
- Erstellung von Voraussagen. Treffen diese Voraussagen nicht zu, wird das interne Modell entsprechend angepasst.
- Verwenden von Voraussagen um Aktionen auszuführen, sowie Beobachtung der Auswirkung. (Steuerung und Regelung)
Sparse Distributed Representation
Daten, welche von einem HTM verarbeitet werden, werden als Sparse Distributed Representation (SDR)[1] kodiert. Dabei handelt es sich um dünnbesetzte Bitvektoren, bei dem jedem Bit eine semantische Bedeutung zukommt. Für jede mögliche Eingabe sind also nur eine geringe Anzahl von Bits aktiv.
Gemeinsame aktive Bits bei unterschiedlichen Eingaben weisen auf eine gemeinsame Bedeutung hin. Kommt es etwa im Zuge vom Subsampling bei dem Vergleich von zwei SDRs zu einem False-Positive, so sind diese zwar nicht gleich, teilen aber eine ähnliche Bedeutung.
Je nach Datentyp kommen unterschiedliche Kodierer zum Einsatz. Beispielsweise gibt es Kodierer für diverse Zahlenformate, Zeitangaben, geographische Angaben sowie für die semantische Bedeutung von Wörtern in natürlicher Sprache.
Auf die durch eine SDR dargestellte semantische Bedeutung können, ähnlich dem Vektorraum-Retrieval, Mengenoperationen angewendet werden.
- Beispiel

Dendriten- und Synapsenmodell
Die Verbindungen zwischen den Neuronen (Dendriten) werden über eine Matrix dargestellt. Übersteigt die Verbindungsstärke („Permanenz“) einen bestimmten Schwellwert, so wird logisch eine Synapse gebildet. Synapsen werden hierbei als Identische Abbildung modelliert, leiten also den (binären) Eingabewert unverändert weiter. (siehe auch: Schwellenwertverfahren)
Es wird zudem zwischen basalen und apikalen Dendriten unterschieden.
- Basale Dendriten
- Basale Dendriten stellen etwa 10 % der Dendriten. Sie sind lokal innerhalb einer Neuronenschicht mit anderen (räumlich nahen) Neuronen verknüpft und repräsentieren die Vorhersage für die zukünftige Aktivierung von Neuronen in einem bestimmten Kontext. Jeder basale Dendrit steht hierfür für einen anderen Kontext.
- Wird die Aktivierung eines Neurons durch einen basalen Dentriten vorhergesagt, so wird die Aktivierung des entsprechenden Neurons unterdrückt. Umgekehrt wird die unerwartete Aktivierung eines Neurons nicht unterbunden und führt zu einem Lernvorgang.
- Apikale Dendriten
- Apikale Dendriten stellen die restlichen 90 % der Dendriten. Sie stellen die Verbindung zwischen den Neuronenschichten her. Je nach Schicht sind sie innerhalb einer Kortikalen Spalte, etwa als Feedforward-Netz oder Feedback-Netz, verknüpft.
Spacial Pooling und Temporal Pooling
Das Spacial Pooling ist ein Algorithmus, welches das Lernverhalten zwischen räumlich nahen Neuronen steuert. Wird ein Neuron aktiviert, so wird die Aktivierung räumlich benachbarter Neuronen mittels der basalen Dentriten unterdrückt. Dadurch wird ein dünnbesetztes Aktivierungsmuster gewährleistet. Das übrigbleibende aktivierte Neuron stellt hierbei die beste semantische Repräsentation zu der gegebenen Eingabe dar.
Findet eine, durch die Aktivierung eines Neurons vorhergesagte, Aktivierung benachbarter Neuronen statt, so wird die Permanenz der basalen Verbindung zur Unterdrückung der entsprechenden Neuronen verstärkt. Findet eine vorhergesagte Aktivierung nicht statt, so wird die Permanenz der basalen Verbindung geschwächt.
Das Temporal Pooling entspricht funktional dem Spacial Pooling, wirkt allerdings zeitlich verzögert. Je nach Implementierung ist des Temporal Pooling wahlweise als eigenständige Funktion implementiert oder mit dem Spacial Pooling zusammengefasst. Auch gibt es unterschiedliche Ausführungen wie viele Zeiteinheiten in die Vergangenheit berücksichtigt werden. Durch das zeitlich verzögerte Vorhersagen einer Neuronenaktivierung ist ein HTM in der Lage zeitlich abhängige Muster zu erlernen und vorherzusagen.
Klassifizierer
Am Ende einer Pipeline aus einer oder mehreren HTM-Schichten wird ein Klassifizierer eingesetzt, um eine als SDR kodierte Ausgabe des HTMs einem Wert zuzuordnen.
Schichtenmodell
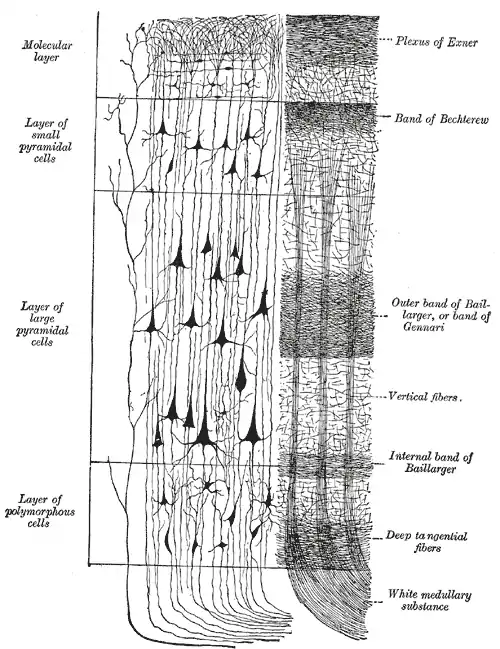
Analog zum Neocortex wird eine kortikale Spalte in mehreren Schichten aufgebaut, wobei jede Schicht ein HTM darstellt. Prinzipiell leitet eine untenliegende Schichte ihre Daten an eine höherliegende Schicht weiter.
Kortikale Spalten sind wiederum in Serie geschaltet. Niedere Spalten geben hierbei ihre Daten an organisatorisch höhere Spalten weiter, während höhere Spalten Vorhersagen zur Neuronenaktivierung an niedere Spalten zurückgeben.
| Schicht | Funktion | Aufbau |
|---|---|---|
| 2/3 | Inferenz (Sensorik) | Feedforward |
| 4 | Inferenz (Sensorik-Motorik) | |
| 5 | Motorik | Feedback |
| 6 | Aufmerksamkeit | |
Schicht 6 nimmt Sensordaten, welche mit einer Kopie der zugehörigen Motorikdaten kombiniert sind, entgegen. Die Daten kommen hierbei entweder direkt aus der Sensorik oder von organisatorisch niederen Spalten. Vorhersagen der Schicht 6 werden an untenliegende Spalten weitergeleitet.
Schicht 5 ist für die Steuerung der Motorik zuständig. Zudem werden Motorik-Steuerbefehle über den Thalamus auch an organisatorisch höhere Spalten weitergereicht.[2]
Schicht 2/3 ist die höchste logische Schicht. Sie leitet ihr Ergebnis an organisatorisch höhere Spalten weiter.
Die genauen Ein- und Ausgaben der einzelnen Schichten, sowie deren genaue Bedeutung, sind hierbei nur teilweise erforscht. Praktische Implementierungen eines HTMs beschränken sich daher meist auf die Schicht 2/3, deren Funktion am besten verstanden ist.[3]
Vergleich zu Deep Learning
| Eigenschaft | HTM | Deep Learning |
|---|---|---|
| Datenrepräsentation | Binär; dünnbesetzte Datendarstellung | Gleitkomma; dichtbesetzte Datendarstellung |
| Neuronenmodell | Vereinfachtes Modell. | Stark vereinfachtes Modell. |
| Komplexität und Berechnungsaufwand | Hoch. Bislang keine Umsetzung für spezialisierte Hardware. | Mittel bis Hoch. Diverse Optionen für Hardwarebeschleunigung verfügbar. |
| Umsetzung | Bislang nur als Prototypen umgesetzt. | Vielzahl an inzwischen relativ ausgereiften Frameworks verfügbar. |
| Verbreitung | Wird bislang kaum eingesetzt. | Wird von großen Unternehmen und Forschungseinrichtungen weitläufig eingesetzt. |
| Lernen | Online-Learning. Kann aus einem Datenstrom kontinuierlich hinzulernen. | Batch-Learning. Anfällig für Katastrophale Interferenz. |
| Konversionsrate | Langsam. Benötigt viele Iterationen um einen Zusammenhang zu erlernen. | Sehr langsam. |
| Robustheit | Durch die SDR sehr robust gegen Adversarial-Machine-Learning-Methoden. | Anfällig gegen Adversarial Machine Learning-Methoden. Muss gezielt auf die Abwehr bestimmter Angriffsszenarien trainiert werden. |
Kritik
HTMs stellen für KI-Forscher nichts grundlegend Neues dar, sondern sind eine Kombination bereits vorhandener Techniken, wobei Jeff Hawkins jedoch nicht ausreichend auf die Ursprünge seiner Ideen verweist. Zudem hat Jeff Hawkins das in der Wissenschaft für Publikationen übliche Peer Review und damit eine fundierte Prüfung durch Wissenschaftler umgangen. Hierbei gilt es jedoch zu beachten, dass Hawkins nicht aus dem akademischen, sondern aus dem industriellen Umfeld stammt.
Literatur
- Jeff Hawkins, Sandra Blakeslee: On Intelligence. Hrsg.: St. Martin’s Griffin. 2004, ISBN 0-8050-7456-2, S. 272 (englisch).
Weblinks
- Numenta. Abgerufen am 16. Juli 2014 (englisch, Homepage von Numenta).
- Evan Ratliff: The Thinking Machine. Wired, März 2007, abgerufen am 16. Juli 2014 (englisch).
- Hierarchischer Temporaler Speicher und HTM-basierte kortikale Lernalgorithmen. (PDF) Numenta, 12. September 2011, abgerufen am 16. Juli 2014.
- Ryan William Price: Hierarchical Temporal Memory Cortical Learning Algorithm for Pattern Recognition on Multi-core Architectures. (PDF) Portland State University, 2011, abgerufen am 16. Juli 2014 (englisch).
- HTM School. Numenta, 2019, abgerufen am 4. August 2019 (englisch).
Open-Source-Implementierungen
- Numenta Platform for Intelligent Computing (NuPIC). Numenta, abgerufen am 16. Juli 2014 (englisch, C++/Python).
- Neocortex – Memory-Prediction Framework. In: Sourceforge. Abgerufen am 16. Juli 2014 (englisch, C++).
- OpenHTM. In: Sourceforge. Abgerufen am 16. Juli 2014 (englisch, C#).
- Michael Ferrier: HTMCLA. Abgerufen am 16. Juli 2014 (englisch, C++/Qt).
- Jason Carver: pyHTM. Abgerufen am 16. Juli 2014 (englisch, Python).
- htm. In: Google Code. Abgerufen am 16. Juli 2014 (englisch, Java).
- adaptive-memory-prediction-framework. In: Google Code. Abgerufen am 16. Juli 2014 (englisch, Java).
Einzelnachweise
- Subutai Ahmad, Jeff Hawkins: Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory. 24. März 2015, arxiv:1503.07469 (englisch).
- Jeff Hawkins: Sensory-motor Integration in HTM Theory, by Jeff Hawkins. In: YouTube. Numenta, 20. März 2014, abgerufen am 12. Januar 2016 (englisch).
- Jeff Hawkins: What are the Hard Unsolved Problems in HTM. In: YouTube. Numenta, 20. Oktober 2015, abgerufen am 12. Januar 2016 (englisch).