Early Stopping
Early Stopping bezeichnet eine Regularisierungstechnik, um Überanpassung bei iterativen Methoden des maschinellen Lernens zu verhindern.
Hintergrund
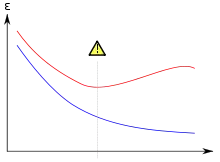
Rot: Generalisierungsfehler
Beide Fehler sinken in den ersten Iterationsschritten. Ab einem bestimmten Punkt steigt der Generalisierungsfehler wieder an.
Beim Training eines Machine-Learning-Modells werden Modellparameter gesucht, mit denen ein definierter Fehler zwischen dem wahren und dem vorhergesagten Label minimiert wird. Dabei ist das Ziel, Parameter zu ermitteln, die eine möglichst gute Generalisierung bieten. Das bedeutet, dass das Modell nicht nur auf dem begrenzen Trainingsdatensatz gut performt, sondern auch auf bisher ungesehenen Daten einen geringen Fehler aufweist. Dieser Fehler wird als Generalisierungsfehler bezeichnet. Ein Modell, das einen geringen Trainingsfehler und einen vergleichsweise hohen Generalisierungsfehler besitzt, nennt man überangepasst. Überanpassung wird durch eine zu hohe Anzahl von Parametern ermöglicht, wodurch die Trainingsdaten (teilweise) auswendig gelernt werden können.
Bei iterativen Trainingsmethoden kann oft beobachtet werden, dass sowohl der Trainingsfehler als auch der Generalisierungsfehler in den ersten Schritten abnehmen, aber ab einem bestimmten Punkt der Generalisierungsfehler steigt, während der Trainingsfehler weiter sinkt.[1]
Regularisierung durch Early Stopping
Anstatt beispielsweise die Anzahl der Parameter zu verringern oder der Fehlerfunktion einen Strafterm hinzuzufügen, wird beim Early Stopping das Training angehalten, sobald eine signifikante Verschlechterung (oder keine (signifikante) Verbesserung) der Generalisierungsperformance über einen vorher definierten Zeitraum festgestellt wird. Der Trainingsalgorithmus gibt anschließend die Modellparameter mit der bis zu diesem Zeitpunkt besten Generalisierungsperformance zurück.[1]
Early Stopping kann als effiziente Hyperparameteroptimierung betrachtet werden, bei der ein Hyperparameter die Anzahl der Trainingsschritte bestimmt.[1]
Da die Ermittlung des Generalisierungsfehlers für Daten mit unbekannter Wahrscheinlichkeitsverteilung nicht möglich ist, wird er in der Praxis oft durch einen auf Validierungsdaten ermittelten Fehler approximiert. Die Trainings- und Validierungsdaten überschneiden sich dabei idealerweise nicht. Zur Aufteilung des Datensatzes in Trainings- und Validierungsdaten kann zum Beispiel ein Kreuzvalidierungsverfahren angewendet werden.
Einzelnachweise
- Ian Goodfellow, Yoshua Bengio, Aaron Courville: Deep Learning. MIT Press, 2016, Kap. 7.8 Early Stopping (deeplearningbook.org).