Audiodatenkompression
Audiodatenkompression (oft auch kurz uneindeutig als Audiokompression bezeichnet) ist eine Datenreduktion („verlustbehafteter“ Algorithmus) oder Datenkompression („verlustfreier“ Algorithmus).
Audiodatenkompression bezeichnet spezialisierte Arten der Datenkomprimierung, um digitale Audiodaten effektiv in ihrer Größe zu reduzieren. Wie bei anderen spezialisierten Arten der Datenkomprimierung (vor allem Video- und Bildkompression) werden spezifische Eigenschaften der entsprechenden Signale mit verschiedenen Möglichkeiten ausgenutzt, um einen Verkleinerungseffekt zu erzielen.
Nicht zu verwechseln ist diese Art der Kompression mit dem Verfahren einer Dynamikeinengung (auch Dynamikkompression genannt), die im Normalfall zum Anheben von leiseren oder Absenken lauterer Passagen in einem Audiosignal verwendet wird und keine Daten einspart (siehe dazu Kompressor).
Verlustfreie Audiodatenkompression
Die verlustfreie Audiodatenkompression oder kürzer verlustfreie Audiokompression ist die verlustfreie Kompression von Audiodaten, also die Erzeugung von gepackten Daten, die eine bitidentische Rekonstruktion des Ausgangssignals erlauben.
Die verlustfreien Audiocodecs unterscheiden sich von generischen Datenkompressionsverfahren dadurch, dass sie speziell an die typische Datenstruktur von Audiodaten angepasst sind und diese daher besser komprimieren als generische Verfahren wie zum Beispiel die Lempel-Ziv-basierten Algorithmen Deflate/ZIP und RAR. Die mit heutigen verlustfreien Verfahren erreichbare Kompressionsrate liegt bei Audio-CD-typischen Inhalten (Musik, 16 Bit/44100 Hz) üblicherweise zwischen 25 und 70 Prozent.
Verwendung
Die Verfahren finden Anwendung in Tonstudios, auf neueren Tonträgern wie der SACD und der DVD-Audio sowie zunehmend auch in privaten Musikarchiven qualitätsbewusster Musikhörer, die beispielsweise Generationsverluste vermeiden wollen. Daneben sind viele Datenkompressionsverfahren aus dem Audiobereich auch für andere Signale wie beispielsweise biologische Daten, medizinische Kurven oder seismische Daten interessant.
Problemstellung
Die Mehrzahl der Tonaufnahmen sind Töne, aufgenommen aus der realen Welt; solche Daten sind schwer zu komprimieren. Ähnlich wie sich Fotos nicht so gut komprimieren lassen wie computergenerierte Bilder, obwohl auch computergenerierte Tonabfolgen sehr komplizierte Wellenformen enthalten können, die sich mit vielen Kompressionsalgorithmen nur schlecht verkleinern lassen.
Außerdem ändern sich die Werte der Audiosamples sehr schnell und es gibt selten Folgen von gleichen Bytes, weswegen allgemeine Datenkompressionsalgorithmen nicht gut funktionieren.
Sparsamere Repräsentationen finden
Die PCM-Darstellung von Schallwellen lässt sich ihrer Natur nach im Allgemeinen schwer vereinfachen ohne eine zwangsweise verlustbehaftete Konvertierung in Frequenzfolgen, wie sie im menschlichen Ohr stattfinden.
Im Falle von Audiodaten können
- Ähnlichkeiten zwischen den (Stereo-)Kanälen und
- Abhängigkeiten zwischen aufeinanderfolgenden Abtastwerten (durch Dekorrelation) sowie danach
- Entropie der Abtastwerte des Restsignales
ausgenutzt werden.
Kanalkopplung
Durch Kopplung von Kanälen können Abhängigkeiten zwischen Kanälen ausgebeutet werden. Indem ein Kanal über den Unterschied zu einem vorhandenen oder einem neuen Mittenkanal beschrieben wird, kann die wiederholte Beschreibung gemeinsamer Inhalte vermieden werden.
Die Differenzsignale können entweder verlustfrei gespeichert, quantisiert und entsprechend verlustbehaftet kodiert werden oder beispielsweise auch zu parametrischen Beschreibungen abstrahiert gespeichert werden.
Vorhersage
Zur Ausbeutung von Abhängigkeiten zwischen aufeinanderfolgenden Abtastwerten wird eine Dekorrelation vorgenommen, indem versucht wird, den Verlauf der Klangkurve vorherzusagen. Dadurch kann ein Rest-/Differenzsignal errechnet werden, das bei guter Vorhersage entsprechend schwach ist (das heißt wenig signifikante Stellen hat) und darüber hinaus mit einer Entropiekodierungsmethode komprimiert werden kann. Dazu werden in den meisten Fällen Abtastwerte mit ausgefeilten, sich anpassenden (adaptiven) Vorhersageverfahren aus anderen extrapoliert.
Entropiekodierung
Die Entropiekodierung des dekorrelierten Restsignales nutzt für dessen Abtastwerte unterschiedliche Auftrittswahrscheinlichkeiten und Ähnlichkeiten aus. Hierfür werden oft beispielsweise Rice-Codes verwendet.
Ein Verfahren ist symmetrisch, wenn zum Dekodieren das Signal die gleichen Schritte wie bei der Kodierung umgekehrt durchläuft und der Rechenaufwand für das Kodieren von dem für das Dekodieren nötigen Rechenaufwand abhängt.
Verfahrensmerkmale
Bei verlustfreien Codecs sollten definitionsgemäß Qualitätsunterschiede des Audiosignals ausgeschlossen sein, Verfahrensunterschiede liegen hier in folgenden Merkmalen:
- Kompressionsrate
- direktes Abspielen der komprimierten Daten
- Anspringen beliebiger Positionen in einem Audiostrom
- Ressourcenbedarf der Kompression sowie der Dekompression
- Soft- und Hardwareunterstützung
- Flexibilität im Umgang mit Metadaten
- Art der Lizenz
- Plattformübergreifende Verfügbarkeit
- Unterstützung von Mehrkanal-Signalen
- Unterstützung unterschiedlicher Auflösungen – zeitlich (Abtastfrequenz) beziehungsweise der Klangtiefe (Abtasttiefe)
- eventuell zusätzliche verlustbehaftete, oder sogar Hybrid-Modi (verlustbehaftete + Korrekturdatei)
- Streaming-Unterstützung
- Fehlertoleranz/-korrekturmechanismen
- Eingebettete Prüfsummen zur schnellen Überprüfung einer Datei auf Vollständigkeit
- Symmetrische und asymmetrische Kodiermöglichkeiten (Un-/Abhängigkeit der Dekodier- von der Kodiergeschwindigkeit)
- Unterstützt die Erstellung selbstentpackender Dateien
- Kompatibilität zum Replay-Gain-Standard
- Unterstützung eingebetteter Cuesheets
- eventuelle Speicherung von Kopfdaten des Originalformates
Verlustfreie Audioformate
Verlustfreie Audioformate sind:
- Adaptive Transform Acoustic Coding – Advanced Lossless (ATRAC)
- Apple Lossless, auch Apple Lossless Encoding oder Apple Lossless Audio Codec (ALAC)
- Free Lossless Audio Codec (FLAC)
- Lossless Audio (LA)
- Meridian Lossless Packing (MLP)
- Monkey’s Audio (APE)
- MPEG-4 Audio Lossless Coding (ALS)
- MPEG-1 Audio Layer 3 (mp3HD)
- OptimFROG
- Shorten
- TAK Toms verlustfreier Audiokompressor
- The True Audio (TTA)
- WavPack (WV/WVC)
- Windows Media Audio Lossless (WMA Lossless)
- Emagic ZAP
Verlustbehaftete Audiodatenkompression
Als verlustbehaftete Audiodatenkompression, auch weniger präzise, kürzer Verlustbehaftete Audiokompression beziehungsweise in entsprechendem Kontext Verlustbehaftete Kompression oder englisch „lossy“ (verlustbehaftet), bezeichnet man Verfahren, die eine Datenreduktion durchführen und gezielt weniger relevante Signalanteile in der Regel näherungsweise mit minderer Präzision abspeichern oder unwiederbringlich verwerfen.
Bei simplen Verfahren wie μ-law und A-law werden nur die einzelnen Abtastpunkte des PCM-Datenstroms anhand einer logarithmischen Kennlinie abhängig vom Pegel quantisiert. Verfahren wie ADPCM nutzen bereits die Korrelationen aufeinanderfolgender Abtastpunkte aus. Moderne Verfahren basieren meist auf Frequenztransformationen in Verbindung mit psychoakustischen Modellen, die die Eigenschaften des menschlichen (Innen-)Ohres nachbilden und entsprechend dessen Unzulänglichkeiten die Darstellungspräzision maskierter Signalanteile reduziert. Für spezialisierte Verfahren werden weiterhin Modelle eingesetzt, die den Klangerzeuger nachbilden und so eine Klangsynthese beim Empfänger beziehungsweise im Dekoder ermöglichen, womit dann ein großer Signalanteil mit Parametern zur Steuerung des Synthesizers beschrieben werden kann.
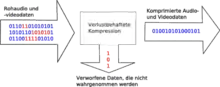
Psychoakustik
Die meisten modernen Verfahren versuchen nicht den mathematischen Fehler zu reduzieren, sondern die subjektive menschliche Wahrnehmung der Tonfolgen zu verbessern. Da das menschliche Ohr nicht alle Informationen eines ankommenden Tones analysieren kann, ist es möglich, eine Klangdatei stark zu verändern, ohne dass die subjektive Wahrnehmung des Hörers beeinträchtigt wird. So kann ein Codec zum Beispiel einen Teil der Klanganteile in sehr hohen und sehr tiefen Frequenzbereichen, die am Rande des Hörbereiches liegen, mit stärker verminderter Präzision speichern oder ausnahmsweise sogar komplett verwerfen. Auch können leise Klänge mit geringerer Genauigkeit wiedergegeben werden, da sie durch laute Klänge benachbarter Frequenzen verdeckt („maskiert“) sind. Eine andere Art der Überlagerung ist, dass ein leiser Ton nicht erkennbar ist, wenn er unmittelbar vor oder nach einem lauten Ton kommt (zeitliche Maskierung). Ein solches Modell der Ohr-Gehirn-Verbindung, das für diese Effekte verantwortlich ist, wird häufig psychoakustisches Modell genannt (auch: Psychoaccoustic Model, Psycho-model oder Psy-model). Ausgenutzt werden hierbei Eigenschaften des menschlichen Gehörs wie Frequenzgruppenbildung, Hörbereichsgrenzen, Maskierungseffekte und Signalverarbeitung des Innenohrs.
Die meisten der nach einem psychoakustischen Modell arbeitenden verlustbehafteten Kompressionsalgorithmen basieren auf simplen Transformationen, wie der modifizierten diskreten Kosinustransformation (MDCT), welche die aufgenommene Wellenform in ihre Frequenzabfolgen umwandeln und damit näherungsweise Repräsentationen des Ausgangsmaterials finden, die sich effizient quantifizieren lassen, da die Repräsentation der menschlichen Wahrnehmung näher ist. Einige moderne Algorithmen benutzen Wavelets, aber es ist noch nicht sicher, ob solche Algorithmen besser funktionieren als die auf MDCT basierenden.
Qualität
Verlustbehaftet komprimierende Verfahren erlauben prinzipbedingt nur die Rekonstruktion eines näherungsweise ähnlichen Signals. Mit vielen Verfahren kann Transparenz erreicht werden, also für die Hörwahrnehmung (des Menschen) ein Grad der Ähnlichkeit erreicht werden, bei dem kein Unterschied zum Original wahrnehmbar ist. Unterhalb der Transparenzschwelle werden die ins Signal eingeschleppten Kompressionsartefakte hörbar. Am oberen Ende der Skala steht die Transparenz, bei der kein Unterschied zum Original wahrnehmbar ist. Sie kann in Blindhörtests festgestellt werden. Meist stellt sich grob ein Schwellwert in der Höhe der Bitrate dar, ab dem Transparenz möglich wird, wobei ein mehr oder minder großes Risiko auf Ausnahmesituationen bleibt, die (noch) nicht transparent kodiert werden können. Dieses Risiko sinkt in der Regel bei weiterer Erhöhung der Bitrate und hängt unter anderem auch von der Architektur des jeweiligen Verfahrens ab. Hier können somit modernere Verfahren oft mit besseren Mechanismen zur Beherrschung von Problemstellen aufwarten. Unterhalb der Transparenzschwelle des Kompressionsverfahrens werden die Kompressionsartefakte eventuell zu einem gewissen Grad noch von den Störungen maskiert, die minderwertige Geräte in die Wiedergabe einbringen. Bei wahrnehmbaren Kompressionsartefakten ist ein objektiver Vergleich unterschiedlicher Verfahren deutlich schwerer, da er oft weitgehend von den subjektiven Vorlieben des Hörers abhängt. Maßstäbe können hier zum Beispiel die Natürlichkeit des Klangbildes sein – zum Beispiel ob die Artefakte natürlich auftretenden Störungen wie Rauschen ähneln. Am unteren Ende der Qualitätsskala wird bei Sprach-Codecs üblicherweise noch die Verständlichkeitsschwelle betrachtet, unterhalb derer Sprachinhalte nicht mehr verständlich reproduziert werden können.
Kompressionsartefakte
Bei auf Frequenztransformationen basierenden Kompressionsverfahren ergeben sich als typische Artefakte unter anderem ein merklich ausgedünntes, ärmeres Klangspektrum, was zum Beispiel zu Zwitscherartefakten („birdie artifact“) oder charakteristisch dumpf blubberndem oder gurgelndem Klang führt und vorauseilende Echos (englisch „pre-echo artifacts“) bei scharfen, energiereichen Klangereignissen (Transienten).
Generationsverlust
Da die verlustbehaftet arbeitenden Teile eines Kompressionsverfahrens in der Regel bei jedem Durchlauf (weiteren) Verlust erzeugen, ergibt sich ein sogenannter Generationsverlust, wenn zum Beispiel beim Transkodieren eine Datei komprimiert, dann dekomprimiert und anschließend wieder komprimiert wird. Das passiert in der Praxis vor allem, wenn eine Audio-CD aus verlustbehafteten Audiodateien gebrannt wird (Audio-CDs sind unkomprimiert) und das Material später wieder ausgelesen und komprimiert wird. Dieses macht verlustbehaftete Dateien ungeeignet für Anwendungen in professionellen Tonbearbeitungsbereichen („Data reduction is Audio destruction“). Allerdings sind solche Dateien sehr beliebt bei Endbenutzern, da ein Megabyte je nach Komplexität des Tonmaterials ungefähr für eine Minute Musik bei annehmbarer Qualität reicht, was einer Kompressionsrate von etwa 1:11 entspricht.
Ausnahmen bilden hier beispielsweise verlustbehaftete Vorfilter zur Kombination mit verlustfreien Verfahren wie lossyWAV[1], die die PCM-Daten bearbeiten, um nachfolgend eine stärkere Kompression mit einem (bestimmten) verlustfrei arbeitenden Kompressionsverfahren zu erreichen. Dabei können die vom Vorfilter erzeugten Daten – zumindest solange sie danach nicht weiter verändert werden – natürlich mit dem verlustfrei arbeitenden Kompressionsverfahren beliebig oft komprimiert und dekomprimiert werden, ohne weitere Verluste zu erleiden.
Qualitätseinschätzung
Die folgenden Einschätzungen basieren auf verschiedenen Hörtests von hydrogenaudio.org. Dieses Forum stellt eine Plattform dar, die von interessierten und versierten Benutzern sowie von den Entwicklern verschiedener Audiokompressionsverfahren wie MP3 (LAME-Encoder), Vorbis oder Nero-AAC besucht wird. Durch die hohe Anzahl an teilnehmenden Testpersonen ergeben sich statistisch abgesicherte Qualitätsaussagen.
Seit der Entwicklung von MP3 (um 1987) über die anfängliche Nutzung des Codecs (um 1997–2000) bis zum weltweit meistgenutzten Audio-Format (seit etwa 2003) wurde die Ausgabequalität stetig verbessert. Ebenso wurden weitere Formate wie Vorbis, WMA oder AAC entwickelt, um eine Alternative zu MP3 darzustellen oder dieses langfristig abzulösen. Auch diese Formate wurden stetig weiterentwickelt.
Eine MP3-Datei mit einer Bitrate von ~128 kbit/s klang 1997 noch sehr bescheiden. Die versprochene CD-ähnliche Qualität wurde damals noch nicht erreicht. Im Jahr 2005, so belegen damalige Hörtests,[2] bot der Encoder LAME für dasselbe Format bei ~128 kbit/s für die deutliche Mehrheit der Hörer bereits eine transparente, also von der Originalaufnahme nicht unterscheidbare Qualität.
Eine vergleichbare Qualität ist mit dem AAC-Format laut einem Hörtest von August 2007[3] bereits mit 96 kbit/s zu erreichen.
Die Hörtests aus den 00er Jahren mit Bitraten von 48 und 64 kbit/s zeigen, dass bei diesen niedrigen Bitraten bereits eine Qualität erzielt werden kann, die für den Einsatz in portablen Geräten oder für Webradio geeignet ist.[3][4]
Mit einem qualitativ guten Encoder und dem richtigen Format konnte bereits bei 96 bis 128 kbit/s eine Qualität erreicht werden, die die deutliche Mehrheit der Benutzer nicht von der CD unterscheiden kann.
Verlustbehaftete Audioformate

Bei den Beispielen werden, soweit bekannt, auch die Bitraten angegeben, bei denen eine komprimierte Datei von den meisten Personen nicht mehr vom Original unterscheidbar ist, also transparent klingt – bei konzentriertem Zuhören mit gutem Zubehör und einem ausgereiften Codec des jeweiligen Kompressionsschemas; abhängig von der Art der Musik. Es muss jedoch beachtet werden, dass Transparenz nicht von jedem bei der gleichen Bitrate empfunden wird. Die Qualität der D/A-Wandler, Verstärker und Boxen spielt hier eine wichtige Rolle. Während auf Studio-Equipment eine verlustbehaftete Kompression meist sehr deutlich, auch für Laien, hörbar ist, kann sie auf minderwertigen Abspielgeräten auch für den Profi nicht vom Original unterscheidbar sein. Die Angaben sind daher ein Anhaltswert für den durchschnittlichen Hörer mit durchschnittlicher Ausrüstung. Die Bitrate von CDs beträgt 1411,2 kbit/s (Kilobit pro Sekunde).
Für Vergleiche diverser Audiocodecs siehe Weblinks.
- AC-3, auch Dolby Digital oder ähnlich genannt
- AAC (MPEG-2, MPEG-4): 96–320 kbit/s
- ATRAC (MiniDisc): 292 kbit/s
- ATRAC3 (MiniDisc im MDLP-Modus): 66–132 kbit/s
- ATRAC3plus (bei Hi-MD sowie anderen portablen Audiogeräten von Sony): 48–352 kbit/s
- DTS
- MP2: MPEG-1 Layer 2 Audio Codec (MPEG-1, MPEG-2): 280–400 kbit/s
- MP3: MPEG-1 Layer 3 Audio Codec (MPEG-1, MPEG-2, LAME): 180–250 kbit/s
- mp3PRO
- Musepack: 160–200 kbit/s (Open Source)
- Ogg Vorbis: 160–220 kbit/s (Open Source)
- Opus
- WMA
- LPEC
- TwinVQ
- AMR-WB
Siehe auch
- Unterbrechungsfreie Wiedergabe
- Mean Opinion Score (Beurteilung der Klangqualität von Kompressionsverfahren)
- Spektralbandreplikation (Spectral Band Replication, SBR)
- Teilbandkodierung
Literatur
- Roland Enders: Das Homerecording Handbuch. 3. Auflage. Carstensen, München 2003, ISBN 3-910098-25-8.
- Thomas Görne: Tontechnik. 1. Auflage. Carl Hanser, Leipzig 2006, ISBN 3-446-40198-9.
- R. Beckmann: Handbuch der PA-Technik, Grundlagen-Komponenten-Praxis. 2. Auflage. Elektor, Aachen 1990, ISBN 3-921608-66-X.
- A. Lerch: Bitratenreduktion. In: Stefan Weinzierl (Hrsg.): Handbuch der Audiotechnik. 1. Auflage. Springer, Berlin 2008, ISBN 978-3-540-34300-4, S. 849–884.
Weblinks
Einzelnachweise
- http://wiki.hydrogenaudio.org/?title=lossyWAV
- Results of Public, Multiformat Listening Test @ 128 kbps (December 2005) (Memento vom 5. Juni 2008 im Internet Archive)
- Results of Public, Multiformat Listening Test @ 48 kbps (November 2006) (Memento vom 5. Juni 2008 im Internet Archive), auf www.listening-tests.info, November 2006 (englisch).
- Results of Public, Multiformat Listening Test @ 64 kbps (July 2007) (Memento vom 5. Juni 2008 im Internet Archive)