Algorithmus von Hopcroft und Karp
Der Algorithmus von Hopcroft und Karp (1973 von John E. Hopcroft und Richard M. Karp entwickelt) dient in der Graphentheorie zur Bestimmung eines maximalen Matchings in einem bipartiten Graphen. Er geht aus von dem Matching, die keine Kanten enthält, und konstruiert dazu alternierende Pfade zwischen noch ungepaarten Knoten. Jeder solche Pfad liefert eine Vergrößerung (Augmentierung) des Matchings um eine Kante.
Augmentierende Pfade
Ist zu einem Graphen mit Kantenmenge ein Matching gegeben, so betrachten wir zusammenhängende Teilgraphen, die Bäume sind, also keinen Zyklus enthalten und die bestehen aus


- einem ungepaarten Knoten als Wurzel,
- gepaarten Knoten, die sich von der Wurzel aus innerhalb des Baumes erreichen lassen auf alternierenden Pfaden gerader Kantenzahl. Alternierend heißt, dass die Kanten des Pfades abwechselnd zu gehören und nicht zu gehören. Diese Knoten haben also geraden Abstand von der Wurzel.
- allen Knoten und Kanten entlang der alternierenden Pfade. Dadurch kommen auch Knoten hinzu, die ungeraden Abstand von der Wurzel haben.

Eine Vereinigungsmenge solcher Bäume, die keine gemeinsamen Knoten haben, heißt Wald.
Wenn Knoten und aus zwei verschiedenen Bäumen des Waldes, die jeweils geraden Abstand von ihrer Wurzel haben, durch die Kante verbunden sind, so kann diese Kante nicht zu gehören, denn die Knoten sind ja schon durch je eine andere Kante innerhalb des Baumes gepaart, es sei denn, es handelt sich um die Wurzel, die sowieso ungepaart ist. Der Pfad mit Kantenmenge von der Wurzel des einen Baumes über zur Wurzel des anderen Baumes ist dann ein alternierender Pfad mit ungepaartem Anfangs- und Endknoten. Ein solcher Pfad wird -augmentierender Pfad genannt, denn ist ein Matching, das eine Kante mehr enthält als .






Umgekehrt gilt, dass ein Matching , das mehr Kanten enthält als , einen Teilgraph mit Kantenmenge ergibt, in dem alle Pfade zwischen und alternieren, und von denen mindestens Pfade -augmentierend ohne gemeinsame Knoten sein müssen. ist also genau dann ein maximales Matching, wenn es keinen -augmentierenden Pfad gibt.



Ungarische Wälder
Bei der Definition der betrachteten Wälder wurde bisher nicht vorausgesetzt, dass ein bipartiter Graph vorliegt. In einem bipartiten Graphen gilt aber mehr: Dort liegen die Knoten geraden Abstandes von ihrer Wurzel in oder , je nachdem wo die Wurzel auch liegt. Wenn es dann im Wald keine zwei Knoten und mit wie im letzten Abschnitt gibt und der Wald auch nicht mehr unter Einhaltung der genannten Eigenschaften vergrößert werden kann, heißt er ein ungarischer Wald. Wegen der Bipartitheit lässt sich dann zeigen, dass das Matching genau dann ein maximales Matching ist, wenn es zu ihm einen ungarischen Wald gibt.



Algorithmus
Der folgende Algorithmus ist eine Vorstufe zum Algorithmus von Hopcroft und Karp. Er konstruiert zu einem bipartiten Graphen mit Matching einen Wald mit den genannten Eigenschaften, der
- entweder ein ungarischer Wald ist
- oder einen -augmentierenden Pfad liefert.
- Beginne mit dem Wald, der alle ungepaarten Knoten als Wurzeln enthält, aber keine Kanten.
- Suche eine Kante von einem Knoten des Waldes mit geradem Abstand von seiner Wurzel zu einem Knoten , der nicht zum Wald gehört oder geraden Abstand von seiner Wurzel hat. Falls es keinen solchen Knoten mehr gibt, ist der Wald ein ungarischer Wald. Beende den Algorithmus.
- Falls geraden Abstand von seiner Wurzel hat, gibt es einen Pfad gerader Länge von einem ungepaarten Knoten nach . Gib den -augmentierenden Pfad von über nach zurück und beende den Algorithmus.
- Falls nicht zum Wald gehört, ist gepaart, etwa : Füge die Knoten und sowie die Kanten und zum Wald hinzu und gehe zurück zu Schritt 2.



Zu Beginn wird der Algorithmus mit ausgeführt. Falls er in Schritt 3 mit einem -augmentierenden Pfad endet, wird durch ersetzt und der Algorithmus erneut durchgeführt. Der Fall, dass der Algorithmus in Schritt 2 mit einem ungarischen Wald endet, wobei dann eine maximales Matching ist, muss nach spätestens Durchläufen des Algorithmus eintreten, weil das Matching im anderen Fall jeweils um zwei Knoten vergrößert wird. Die Laufzeit bei einmaliger Durchführung des Algorithmus ist proportional zur Kantenzahl , die Gesamtlaufzeit bei mehrmaliger Durchführung also proportional zum Produkt aus Kanten- und Knotenzahl.



Beispiel
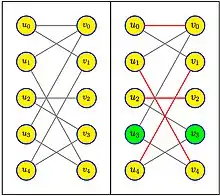

Der bipartite Graph im Beispiel hat 10 Knoten und 10 Kanten. Im linken Teil sind vor der ersten Phase alle Knoten frei, das Matching ist leer. Alle augmentierenden Pfade werden auf eine einzelne Kante zwischen einem Knoten in und einem Knoten in reduziert. Eine Breitensuche wählt zum Beispiel die Kanten , indem sie für jeden Knoten in den freien Knoten in mit dem kleinsten Index auswählt. Diese Menge von Pfaden ist maximal, alle haben die gleiche Länge 1, das erhaltene Matching hat die Größe 4 und es verbleiben zwei freie Knoten, und .



In der zweiten Phase geht es darum, die Pfade mit minimaler Längenzunahme ausgehend vom einzigen freien Knoten von oder vom einzigen freien Knoten von zu finden. Der angegebene Pfad wechselt zwischen schwarzen Kanten außerhalb des Matchings und roten Kanten innerhalb des Matchings. Er hat die Länge 5. Wir können sehen, dass es keinen Pfad der Länge 3 gibt, aber es gibt einen Pfad der Länge 7, nämlich . Das Matching, das sich aus der symmetrischen Differenz des vorherigen Matchings mit dem Weg der Länge 5 ergibt, ergibt im Beispiel das Matching der Größe 5. Es ist maximal, weil es keine freien Knoten mehr gibt.


Gleichzeitige Augmentierung mehrerer Pfade
Die Gesamtlaufzeit des Algorithmus kann verringert werden, wenn mehrere -augmentierende Pfade gleichzeitig betrachtet werden. Es sei die Länge des kürzesten -augmentierenden Pfades. Wir betrachten -augmentierende knotendisjunkte Pfade der Länge , denen sich kein weiterer -augmentierender Pfad der Länge knotendisjunkt hinzufügen lässt. Dann lässt sich zeigen, dass



Der genannte Algorithmus kann so zum Algorithmus von Hopcroft und Karp erweitert werden, dass er nicht nur einen augmentierenden Pfad zurückgibt, sondern eine Menge augmentierender Pfade wie gerade betrachtet. Dazu müssen Schritt 2 und 3 als Breitensuche durchgeführt werden, wobei die konstruierten Pfade im Wald erst dann verlängert werden, wenn keine neuen Pfade der bisherigen Länge mehr zu finden sind. Sobald ein Pfad zu einem ungepaarten Knoten führt, also ein augmentierender Pfad ist, brauchen keine Pfade noch größerer Länge mehr betrachtet zu werden.
Ist ein maximales Matching und , so liefert der so erweiterte Algorithmus nach Durchläufen ein Matching mit und knotendisjunkte -augmentierende Pfade, deren Länge mindestens ist. Weil keiner der Knoten in zweien dieser Pfade enthalten ist, muss sein, also muss das maximale Matching nach spätestens weiteren Durchläufen erreicht sein. Die Gesamtlaufzeit des Algorithmus von Hopcroft und Karp ist demnach proportional zum Produkt aus Kantenzahl und Quadratwurzel der Knotenzahl.





Vergleich mit anderen Algorithmen
Für dünne Graphen weist der Algorithmus von Hopcroft und Karp weiterhin die beste Worst-Case-Laufzeit auf. Für dichte Graphen erzielt ein neuerer Algorithmus eine etwas bessere Laufzeit.[1]
Dieser Algorithmus basiert auf der Verwendung des Goldberg-Tarjan-Algorithmus. Wenn das durch diesen Algorithmus erzeugte Matching nahezu optimal ist, wird zum Algorithmus von Hopcroft und Karp gewechselt. Mehrere Autoren haben experimentelle Vergleiche von Algorithmen für bipartite Matchings durchgeführt. Ihre Ergebnisse zeigen tendenziell, dass der Algorithmus von Hopcroft und Karp in der Praxis nicht so gut ist wie in der Theorie. Er wird sowohl durch einfachere Strategien für die Suche nach augmentierenden Pfaden als auch durch Push-Relabel-Techniken übertroffen.[2]
Programmierung
Das folgende Beispiel in der Programmiersprache C++ zeigt die Implementierung des Algorithmus von Hopcroft und Karp für einen bipartiten Graphen. Der bipartite Graph wird als Klasse BipartiteGraph deklariert. Die Methode HopcroftKarp verwendet Breitensuche und Tiefensuche. Bei der Ausführung des Programms wird die Methode main verwendet, die die Liste der markierten Knoten auf der Konsole ausgibt.[3]
#include <list>
#include <queue>
#include <iostream>
using namespace std;
#define NIL 0
#define INF INT_MAX
// Deklariert den Datentyp für die Knoten des Graphen
struct Node
{
int index;
string value;
Node* next;
};
// Deklariert die Klasse für den bipartiten Graphen
class BipartiteGraph
{
int count1, count2; // Anzahl der Knoten auf der linken und rechten Seite des bipartiten Graphen
list<Node>* adjacencyList; // Anzahl der Knoten auf der linken und rechten Seite des bipartiten Graphen
Node* pair1, * pair2; int distance[]; // Basiszeiger, die in der Methode HopcroftKarp verwendet werden
// Deklariert die Interfaces für die Methoden
public:
BipartiteGraph(int count1, int count2); // Konstruktor
void AddEdge(Node* startNode, Node* targetNode);
bool BreadthFirstSearch();
bool DepthFirstSearch(Node* startNode);
int HopcroftKarp();
};
// Gibt die Matchingzahl des maximalen Matching zurück
int BipartiteGraph::HopcroftKarp()
{
pair1 = new Node[count1 + 1]; // Speichert ein Paar von Knoten, wobei pair1[u] eine Ecke auf der linken Seite des bipartiten Graphen ist. Wenn nicht vorhanden, wird der Nullzeiger NIL gespeichert.
pair2 = new Node[count2 + 1]; // Speichert ein Paar von Knoten, wobei pair1[v] eine Ecke auf der rechten Seite des bipartiten Graphen ist. Wenn nicht vorhanden, wird der Nullzeiger NIL gespeichert.
// Initialisiert die Paare mit dem Nullzeiger NIL
for (int i = 0; i <= count1; i++)
{
(&pair1)[i] = NIL;
}
for (int i = 0; i <= count2; i++)
{
(&pair2)[i] = NIL;
}
int result = 0; // Initialisierung
while (BreadthFirstSearch())
{
for (int i = 1; i <= count1; i++)
{
Node* node = &pair1[i];
if (node == NIL && DepthFirstSearch(node))
{
result++;
}
}
}
return result;
}
// Gibt true zurück, wenn es einen augmentierenden Pfad gibt, sonst false
bool BipartiteGraph::BreadthFirstSearch()
{
queue<Node> nodeQueue;
for (int i = 1; i <= count1; i++)
{
Node* node = &pair1[i];
if (node == NIL)
{
distance[i] = 0;
nodeQueue.push(*node);
}
else
{
distance[i] = INF;
}
}
distance[NIL] = INF;
while (!nodeQueue.empty())
{
int currentIndex = nodeQueue.front().index;
nodeQueue.pop();
if (distance[currentIndex] < distance[NIL])
{
list<Node>::iterator i;
for (i = adjacencyList[currentIndex].begin(); i != adjacencyList[currentIndex].end(); ++i)
{
Node* node = &pair2[(*i).index];
int index = (*node).index;
if (distance[index] == INF)
{
distance[index] = distance[currentIndex] + 1;
nodeQueue.push(*node);
}
}
}
}
return (distance[NIL] != INF);
}
// Gibt true zurück, wenn es einen augmentierenden Pfad mit startNode gibt, sonst false
bool BipartiteGraph::DepthFirstSearch(Node* startNode)
{
int startIndex = startNode->index; //
if (startNode != NIL)
{
list<Node>::iterator i;
for (i = adjacencyList[startIndex].begin(); i != adjacencyList[startIndex].end(); ++i)
{
Node j = *i;
if (distance[pair2[startIndex].index] == distance[startIndex] + 1)
{
if (DepthFirstSearch(&pair2[startIndex]))
{
pair2[startIndex] = *startNode;
pair1[startIndex] = j;
return true;
}
}
}
distance[startIndex] = INF; // Es gibt keinen augmentierenden Pfad, der mit startNode beginnt.
return false;
}
return true;
}
// Konstruktor mit der Anzahl count1 und count2
BipartiteGraph::BipartiteGraph(int count1, int count2)
{
this->count1 = count1;
this->count2 = count2;
adjacencyList = new list<Node>[count1 + 1];
}
// Diese Methode verbindet die Knoten startNode und targetNode miteinander.
void BipartiteGraph::AddEdge(Node* startNode, Node* targetNode)
{
adjacencyList[(*startNode).index].push_back(*targetNode);
}
// Hauptmethode, die das Programm ausführt
int main()
{
// Deklariert und initialisiert 4 Knoten
Node node1 = Node{ 1, "A", NIL };
Node node2 = Node{ 2, "B", NIL };
Node node3 = Node{ 3, "C", NIL };
Node node4 = Node{ 4, "D", NIL };
// Verbindet Knoten des Graphen miteinander
BipartiteGraph bipartiteGraph(4, 4);
bipartiteGraph.AddEdge(&node1, &node2);
bipartiteGraph.AddEdge(&node1, &node3);
bipartiteGraph.AddEdge(&node2, &node1);
bipartiteGraph.AddEdge(&node3, &node2);
bipartiteGraph.AddEdge(&node4, &node2);
bipartiteGraph.AddEdge(&node4, &node4);
cout << "Size of maximum matching is " << bipartiteGraph.HopcroftKarp(); // Ausgabe auf der Konsole
}
Literatur
- Hubertus Th. Jongen: Optimierung B. Skript zur Vorlesung. Verlag der Augustinus-Buchhandlung, Aachen, ISBN 3-925038-19-1
Einzelnachweise
- H. Alt, N. Blum, K. Mehlhorn, M. Paul, Institute of Computing, University of Campinas: Computing a maximum cardinality matching in a bipartite graph in time
- Joao C. Setubal, Institute of Computing, University of Campinas: Sequential and Parallel Experimental Results with Bipartite Matching Algorithms
- GeeksforGeeks: Hopcroft–Karp Algorithm for Maximum Matching