Suffix-Array-Induced-Sorting
Suffix-Array-Induced-Sorting (kurz SAIS) stellt ein Verfahren in der Informatik dar, mit dem Suffixarrays für beliebige Texte in linearer Zeit konstruiert werden können. Die Idee besteht darin, durch Rekursion festgelegte Suffixe vorzusortieren um dann durch mehrere Durchläufe des Textes die verbleibenden Suffixe einordnen zu können. Dadurch sortiert dieses Verfahren Suffixe besonders effizient.
Verfahren des Algorithmus
Im Folgenden wird der Algorithmus für einen Text angewendet, der ein Suffixarray konstruiert. Mit wird das Suffix von ab Index angegeben.[1]




- Klassifiziere alle Suffixe im Text mit (smaller) oder (larger), in dem der Text von rechts nach links durchlaufen wird. Ein Zeichen beziehungsweise Suffix wird hierbei als klassifiziert, wenn das nachfolgende Suffix lexikographisch größer ist, sonst als .
- Kennzeichne ein Suffix vom Typ mit , wenn dessen Vorgänger lexikographisch größer ist
- Teile in Buckets auf. Buckets stellen hier Intervalle in dar, in denen alle Suffixe mit dem gleichen jeweiligen Zeichen beginnen.
- Teile die Buckets in - und -Buckets auf. Innerhalb eines oberen Buckets stehen die -Buckets vor den -Buckets.
- Sortiere die -Suffixe lexikographisch und schreibe sie in ihre jeweiligen -Buckets.
- Scanne von links nach rechts. Falls an Stelle ein Suffix vorhanden ist und vom Typ ist, dann schreibe an die nächste freie Stelle im Typ--Bucket für den Buchstaben .
- Scanne von rechts nach links. Falls an Stelle ein Suffix vorhanden ist und vom Typ ist, dann schreibe an die nächste freie Stelle im Typ--Bucket für den Buchstaben von rechts nach links.






Schritt 5 kann hierbei noch konkretisiert werden:
- Sortiere die -Substrings und ordne diesen dann Superzeichen zu. Erzeuge daraus Text .
- Berechne Suffixarray für rekursiv.
- Aus folgt dann die Sortierung der -Suffixe Rücktransformation der Indizes von nach .



Beispiel
Als Beispieltext wird hier genommen, das Dollarzeichen am Ende symbolisiert das Ende der Zeichenkette. Die zugehörige Klassifizierung ergibt folgende Zuweisungen:

| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
Nach erfolgter Klassifizierung findet nun die Einteilung in Buckets statt. Hierbei ist zu beachten, dass die Buckets lexikographisch geordnet sind und deren Größe von der Anzahl der jeweils vorkommenden Zeichen abhängt.
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
Es ist zu erkennen, dass der Bucket für das Dollarzeichen ziemlich klein ist, weil dieses Zeichen nur einmal im Text vorkommt. Der Bucket für das Zeichen hingegen ist vergleichsweise groß, weil es sechsmal in auftritt.
Es erfolgt eine weitere Unterteilung in - und -Buckets, wobei die -Buckets vor den -Buckets stehen.
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
| Bucket-Typ | S | L | S | L | L | L | |||||||||
Nun erfolgt die Einordnung der -Suffixe in die jeweiligen Buckets. Für jedes Zeichen werden zuerst alle -Suffixe lexikographisch sortiert und anschließend in das -Bucket geschrieben. Dies erfolgt durch einen Unterschritt, indem man aus den gegebenen -Substrings konstruiert. Zur Vereinfachung werden die Substrings mit Superzeichen versehen. ist dann von der Form
, wobei , , und . Die Superzeichen bis stehen hier für die jeweiligen -Suffixe.






Um generieren zu können, werden den Superzeichen Indizes zugewiesen. Anschließend wird lexikographisch sortiert.
| Index | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| T' | D | B | C | A |
| Stelle in T | 4 | 7 | 11 | 15 |
ist dann von der Form
, wobei , , und .





Mit diesem Schritt ist bereits ein Teil des kompletten Suffixarrays vorsortiert, dieser kann nun in die Buckets eingefügt werden:
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
| Bucket-Typ | S | L | S | L | L | L | |||||||||
| 15 | 7 | 11 | 4 | ||||||||||||
Jetzt erfolgt ein Durchlauf der Buckets von links nach rechts, wird hierbei ein Suffix einer entsprechenden Stelle gefunden, dessen Vorgänger-Suffix vom Typ ist, so wird dieses an die nächst freie Stelle im -Bucket des jeweiligen Zeichens geschrieben.
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
| Bucket-Typ | S | L | S | L | L | L | |||||||||
| 15 | 7 | 11 | 4 | ||||||||||||
| 14 | |||||||||||||||
Dieser Vorgang wird so oft wiederholt, bis das Ende von erreicht wurde. Nach dem Durchlauf enthält folgende Suffixe:
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
| Bucket-Typ | S | L | S | L | L | L | |||||||||
| 15 | 7 | 11 | 4 | ||||||||||||
| 14 | 3 | 6 | 10 | ||||||||||||
| 2 | 13 | 5 | |||||||||||||
| 12 | |||||||||||||||
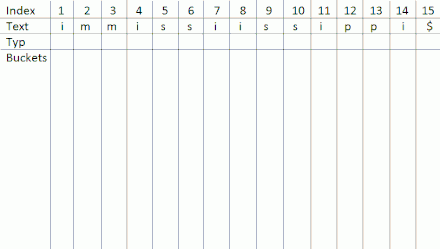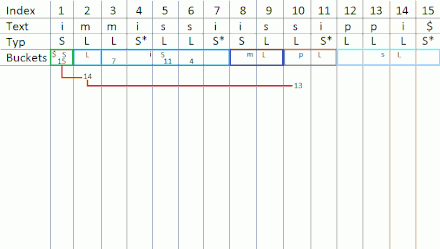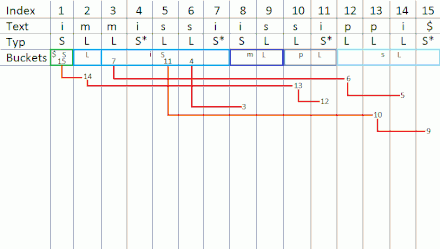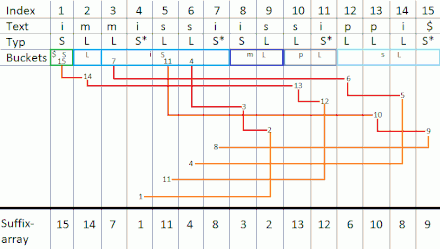
Jetzt erfolgt der Durchlauf von rechts nach links:
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | i | m | m | i | s | s | i | i | s | s | i | p | p | i | $ |
| Typ | S | L | L | S* | L | L | S* | S | L | L | S* | L | L | L | S* |
| Buckets | $ | i | m | p | s | ||||||||||
| Bucket-Typ | S | L | S | L | L | L | |||||||||
| 15 | 7 | 11 | 4 | ||||||||||||
| 14 | 3 | 6 | 10 | ||||||||||||
| 2 | 13 | 5 | |||||||||||||
| 12 | 9 | ||||||||||||||
| 8 | |||||||||||||||
| 4 | |||||||||||||||
| 11 | |||||||||||||||
| 1 | |||||||||||||||
Zuletzt werden die sortierten Suffixe in von links nach rechts zusammengesetzt. Es ergibt sich das sortierte Suffix-Array:

Beispielimplementierung (Pseudocode)
sais(T,A)
for i = n to 1 do
if (T[i] >lex T[i+1])
typ[i] <- L
if (typ[i+1] = S) typ[i+1] = S*
else
typ[i] <- S
begin <- {}
for j = 1 to n do
if (typ[j] = S*)
if (begin = {})
begin <- j
else
end <- p
T’[q] <- CharacterFor(begin,end)
q <- q + 1
begin <- end
If (everyCharacterInT’IsUnique(T’))
A <- countingSort(T’)
return A
else
A <- sais(T’,A)
for k = 1 to n do
if (A[k] != {})
if (typ[A[k]-1] = L)
A <- writeToLBucketForCharacter(T[A[k]-1])
for l = n to 1 do
if (A[l] != {})
if (typ[A[l]-1] = S)
A <- writeToSBucketForCharacter(T[A[l]-1])
return A
Weitere Implementierungen lassen sich unter[2] finden. Darunter auch Implementierungen in Java, sowie C.
Laufzeit
Der Suffix-Array-Induced-Sorting-Algorithmus löst das Problem der Suffix-Sortierung in einer Laufzeit von . Die Beispielimplementierung zeigt dabei drei über den Text iterierende Schleifen von Länge . Die beiden angedeuteten Funktionen writeToLBucketForCharacter und writeToSBucketForCharacter springen innerhalb des Arrays zu dem -Bucket beziehungsweise -Bucket für das angegebene Zeichen. Innerhalb des Buckets wird in einer naiven Implementierung maximal n-mal geprüft werden müssen, ob ein freier Platz im Bucket vorhanden ist, um einen freien Platz zu finden.


Interessant ist das Sortieren der -Suffixe. Hier wird das Problem der Sortierung auf die -Suffixe beschränkt, indem der SAIS-Algorithmus rekursiv darauf angewendet wird. Der übergebene Text T' ist dabei höchstens lang, da per Definition ein nur an jeder zweiten Stelle im Text vorkommen kann. Dadurch ergibt sich folgende kombinierte Laufzeit:


Insgesamt wird also eine Laufzeit von gebraucht.
Verwendung
Der Suffix-Array-Induced-Sorting-Algorithmus findet Verwendung bei der Erstellung eines Suffixbaumes in Zeit. Dabei bildet er nur einen Teilschritt zwischen dem Text und dem entstandenen Suffixbaum.
Siehe auch
Literatur
- Ge Nong, Sen Zhang, Wai Hong Chan: Two Efficient Algorithms for Linear Time Suffix Array Construction. IEEE Trans. Computers 60(10): 1471–1484 (2011)
Einzelnachweise
- Johannes Fischer: Vorlesungsskriptum "Text-Indexierung und Information Retrieval". Wintersemester 2014/2015. Abgerufen am 20. Januar 2015.
- Yuta Mori: Sais Beispielimplementierungen Sais. Abgerufen am 19. Januar 2015.