Semistrukturierte Daten
Als Semistrukturierte Daten bezeichnet man in der Datenbankforschung (Informatik) Informationen, die keiner allgemeinen Struktur unterliegen, sondern einen Teil der Strukturinformation mit sich tragen.
Während bei der strukturierten Datenhaltung ein Datenbankmodell zugrunde liegen muss, das das Aussehen der Datenelemente (Objekte) enthält, fehlt ein solches bei semistrukturierten Daten.
Semistrukturierte Daten müssen keinem Typenmodell unterworfen werden; somit kann sich eine Datensammlung aus semistrukturierten Daten beliebig erweitern. Ein Strukturmodell kann nachfolgend impliziert werden.
Semistrukturierte Daten können mit Hilfe von Grammatik und Lexik in eine Form gebracht werden, die folgende Charakteristika aufweist:
- (E1) Die Datensammlung besteht aus einer oder mehreren Folgen von Objekten.
- (E2) Objekte können entweder in Attribute zerlegt werden (komplexe Objekte) oder sie sind atomare Objekte.
- (E3) Atomare Objekte enthalten Werte eines bekannten, elementaren Datentyps.
Semistrukturierte Daten mit den Eigenschaften (E1), (E2) und (E3) werden als wohlgeformte semistrukturierte Daten bezeichnet.
Das Object Exchange Model (OE-Modell) hat sich de facto als Modell für semistrukturierte Daten durchgesetzt. Daten, die diese Eigenschaften aufweisen, können auch als wohlgeformte XML-Dokumente beschrieben werden.
Ist semistrukturiert nicht auch strukturiert?
Semistrukturierte Daten lassen sich bis auf eine im Folgenden beschriebenen Ausnahme nicht in einem strukturierten Datenbank-Modell unterbringen. Jedoch existieren Verfahren, mit denen Datentypen von semistrukturierten Daten erkannt werden können.
Wenn die Datentypen (Klassen) und damit auch die Relationen bekannt sind, hat man ein Entity-Relationship-Modell. Jedoch gilt für dieses Modell, dass es danach nur noch mit Daten in dieser Struktur gefüllt werden kann, nicht mehr mit weiteren semistrukturierten Daten.
Bei semistrukturierten Dateien, die in einem OE-Modell geformt sind, kann auch behauptet werden: Die formale Beschreibung eines OE-Modells ermöglicht es, ein übereinstimmendes, strukturiertes Datenmodell zu erstellen, das folgendermaßen aussehen kann:
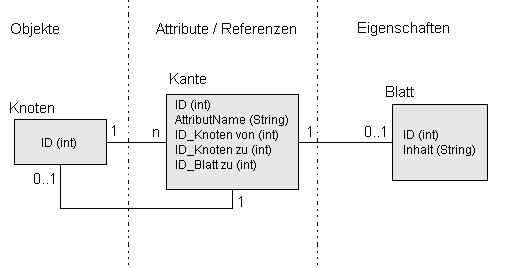 |
| Relationales Datenmodell zur Abbildung von semistrukturierten Objekten |
Dieses Datenmodell enthält nur drei grundlegende Typen: die Knoten, die die Objekte repräsentieren, die Kanten, die Attribute bzw. Referenzen referenzieren, und Blätter, die die Eigenschaften der Referenz repräsentieren.
Somit lassen sich alle semistrukturierten Objekte eines OEM-Modells auch in dieses Datenmodell hineinschreiben. Im Folgenden soll dieses OEM-DB-Modell genannt werden.
Semistrukturierte Daten lassen sich in kein DB-Modell hineinschreiben, außer in Modelle, die nur einen abstrakten Datentyp für alle Objekte bereithalten.
ssd-Notation
Serge Abiteboul, Peter Buneman und Dan Suciu verwenden in ihrer Ausgabe „Data on the Web“ die sog. ssd (semi-structured-data)-Notation1, die allerdings weniger bekannt ist, als die Notation XML. Jedoch bietet diese Notation für semistrukturierte Daten eine sehr kurze und übersichtliche Darstellung:
Datensätze mit Attribut-Werte-Tupels werden folgendermaßen notiert:
- {Hersteller: „Volkswagen“ Modell: „Passat“ km-Stand: „35.600“ }
Die Werte der Attribute können nun wiederum anhand eines Unterdatensatzes definiert sein.
- {Fahrzeug: { Hersteller: { Name : „Volkswagen“ Ort: „Wolfsburg“ } Modell: „Passat“ km-Stand: „35.600“ } }
Bis jetzt ist es möglich, dass ein Element Daten bzw. Attribute-Werte-Paare enthalten kann, und diesem weitere Elemente untergeordnet sein können. Somit ermöglicht die bis jetzt vorgestellte Notation die Darstellung von Daten in Bäumen. Nach der Beschreibung der semistrukturierten Daten als OEM-Modell können zumindest die Knoten-Elemente alle weiteren Elemente der semistrukturierten Datensammlung referenzieren. Dies ist dadurch möglich, dass allen Elementen eine eindeutige ID zugewiesen wird. Z.B. Fahrzeug: &o1. Um von einem Element zu einem anderen zu referenzieren, wird ein Attribut zusammen mit einer eindeutigen ID angegeben, z. B: Hersteller: &o2. Alle Referenzen, die nicht dem Element selbst untergeordnete Elemente referenzieren, werden in dieser Arbeit als Quer-Referenz bezeichnet.
Weil es somit möglich ist, sich innerhalb des Graphen durch die gerichteten Kanten zyklisch zu bewegen, werden solche Datensammlungen als zyklisch bezeichnet.2 Ein zyklischer Graph ist im Folgenden in der ssd-Notation dargestellt:
{
Fahrzeug: &o1{Modell: „Passat“
km-Stand: „35.600“,
Erstzulassung: „02/2007“ ,
Hersteller: &o2,
Motor: &o3
},
Hersteller: &o2 {Name : „Volkswagen“,
Ort: „Wolfsburg“
Produkte: {Gebrauchtwagen : &o1,
Motor: &o3 }
},
Motor: &o3 {Name: „OttoV2“,
Kraftstoff: „Benzin“
Hubraum : „2.0 Liter“
PS : „120“
}
}
XML
Sehr weit verbreitet ist hingegen die Notation von semistrukturierten Daten mit XML, die vom W3-Konsortium standardisiert worden ist. Diese dient als Datenaustausch-Format im Internet und wird zusätzlich in vielen Applikationen als Datenablageformat verwendet.
In XML lassen sich mit folgender Notation Attribute bei sog. Elementen notieren, deren Name frei festgelegt werden kann:
- <element [attribut_1=„wert_1“] [attribut_2=„wert_2“] [attribut_n=„wert_n“] />
Der ssd-Datensatz
- {Fahrzeug: {Modell: „Passat“ } }
sieht in XML wie folgt aus:
- <Fahrzeug Modell=„Passat“/>
Ein Element kann weitere Inhalte und/oder weitere Unterelemente enthalten:
<element [attribut_1=„wert_1“] [attribut_2=„wert_2“] [attribut_n=„wert_n“]> inhalt1 <unterelement_1/> <unterelement_2/> .... </element>
Somit existieren innerhalb von XML zwei Möglichkeiten, Eigenschaften von Objekten zu spezifizieren:
- durch XML-Attribute
- durch Unterelemente
Der ssd-Datensatz (s. o.) kann auch mit einem weiteren Unterelement beschrieben werden:
<Fahrzeug> <Modell> Passat </Modell> </Fahrzeug>
Document Type Definitions
Für die XML-Dokumente existiert eine weitere Notation, welche die Bezeichnung DTD (Document Type Definition) trägt. Diese Notation beschreibt die Struktur eines XML-Dokuments.
XML-Dateien mit DTD sind „strukturierter“ als XML-Dateien ohne DTD. XML-Dateien ohne DTD haben keine Typisierung.
Innerhalb eines XML-Dokumentes können Elemente bzw. Tags und deren Attribute beliebig definiert werden – ohne Einschränkungen. Es ist prinzipiell möglich, dass die DTD nur einen Teil der Elemente innerhalb des XML-Dokumentes festlegt. Mit Hilfe einer DTD kann definiert werden, welche Elemente es geben darf, und welche Attribute diese Elemente haben dürfen oder müssen; ebenso kann die Menge der möglichen Werte eingeschränkt werden. Zusätzlich kann die Menge möglicher untergeordneter Elemente mit DTDs definiert werden. Die in der DTD beschriebenen Typen können impliziert werden.
Obwohl das XML-Dokument einer Objektbeschreibung unterliegt, kann nicht von strukturierten Daten gesprochen werden.
Trotz der Möglichkeit der weiteren Strukturierung mit DTDs, befinden wir uns immer noch auf der semistrukturierten Ebene der Datenhaltung. Dies ist damit begründet, dass strukturierte Daten aus technischer Sicht einem sogenannten Data-Dictionary unterliegen, der die Struktur der Daten beschreibt.
Zur Struktur der Entities gehören u. a. die Beziehungen, Attribute und Werte mit ihren Datentypen. Ein Zugriff auf die abgelegten Daten ohne Data-Dictionary ist nicht möglich.
Anders ist es bei semistrukturierten Daten, die grundsätzlich wie eine Textdatei aufgebaut sind. Auch sind die Werte der Attribute nicht mit Datenstrukturvorgaben wie String, Integer, Float, Date, Number etc. definiert, sondern werden grundsätzlich als Zeichenketten (Strings) dargestellt.
Somit kann eine XML-Datei, die mit einer DTD validiert wurde, unabhängig von der DTD bearbeitet und verändert werden. Verschiedene XML-Dateien, die wiederum mit ein und derselben DTD validiert werden können, gehören somit einer gleichen Äquivalenzklasse an.
Da die Struktur der DTD von den verarbeitenden Algorithmen abgeleitet wird, können semistrukturierte Daten in XML mit DTD nur von einem Programm in einer Version erzeugt und auch mit einem Programm und einer Version weiterverarbeitet werden – es sei denn, bei der Weiterverarbeitung werden semantisch orientierte Abfragen oder Verarbeitungsmethoden eingesetzt.
Möglicherweise können DTDs auch durch Typenerkennungsverfahren, wie Simulation (Abiteboul) erzeugt werden, da mit diesem Verfahren Typen von Objekten „Klassen“ erkannt werden. Programmänderungen – wie hier im Analysesystem – führen auch zur Anpassung der DTD.
Zusätzlich bietet die semistrukturierte Konzeption die Möglichkeit, dass Elemente, die in diesem Fall Wörter und Satzphrasen beschreiben, beliebig aufeinanderfolgen können. Die DTD-Notation bietet Parameter Entities an, die eine beliebige Reihenfolge und Anzahl von Unterelementen eines übergeordneten Elementes ermöglichen. Dies ist bei der strukturierten ER-Modellierung nicht auf direktem Wege möglich.
Literatur
- Serge Abiteboul, Peter Buneman, Dan Suciu: Data on the Web. From Relations to Semistructured Data and XML. Morgan Kaufmann Publishers, San Francisco, California 2000, ISBN 1-55860-622-X.
- Francois Bry, Michael Kraus, Dan Olteanu, Sebastian Schaffert: Aktuelles Schlagwort „Semi-strukturierte Daten“. 2001 (PDF [abgerufen am 26. April 2011]).